Im Folgenden geht es um das Hosting von Git-Repositories und Gitolite, mit dem Sie Zugriffsrechte auf Repositories über SSH-Public-Keys flexibel verwalten. Außerdem werden Installation und Konfiguration der zwei Web-Interfaces Gitweb und CGit erläutert, alternativ für Apache oder Lighttpd.
Zunächst einige Grundlagen: Wie unterscheiden sich Repositories auf einem Server von denen eines normalen Nutzers? Und wie tauscht Git die Änderungen aus?
Git ist auf dezentrale Verwaltung der Repositories ausgelegt; die
kleinste Einheit, um Änderungen zwischen Repositories
auszutauschen, sind Commits. Da sich aber zwischen zwei Versionen
einer Software bisweilen tausende von Commits ansammeln und eine
einzelne, commitweise Übertragung viel Overhead erzeugen würde,
werden Commits vor der Übertragung zu sogenannten Packfiles
zusammengefasst. Diese Packfiles sind ein simples, aber effektives
Format.[92] Sie
werden auch verwendet, um (ältere) Commits auf der Festplatte
platzsparend zu lagern (git gc bzw. git repack,
siehe Abschnitt B.1, „Aufräumen“).
Diese Packfiles werden in der Regel über das Git-Protokoll übertragen, das standardmäßig auf Port 9418/TCP läuft. Das Git-Protokoll ist vom Design her bewusst sehr einfach gehalten und bietet nur wenige Funktionen, die unmittelbar mit der Struktur von Git zu tun haben: Welche Daten gesendet oder empfangen werden sollen sowie eine Möglichkeit für Sender- und Empfängerseite, sich auf die kleinstmögliche Datenmenge zu einigen, die übertragen werden muss, um beide Seiten zu synchronisieren.
Das Git-Protokoll enthält daher keine Möglichkeit der Authentifizierung. Stattdessen verwendet Git eine bereits vorhandene, sichere und einfache Authentifizierungsstruktur: SSH, die Secure Shell.
Während das Git-Protokoll also unverschlüsselt und in Rohform für anonymen Lesezugriff uneingeschränkt verwendet werden kann, funktioniert ein Schreiben bzw. Hochladen über das Git-Protokoll nur, wenn dies über SSH erfolgt.
Des Weiteren unterstützt Git auch den Transport über HTTP(S), FTP(S), sowie Rsync. Zwar gilt die Unterstützung für letzteres mittlerweile als deprecated, es sollte also nicht mehr benutzt werden; für HTTP(S) finden sich aber gewisse Anwendungsfälle: In besonders restriktiven Umgebungen mit sehr einschränkenden Firewall-Regeln kann man eventuell über HTTP(S) (also nur auf Port 80 bzw. 443) auf ein Repository lesend wie schreibend zugreifen. Plattformen wie GitHub (siehe Kapitel 11, Github) bieten HTTPS daher als Standard-Transportmethode an.
Wollen Sie Änderungen an Repositories auf dem gleichen Rechner synchronisieren, muss dies nicht über Umwege erfolgen: Git kommuniziert direkt über Unix-Pipes mit der Gegenseite, handelt eine gemeinsame Basis aus und synchronisiert die Daten. (Dafür ist es natürlich nötig, dass der Nutzer, der das Git-Kommando aufruft, zumindest Leseberechtigung auf die Packfiles des anderen Repositorys hat.)
Bisher haben Sie vermutlich größtenteils mit Git-Repositories
gearbeitet, die Working Tree und Repository in einem waren: Die
repositoryinternen Daten werden in einem Unterverzeichnis
.git gespeichert, alle anderen Dateien gehören dem Working
Tree an, d.h. Sie können sie editieren, während Git die Veränderung
an diesen Dateien beobachtet und abspeichert (Tracking).
Ein sogenanntes Bare Repository, also ein „bloßes“
Repository, hat keinen zugeordneten Working Tree. Es enthält nur die
Dateien und Verzeichnisse, die in einem „regulären“
Repository unterhalb von .git gespeichert sind.
Ein solches Bare Repository erstellen Sie durch git init
--bare. Schauen Sie sich den Unterschied zwischen den beiden
Möglichkeiten an:
$ cd /tmp/ && mkdir init-test && cd init-test $ git init Initialized empty Git repository in /tmp/init-test/.git/ $ ls -AF .git/ $ mkdir ../init-test-bare && cd ../init-test-bare $ git init --bare Initialized empty Git repository in /tmp/init-test-bare/ $ ls -AF branches/ config description HEAD hooks/ info/ objects/ refs/
Um ein Backup eines Ihrer normalen Repositories anzulegen, können Sie (z.B. auf einem USB-Stick) ein neues Bare Repository erstellen und alle Ihre Referenzen (und damit alle Ihre Commits) hochladen:
$ git init --bare /mnt/usb/repo-backup/ $ git push --all /mnt/usb/repo-backup/
Bei git init werden die Dateien in der Regel mit Lese-
und Schreibberechtigung entsprechend der gesetzten umask
angelegt. Für den Endanwender ist dies auch eine günstige Wahl.
Wollen Sie aber ein Repository auf einem Server einrichten, dann
können Sie mit der Option --shared angeben, wer (auf
Dateisystemebene) auf das Repository zugreifen kann.
-
umask -
Default, wenn
--sharednicht angegeben ist; verwendet die aktuell gesetzteumask. -
group -
Default, wenn nur
--sharedangegeben wird. Vergibt Schreibrechte an alle Gruppenmitglieder. Speziell werden auch Verzeichnisse auf den Modusg+sxgesetzt, erlauben es also allen Gruppenmitgliedern, neue Dateien zu erstellen (also Commits hochzuladen). Beachten Sie, dass, wenn dieumaskLeseberechtigung für alle Nutzer (a+r) vorgibt, diese weiterhin vergeben wird. -
all -
Das gleiche wie
group, nur dass unabhängig von derumaskLeseberechtigung für alle explizit vergeben wird. -
0<nnn> -
Setzt die
umaskexplizit auf<nnn>.
Wenn Sie ein Repository mit --shared initialisieren, wird
automatisch die Option receive.denyNonFastForwards gesetzt.
Sie verhindert, dass Commits hochgeladen werden, die nicht per
Fast-Forward integriert werden können (selbst, wenn der Nutzer dies
explizit will via git push -f).
In der Regel kann der Schreib-Zugriff auf Git-Repositories, die auf einem anderen Rechner liegen, nur per SSH erfolgen. Allerdings ist es im Allgemeinen nicht wünschenswert, einem Nutzer, der Zugriffsrechte auf ein Repository erhalten soll, auch gleich Nutzerrechte auf dem ganzen System einzuräumen.
Dieses Problem umgeht Git mit dem mitgelieferten Programm
git-shell. Es funktioniert wie eine Shell, erlaubt aber nur
die Ausführung von vier Git-Kommandos, die für das Hoch- und
Runterladen von Packfiles zuständig sind. Interaktive Benutzung oder
Ausführung anderer Kommandos verweigert die Shell, sofern Sie nicht den
„Interaktiven Modus“ der Shell explizit aktivieren – siehe dafür
die Man-Page git-shell(1).
Wenn Sie einen neuen Benutzer anlegen und ihm z.B. per
chsh <user> die Git-Shell zuweisen, kann er sich nicht
per SSH einloggen, aber auf alle Git-Repositories, auf denen er
Schreibberechtigung hat, Commits hochladen.
Es ist ein wesentlicher Vorteil, dass Git SSH als verschlüsselten und authentifizierten Transportkanal verwendet, denn die meisten Nutzer haben bereits ein Schlüsselpaar (öffentlich/privat), mit dem sie sich auf anderen Rechnern einloggen.
Anstatt also umständlich Passwörter für Accounts zu vergeben (und dann zu versenden), kann ein Systemadministrator den Zugriff auf Git-Repositories auf Nutzer limitieren, die sich gegen öffentliche SSH-Schlüssel authentifizieren. Das spart dem Nutzer Zeit (durch die möglicherweise wegfallende wiederholte Eingabe eines Passworts), aber auch dem Administrator, der sich nicht um Passwortänderungen kümmern muss (die durch Einsatz der Git-Shell nicht ohne weiteres möglich wären).
Im Folgenden wollen wir beispielhaft die Kommandos entwickeln, mit
denen Sie zwei Nutzer max und moritz auf Ihrem
System einrichten und sie auf dem gleichen Repository arbeiten
lassen.
Zunächst müssen wir ein Repository einrichten, auf das die beiden
später zugreifen wollen. Unter der Annahme, dass vielleicht später
weitere Repositories folgen sollen, erstellen wir eine Unix-Gruppe
git (generell für Git-Nutzer) und ein Verzeichnis
/var/repositories mit Leseberechtigung für Mitglieder der
Gruppe git, außerdem eine Gruppe git-beispiel und
ein entsprechendes Verzeichnis, schreibbar nur für Mitglieder von
git-beispiel, in dem sich dann später das Repository
befindet:
$ groupadd git $ groupadd git-beispiel $ mkdir -m 0750 /var/repositories $ mkdir -m 0770 /var/repositories/git-beispiel $ chown root:git /var/repositories $ chown root:git-beispiel /var/repositories/git-beispiel
Wir erstellen auch gleich ein Repository in dem zuletzt angelegten Verzeichnis:
$ git init --bare --shared /var/repositories/git-beispiel $ chown -R nobody:git /var/repositories/git-beispiel
Als nächstes erstellen wir die beiden Nutzer. Beachten Sie, dass bei
diesem Aufruf kein Homeverzeichnis für die Nutzer unter
/home/ erstellt wird. Außerdem werden beide der Gruppe
git und git-beispiel hinzugefügt:
$ adduser --no-create-home --shell /usr/bin/git-shell max $ adduser --no-create-home --shell /usr/bin/git-shell moritz $ adduser max git $ adduser max git-beispiel $ adduser moritz git $ adduser moritz git-beispiel
Als nächstes müssen wir den Nutzern per passwd noch jeweils
ein Passwort zuweisen, damit sie sich per SSH einloggen können.
Anschließend können die neuen Nutzer nun gemeinsam an einem Projekt
entwickeln. Das Remote fügen Sie wie folgt hinzu:
$ git remote add origin max@server:/var/repositories/git-example
Alle weiteren Nutzer, die an diesem Projekt mitarbeiten wollen, müssen
der Gruppe git-beispiel angehören. Dieser Ansatz basiert also
wesentlich auf der Nutzung von Unix-Gruppen und Unix-Nutzern.
Allerdings will ein Server-Admin in der Regel nicht nur Git anbieten,
sondern diverse Services. Und die Nutzerverwaltung vollständig über
Unix-Gruppen zu regeln, ist eher unflexibel.
Die oben beschriebene Art und Weise, Nutzer zu verwalten, bringt einige wesentliche Nachteile. Namentlich:
- Für jeden Nutzer muss ein vollwertiger Unix-Account angelegt werden. Das bedeutet einen großen Mehraufwand für den Administrator und öffnet möglicherweise auch Sicherheitslücken.
- Für jedes Projekt muss eine eigene Unix-Gruppe erstellt werden.
- Für jeden angelegten Nutzer müssen manuell (oder per Script) die Zugriffsberechtigungen angepasst werden.
Abhilfe schafft das Programm Gitolite.[93]
Gitolite ist aus dem Projekt Gitosis hervorgegangen, das
mittlerweile als veraltet angesehen wird. Die Idee: Auf dem Server
wird lediglich ein Unix-Benutzer (z.B. git)
angelegt. Intern verwaltet dann Gitolite eine Liste von Nutzern mit
zugehörigen SSH-Schlüsseln. Diese Nutzer haben aber keinen
„wirklichen“ Nutzer-Account auf dem System.
Nutzer loggen sich ausschließlich mit ihrem öffentlichen
SSH-Schüssel auf diesem Account git ein. Das bringt drei
wesentliche Vorteile:
- Kein Passwort muss vergeben oder geändert werden.
- Nutzer können mehrere SSH-Schlüssel hinterlegen (für verschiedene Rechner, auf denen sie arbeiten).
- Anhand des SSH-Schlüssels, mit dem sich ein Nutzer einloggt, kann Gitolite eindeutig[94] den internen Nutzernamen ableiten und somit auch die Berechtigungen auf den von Gitolite verwalteten Repositories.
Die Installation von Gitolite ist einfach. Sie müssen dafür nur Ihren
Public-Key bereithalten, um sich als Administrator eintragen zu können.
Root-Rechte benötigen Sie nicht, es
sei denn, Sie müssen den Nutzer git erst erstellen.[95]
Überspringen Sie also den nachfolgenden Schritt, wenn Sie bereits
einen solchen Nutzer erstellt haben.
Zunächst erstellen Sie einen Nutzer auf dem Rechner, der als
Git-Server arbeiten soll (im Folgenden <server>). In der
Regel wird dieser Nutzer git genannt, Sie können ihn aber auch
anders nennen (z.B. gitolite). Als Homeverzeichnis können
Sie /home/git angeben oder auch, wie hier im Beispiel, etwas
wie /var/git:
server# adduser --home /var/git git
Werden Sie nun zum Nutzer git. Gitolite braucht die Verzeichnisse
.ssh/ und bin/, also müssen wir diese erstellen:
server$ mkdir -m 0700 ~/.ssh ~/bin
Klonen Sie nun das Gitolite-Repository, und installieren Sie einen
Symlink nach bin (dies ist schon die ganze Installation):
server$ git clone git://github.com/sitaramc/gitolite server$ gitolite/install -ln
Sie können nun Gitolite konfigurieren und Ihren öffentlichen Schlüssel eintragen, mit dem Sie die Gitolite-Konfiguration verwalten wollen:
server$ bin/gitolite setup -pk <ihr-key>.pub
Überprüfen Sie auf dem Rechner, auf dem Sie normalerweise arbeiten (und wo Sie den entsprechenden privaten Schlüssel hinterlegt haben), ob Gitolite funktioniert:
client$ ssh -T git@<server>
...
R W gitolite-admin
Sie sollten erkennen, dass Sie mit Ihrem Key Lese- und
Schreibberechtigung auf dem Repository gitolite-admin besitzen. Dieses
klonen Sie nun auf Ihren Computer:
client$ git clone git@<server>:gitolite-admin
Das Repository enthält die gesamte Konfiguration für Gitolite. Sie
checken Ihre Änderungen dort ein und laden Sie per git push hoch: Der
Server aktualisiert automatisch die Einstellungen.
Im Gitolite-Admin-Verzeichnis befinden sich zwei Unterverzeichnisse,
conf und keydir. Um Gitolite einen neuen Nutzer
vorzustellen, müssen Sie dessen SSH-Schlüssel unter
keydir/<nutzer>.pub ablegen. Hat der Nutzer mehrere
Schlüssel, können Sie diese in einzelnen Dateien vom
Format <nutzer>@<beschreibung>.pub ablegen:
client$ cat > keydir/feh@laptop1.pub ssh-dss AAAAB3NzaC1kc3M ... dTw== feh@mali ^D client$ cat > keydir/feh@laptop2.pub ssh-dss AAAAB3NzaC1kc3M ... 5LA== feh@deepthought ^D
Vergessen Sie nicht, mit git add keydir und einem
anschließenden git commit die neuen Schlüssel einzuchecken.
Um diese der Gitolite-Installation bekannt zu machen, müssen Sie
außerdem die Commits durch git push hochladen.
Danach können Sie diesem Nutzernamen in der Konfigurationsdatei
conf/gitolite.conf Berechtigungen zuweisen.
Über sogenannte Makros können Sie sich viel administrativen Aufwand bzw. Tipparbeit sparen. Sie können Gruppen (von Nutzern oder Repositories) zusammenfassen, z.B.
@test_entwickler = max markus felix @test_repos = test1 test2 test3
Diese Makros werden auch rekursiv ausgewertet. Bei der Definition muss nicht klar sein, ob es sich um Nutzer oder Repositories handelt; die Makros werden erst zur Laufzeit ausgewertet. So können Sie Gruppen aus anderen Gruppen zusammensetzen:
@proj = @developer @tester @admins
Es gibt eine spezielle Gruppe @all, die, je nach Kontext,
alle Nutzer oder alle Repositories enthält.
Ein (oder mehrere) Repositories können Sie wie folgt konfigurieren:
repo @test_repos
RW+ = @test_entwickler
R und W stehen für Lese- bzw. Schreibzugriff. Das
Plus bedeutet, dass auch ein forciertes Hochladen erlaubt ist
(non-fast-forward, also auch das Löschen von Commits).
Für ein Repository können natürlich mehrere solcher Zeilen eingetragen werden. In einem kleinen Projekt könnte es Maintainer, weitere Entwickler und Tester geben. Dann könnten die Zugriffsrechte wie folgt geregelt werden:
@maintainers = ... # Hauptentwickler/Chefs
@developers = ... # Weitere Entwickler
@testers = ...
repo Projekt
RW+ = @maintainers
RW = @developers
R = @testers
So haben die Tester nur Lesezugriff, während die Entwickler zwar neue Commits hochladen dürfen, aber nur, wenn diese per fast-forward integriert werden können. Die Hauptmaintainer dürfen „alles“.
Diese Zeilen werden sequentiell abgearbeitet. Trifft die Zeile für einen Nutzer zu, so autorisiert Gitolite den Nutzer und stattet ihn mit den entsprechenden Rechten aus. Sofern keine Zeile auf den Nutzer zutrifft, wird er zurückgewiesen und darf an dem Repository nichts verändern.
Ein Nutzer kann alle seine Berechtigungen anzeigen lassen, indem er sich einfach per SSH auf dem Git-Server einloggt. Direkt nach der Installation sieht dies für den Administrator dann so aus:
$ ssh -q git@<server>
hello feh, this is git@mjanja running gitolite3 v3.6.1-6-gdc8b590 on git 2.1.0
R W gitolite-admin
R W testing
Sofern Sie später ein webbasiertes Tool installieren wollen, mit dem man die Git-Repositories durchstöbern kann, sollten Sie auch gleich einen Verantwortlichen benennen und das Projekt beschreiben:
repo <repo-name> # Zugriffsrechte config gitweb.owner = "Julius Plenz" config gitweb.description = "Ein Test-Repository"
Damit dies funktioniert, müssen Sie allerdings erst aktivieren, dass
Gitolite diese Config-Einstellungen setzen darf: Das
geschieht auf dem Server, wo Gitolite installiert ist, in der Datei
.gitolite.rc: Tragen Sie dort unter dem Schlüssel
GIT_CONFIG_KEYS den Wert gitweb\..* ein.
Gerade in Firmenumgebungen müssen die Zugriffsrechte häufig noch feiner differenziert werden als ein bloßes „hat Zugriff“ und „darf nicht zugreifen“. Dafür bietet Gitolite Zugriffsbeschränkung auf Verzeichnis- und Datei- sowie Tag- und Branch-Ebene an.
Wir betrachten zunächst einen Fall, der häufig auftritt: Entwickler
sollen auf Entwicklungs-Branches beliebig entwickeln können, aber nur
eine kleine Gruppe von Maintainern soll „wichtige“ Branches
wie z.B. master, bearbeiten können.
Das ließe sich in etwa so umsetzen:
@maintainers = ...
@developers = ...
repo Projekt
RW+ dev/ = @developers
RW+ = @maintainers
R = @developers
Hier wird ein „Entwicklungs-Namespace“ geschaffen: Die
Gruppe der Entwickler kann beliebig mit Branches unterhalb von
dev/ verfahren, also z.B. dev/feature erstellen
oder auch wieder löschen. Den Branch master können die
Entwickler allerdings nur lesen, nicht aber verändern – das ist den
Maintainern vorbehalten.
Der Teil zwischen den Flags (RW+) und dem
Gleichzeichen ist ein sogenannter Perl-kompatibler regulärer Ausdruck
(Perl-Compatible Regular Expression, kurz PCRE). Sofern er
nicht mit refs/ beginnt, bezieht sich der Ausdruck auf
alle Referenzen unterhalb von refs/heads/, also Branches. Im
o.g. Beispiel können also beliebige Referenzen unterhalb von
refs/heads/dev/ modifiziert werden – nicht aber der Branch
dev selbst oder irgendwas-dev!
Beginnt ein solcher Ausdruck aber explizit mit einem refs/,
kann man beliebige Referenzen verwalten. Auf die folgende Weise
richtet man ein, dass alle Maintainer Release-Candidate-Tags[96]
erstellen dürfen, aber nur ein Maintainer wirklich den
Versionierungs-Tag (bzw. beliebige andere) erstellen darf:
repo Projekt
RW+ refs/tags/v.*-rc[0-9]+$ = @maintainers
RW+ refs/tags/ = <projektleiter>
Will einer der Maintainer trotzdem einen Tag wie z.B. v1.0
hochladen, passiert Folgendes:
remote: W refs/tags/v1.0 <repository> <user> DENIED by fallthru remote: error: hook declined to update refs/tags/v1.0 To <user>:<repository> ! [remote rejected] v1.0 -> v1.0 (hook declined)
Wie oben schon angesprochen, werden hier die Regeln nacheinander
angewendet. Da der Tag v1.0 nicht auf den o.g. regulären
Ausdruck zutrifft, kommt nur die untere Zeile in Frage, allerdings
passt der Nutzername nicht. Keine Zeile bleibt übrig
(fallthru), daher wird die Aktion nicht erlaubt.
Etwas flexibler ist das Konzept persönlicher Namespaces. So erhält jeder Entwickler seine eigene Hierarchie von Branches, die er verwalten kann.
Dafür gibt es ein spezielles Schlüsselwort, USER, das jeweils
durch den gerade zugreifenden Nutzernamen ersetzt wird. Damit wird
Folgendes möglich:
repo Projekt
RW+ p/USER/ = @developers
R = @developers @maintainers
Nun können alle Developer unterhalb von p/<user>/ beliebig
ihre Branches verwalten. Die untere Direktive sorgt dafür, dass alle
diese Branches auch lesen können. Nun kann max z.B. p/max/bugfixes erstellen, aber moritz kann nur
lesend darauf zugreifen.
Gitolite erlaubt auch Zugriffsbeschränkungen auf Datei- und
Verzeichnisebene. Zuständig dafür ist die virtuelle Referenz VREF/NAME.
So können Sie beispielsweise dem Dokumentations-Team nur den
(schreibenden[97])
Zugriff auf doc/ erlauben:
@doc = ... # Dokumentations-Team
repo Projekt
RW VREF/NAME/doc/ = @doc
- VREF/NAME/ = @doc
Hierbei sind allerdings folgende Fallstricke zu beachten: Sobald das
Schlüsselwort VREF/NAME einmal auftaucht, werden die
dateibasierten Regeln für alle Nutzer angewendet. Trifft keine von
ihnen zu, so wird der Zugriff zugelassen – daher ist die zweite Regel
wichtig, die den Zugriff für @doc verbietet, es sei denn, der Commit
modifiziert nur Dateien unter doc/ (siehe auch weiter unten
Abschnitt 7.2.7, „Aktionen explizit verbieten“).
Die Zugriffskontrolle prüft auf Commit-Ebene, welche Dateien verändert
werden; stecken in einem Commit Änderungen an einer Datei, die der
Nutzer nicht editieren darf, wird der gesamte push-Vorgang
abgebrochen. Insbesondere können keine Aktionen ausgeführt werden, die
Commits anderer Entwickler involvieren, die Dateien außerhalb des
erlaubten Bereiches modifizieren.
Konkret auf das o.g. Beispiel bezogen heißt das, dass die Mitglieder
von @doc im Allgemeinen keine neuen Branches erstellen
können. Einen neuen Branch zu erstellen hieße nämlich, ein neue
Referenz auf einen initialen Commit zu erstellen und dann alle
Commits vom obersten bis zur Wurzel per fast-forward zu
integrieren, also die gesamte Projekt-Historie. Darin befinden sich
aber sicherlich Commits, die Dateien außerhalb von doc/
verändern, und somit wird die Aktion verboten.
Bisher wurde ein Nutzer nur abgewiesen, wenn er durch alle Regeln
durchgefallen war (fallthru), ihm also keine Rechte zugewiesen
wurden. Allerdings lässt sich durch das Flag - (statt
RW) explizit der Zugriff einschränken. Auch hier werden die
Regeln wieder von oben nach unten durchgegangen.
repo Projekt
- VREF/NAME/Makefile = @developers
Diese Direktive verbietet Mitgliedern von @developers,
Commits zu erstellen, die das Makefile
verändern.[98]
Nach Konvention sollten Sie niemals forcierte Updates in die Branches
master oder maint hochladen (siehe auch Abschnitt 3.1, „Referenzen: Branches und Tags“). Diese Policy können
Sie nun mit Gitolite forcieren:
repo Projekt
RW master maint = @developers
- master maint = @developers
RW+ = @developers
Wird ein Branch, der nicht master oder maint
heißt, hochgeladen, so wird lediglich die dritte Regel angewendet und
der beliebige Zugriff (inkl. nicht-fast-forward-Updates)
erlaubt. Commits, die per fast-forward auf master oder
maint integriert werden können, werden durch die erste Regel
erlaubt. Beachten Sie allerdings das fehlende Plus-Zeichen: Ein
forciertes Update wird nicht durch die erste Regel abgedeckt, aber
durch die zweite, die explizit alles verbietet (was nicht vorher schon
erlaubt wurde).
Mit den hier vorgestellten Mitteln und weiteren, die Sie der Dokumentation[99] entnehmen können, sind Sie in der Lage, Policies sehr flexibel zu forcieren. Allerdings ist es möglicherweise nicht sinnvoll, alles bis ins kleinste Detail zu kontrollieren. Wie oben bereits angesprochen, ist besonders eine Kontrolle auf Dateinamen-Ebene problematisch. Wenn dann stundenlange Arbeit in einem Commit steckt, er aber nicht hochgeladen werden kann, weil eine dieser Restriktionen es verbietet, ist die Frustration groß (und diesen Commit zu korrigieren, ist auch nicht ganz trivial, siehe Rebase, Abschnitt 4.1, „Commits verschieben – Rebase“).
Auf Branch-Ebene ist es sinnvoll, nur einer eingeschränkten Gruppe von
Entwicklern Zugriff auf „wichtige“ Branches zu geben (wie
z.B. master). Allerdings geht natürlich eine strikte
Kontrolle, wer was machen darf, erheblich zu Lasten der Flexibilität,
und gerade diese Flexibilität macht das Branching in Git so praktisch.
Der Git-Daemon erlaubt unverschlüsselten, anonymen, lesenden Zugriff auf Git-Repositories über das Git-Protokoll. Er wird mit Git mitgeliefert und läuft in der Regel auf TCP-Port 9418 (und kann somit auch ohne Root-Rechte gestartet werden).
- Die Übertragung findet unverschlüsselt statt. Die kryptografische Integrität, die Git ständig überprüft, schließt es allerdings aus, dass Angreifer den Datenstrom manipulieren und Schadcode einschmuggeln können.[100]
- Dieser Weg ist ideal, um schnell und einfach Quellcode einer großen Menge von Leuten zugänglich zu machen. Es wird nur das Minimum an nötigen Informationen heruntergeladen (es werden nur die benötigten Commits ausgehandelt und dann gepackt übertragen).
Um ein oder mehrere Repositories zu exportieren, reicht prinzipiell
ein einfacher Aufruf von git daemon <pfad>, wobei
<pfad> der Pfad ist, in dem Ihre Repositories liegen. Es
können auch mehrere Pfade angegeben werden. Sofern Sie Gitolite schon
wie oben aufgesetzt haben, ist /var/git/repositories ein
sinnvoller Pfad.
Zum Testen können Sie einen Git-Daemon auf einem einzigen Repository laufen lassen:
$ touch .git/git-daemon-export-ok $ git daemon --verbose /home/feh/testrepo
Dann klonen Sie (am besten in ein temporäres Verzeichnis) eben dieses Repository:
$ git clone git://localhost/home/feh/testrepo
Initialized empty Git repository in /tmp/tmp.kXtkwxKgkc/testrepo/.git/
remote: Counting objects: 130, done.
remote: Compressing objects: 100% (102/102), done.
Receiving objects: 100% (130/130), 239.71 KiB, done.
Resolving deltas: 100% (54/54), done.
remote: Total 130 (delta 54), reused 0 (delta 0)
Der Git-Daemon exportiert ein Repository aber nur, wenn eine Datei
git-daemon-export-ok im .git-Verzeichnis angelegt
wird (wie oben geschehen; im Falle von Bare Repositories muss
dies natürlich im Verzeichnis selbst geschehen). Dies erfolgt aus
Sicherheitsgründen: So können etwa unter
/var/git/repositories viele (auch private) Repositories
liegen, aber nur diejenigen, die wirklich ohne Zugriffskontrolle
exportiert werden sollen, erhalten diese Datei.
Der Daemon akzeptiert allerdings die Option --export-all,
die diese Restriktion aufhebt und alle Repositories in allen
Unterverzeichnissen exportiert.
Eine weitere wichtige Einstellung ist der Base Path, also der Pfad, in dem die eigentlichen Git-Repositories liegen. Startet man den Git-Daemon wie folgt:
$ git daemon --base-path=/var/git/repositories /var/git/repositories
wird jeder Anfrage nach einem Git-Repository der Base Path
vorangestellt. Nun können Nutzer ein Repository mit der Adresse
git://<server>/<projekt>.git klonen, anstatt
das umständliche
git://<server>/var/git/repositories/<projekt>.git zu
verwenden.
Im Regelfall soll der Git-Daemon eine große Anzahl von Repositories
ständig ausliefern. Dafür läuft er ständig im Hintergrund oder wird
für jede Anfrage neu gestartet. Letztere Aufgabe übernimmt
typischerweise der aus OpenBSD stammende Inetd. Damit das
funktioniert, muss lediglich folgende (eine!) Zeile in die
/etc/inetd.conf eingetragen werden:
git stream tcp nowait <user> /usr/bin/git git daemon --inetd --base-path=/var/git/repositories /var/git/repositories
Dabei muss <user> ein Nutzer sein, der auf die Repositories
lesend zugreifen kann. Das kann root sein, weil der Inetd
normalerweise mit Root-Rechten läuft, sollte aber sinnvollerweise
git oder ein ähnlich unprivilegierter Account sein.
Die Konfiguration für den xinetd ist analog, aber selbsterklärender. Sie wird z.B. unter
/etc/xinet.d/git-daemon abgelegt:
service git
{
disable = no
type = UNLISTED
port = 9418
socket_type = stream
wait = no
user = <user>
server = /usr/bin/git
server_args = daemon --inetd --base-path=... ...
log_on_failure += USERID
}
Vergessen Sie nicht, den jeweiligen Daemon per
/etc/init.d/[x]inetd restart neu zu
starten.[101]
Debian bietet ein Paket git-daemon-run an, das
Konfigurationsdateien für sv[102]
enthält. Das Paket erstellt im wesentlichen einen Nutzer
gitlog sowie zwei ausführbare Shell-Scripte, /etc/sv/git-daemon/run und /etc/sv/git-daemon/log/run. Modifizieren Sie ersteres, damit
der Git-Daemon auf dem Verzeichnis gestartet wird, in dem Ihre
Repositories liegen:
#!/bin/sh exec 2>&1 echo 'git-daemon starting.' exec git-daemon --verbose --listen=203.0.113.1 --user=git --group=git \ --reuseaddr --base-path=/var/git/repositories /var/git/repositories
Wenn Sie den Git-Daemon auf diese Weise (oder auf ähnliche Weise per SysV-Init) aus einem Shell-Script starten, wird das Skript mit Root-Rechten ausgeführt. Folgende Optionen sind daher sinnvoll:
-
--user=<user> -
Nutzer, als der der Daemon läuft (z.B.
git). Muss lesend auf die Repositories zugreifen können. -
--group=<group> -
Gruppe, als die der Daemon läuft. Sinnvollerweise
die Nutzergruppe (
git) odernobody. -
--reuseaddr - Verhindert, dass der Neustart des Daemons schief läuft, weil noch offene Verbindungen auf ein Timeout warten. Diese Option benutzt die Bind-Adresse trotz eventuell noch bestehender Verbindungen. Diese Option sollten Sie immer dann angeben, wenn eine Instanz kontinuierlich läuft.
Wenn Sie das SysV-Init verwenden, Dienste also in der Regel über
Symlinks in /etc/rc2.d/ zu Scripten in /etc/init.d/
gestartet werden, müssen Sie für einen automatischen Start des
Git-Daemon beim Booten des Systems außerdem folgende Symlinks anlegen:
# ln -s /usr/bin/sv /etc/init.d/git-daemon # ln -s ../init.d/git-daemon /etc/rc2.d/S92git-daemon # ln -s ../init.d/git-daemon /etc/rc0.d/K10git-daemon # ln -s ../init.d/git-daemon /etc/rc6.d/K10git-daemon
Auf einem Produktivsystem, das mehr als nur ein Git-Server ist, trifft man möglicherweise auf folgende Situationen:
- Es gibt mehrere Netzwerkkarten bzw. virtuelle Interfaces.
- Der Service soll auf einem anderen Port laufen.
- Verschiedene IPs sollen verschiedene Repositories ausliefern.
Der Git-Daemon bietet Optionen, um auf solche Situationen zu
reagieren. Sie sind nachfolgend zusammengefasst. Für
detailliertere Erklärungen ist die Man-Page git-daemon zu
konsultieren.
-
--max-connections=<n> - Per Default erlaubt der Git-Daemon nur 32 gleichzeitige Verbindungen. Mit dieser Optionen können Sie die Anzahl erhöhen. Ein Wert von 0 lässt beliebig viele Verbindungen zu.[103]
-
--syslog - Verwendet den Syslog-Mechanismus statt Standard-Error, um Fehlermeldungen zu loggen.
-
--port=<n> - Verwendet einen anderen Port als 9418.
-
--listen=<host/ip> -
Bestimmt, an welches Interface sich der
Git-Daemon binden soll. Per Default ist der Daemon auf allen
Interfaces erreichbar, bindet also auf
0.0.0.0. Ein Einstellung von127.0.0.1z.B. erlaubt nur Verbindungen vom lokalen Rechner. -
--interpolated-path=<template> -
Soll ein Git-Daemon abhängig von
der Interface-Adresse verschiedene Repositories anbieten, so wird dies
über das
<template>geregelt:%IPwird durch die IP-Adresse des Interfaces, über das die Verbindung eingeht, ersetzt, und%Ddurch den angegebenen Pfad. Mit einem Template von/repos/%IP%Derscheint bei einemgit clone git://localhost/testrepodie folgende Nachricht in den Logfiles:Interpolated dir '/repos/127.0.0.1/testrepo'(weil die Verbindung über das Loopback-Interface zustande kommt). Für jedes Interface, auf dem der Git-Daemon läuft, muss in diesem Fall in/repos/ein Unterverzeichnis mit der entsprechenden IP-Adresse des Interfaces existieren, in dem sich exportierbare Repositories befinden.
Gitolite kennt einen speziellen Nutzernamen, daemon. Für alle
Repositories, auf denen dieser Nutzer Leseberechtigung hat, wird
automatisch die Datei git-daemon-export-ok angelegt. Sie
können also über Gitolite direkt festlegen, welche Repositories
exportiert werden sollen:
repo Projekt
R = daemon
Beachten Sie allerdings, dass diese Einstellung wirkungslos ist, wenn
Sie den Git-Daemon mit der Option --export-all starten.
Auch können Sie nicht per repo @all allen Repositories diese
Berechtigung vergeben.
Git kommt mit einem integrierten, browserbasierten Frontend, genannt Gitweb. Über das Frontend lässt sich die gesamte Versionsgeschichte eines Projekts durchsuchen: Jeder Commit kann mit allen Details angezeigt werden, Unterschiede zwischen Commits, Dateien oder Branches ebenso wie alle Log-Nachrichten. Außerdem kann jeder Snapshot individuell als Tar-Archiv heruntergeladen werden (das ist besonders für Git-Neulinge praktisch).
Um einen Überblick über die Funktionalität zu erhalten, können Sie mit
dem Kommando git instaweb ohne weitere Konfiguration einen
temporären Webserver mit Gitweb aufsetzen.
Git bringt keinen eigenen Webserver mit. Über die Option
--httpd=<webserver> können Sie festlegen, welchen Webserver
Git verwenden soll, um die Seite auszuliefern. Um Gitweb lediglich
auszuprobieren, empfiehlt es sich, den Webserver webrick zu
verwenden – das ist ein kleiner Webserver, der automatisch mit der
Scriptsprache Ruby ausgeliefert wird.
Sobald Sie das nachfolgende Kommando ausführen, wird der Webserver
gestartet und die Seite im Browser aufgerufen (welcher Browser
verwendet wird, können Sie über die Option --browser
festlegen).
$ git instaweb --httpd=webrick
Beachten Sie, dass das Kommando auf der obersten Ebene eines Git-Verzeichnisses gestartet werden muss. Stoppen Sie den Webserver, wenn nötig, mit folgendem Befehl:
$ git instaweb --stop
Viele Distributionen bringen Gitweb bereits als eigenes Paket oder
direkt im Git-Paket mit. Unter Debian heißt das korrespondierende
Paket gitweb. Wenn Sie nicht sicher sind, ob Gitweb auf Ihrem
System verfügbar ist, sollten Sie das unter /usr/share/gitweb prüfen und ggf. nachinstallieren.
Gitweb benötigt lediglich ein großes Perl-Script plus
Konfigurationsdatei sowie optional ein Logo, CSS-Stylesheet und
Favicon. Die Konfigurationsdatei liegt üblicherweise unter /etc/gitweb.conf, kann aber auch beliebig anders benannt
werden. Wichtig ist, dass bei jedem Aufruf des Perl-Scripts über die
Umgebungsvariable GITWEB_CONFIG übergeben wird, wo sich
diese Datei befindet.
In der Regel sollten Sie schon eine solche Datei haben. In nachfolgender Liste sind die wichtigsten Konfigurationsmöglichkeiten dargestellt.
Achtung: Die Datei muss in validem Perl geschrieben sein. Vergessen Sie also insbesondere nicht das abschließende Semikolon bei der Variablenzuweisung!
-
$projectroot - Verzeichnis, in dem Ihre Git-Repositories liegen.
-
$export_ok -
Dateiname, der bestimmt, ob ein Repository in Gitweb
sichtbar sein soll. Sie sollten diese Variable auf
"git-daemon-export-ok"setzen, damit nur diejenigen Repositories angezeigt werden, die auch durch den Git-Daemon ausgeliefert werden. -
@git_base_url_list -
Array von URLs, über die das Projekt geklont
werden kann. Diese URLs erscheinen in der Projektübersicht und sind
sehr hilfreich, um Leuten schnellen Zugriff auf den Quellcode zu
geben, nachdem sie sich einen kurzen Überblick verschafft haben. Geben
Sie am besten die URL an, unter der Ihr Git-Daemon erreichbar ist,
also z.B.
('git://git.example.com'). -
$projects_list - Zuordnung von Projekten und ihren Besitzern. Diese Projektliste kann automatisch von Gitolite erzeugt werden; siehe die Beispiel-Konfigurationsdatei weiter unten.
-
$home_text - Absoluter Pfad zu einer Datei, die z.B. einen firmen- oder projektspezifischen Textbaustein enthält. Dieser wird oberhalb der Auflistung der Repositories eingeblendet.
Sofern Sie Gitolite wie oben installiert haben und Ihre Repositories
unter /var/git/repositories liegen, sollte folgende
Konfiguration für Gitweb ausreichen:
$projects_list = "/var/git/projects.list";
$projectroot = "/var/git/repositories";
$export_ok = "git-daemon-export-ok";
@git_base_url_list = ('git://example.com');
Ausgehend davon, dass Sie das CGI-Script unter /usr/lib/cgi-bin und die Bild- und CSS-Dateien unter /usr/share/gitweb installiert haben (wie es z.B. auch das
Debian-Paket gitweb macht), konfigurieren Sie Apache wie
folgt:
Erstellen Sie /etc/apache2/sites-available/git.example.com
mit folgendem Inhalt:
<VirtualHost *:80> ServerName git.example.com ServerAdmin admins@example.com SetEnv GITWEB_CONFIG /etc/gitweb.conf Alias /gitweb.css /usr/share/gitweb/gitweb.css Alias /git-logo.png /usr/share/gitweb/git-logo.png Alias /git-favicon.png /usr/share/gitweb/git-favicon.png Alias / /usr/lib/cgi-bin/gitweb.cgi Options +ExecCGI </VirtualHost>
Dann müssen Sie den virtuellen Host aktivieren und Apache die Konfiguration neu laden lassen:
# a2ensite git.example.com # /etc/init.d/apache2 reload
Je nachdem, wie Sie virtuelle Hosts in Lighttpd realisieren, sieht die
Konfiguration möglicherweise anders aus. Wichtig sind drei Dinge: Dass
Sie Aliase für die global installierten Gitweb-Dateien machen, die
Umgebungsvariable GITWEB_CONFIG setzen und dass CGI-Scripte
ausgeführt werden. Dafür müssen Sie die Module mod_alias,
mod_setenv und mod_cgi laden (sofern noch nicht
geschehen).
Die Konfiguration sieht dann wie folgt aus:[104]
$HTTP["host"] =~ "^git\.example\.com(:\d+)?$" {
setenv.add-environment = ( "GITWEB_CONFIG" => "/etc/gitweb.conf" )
alias.url = (
"/gitweb.css" => "/usr/share/gitweb/gitweb.css",
"/git-logo.png" => "/usr/share/gitweb/git-logo.png",
"/git-favicon.png" => "/usr/share/gitweb/git-favicon.png",
"/" => "/usr/lib/cgi-bin/gitweb.cgi",
)
$HTTP["url"] =~ "^/$" {
cgi.assign = ( ".cgi" => "" )
}
}
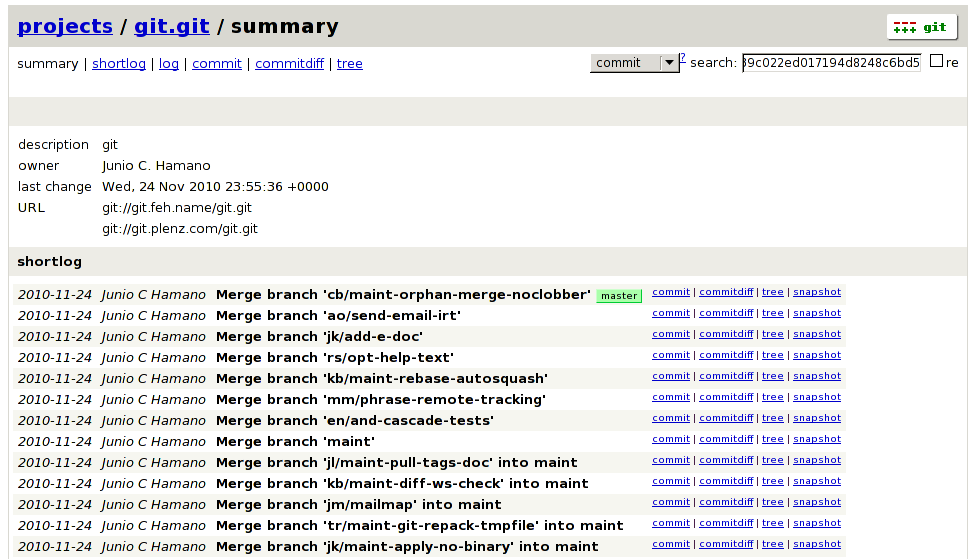
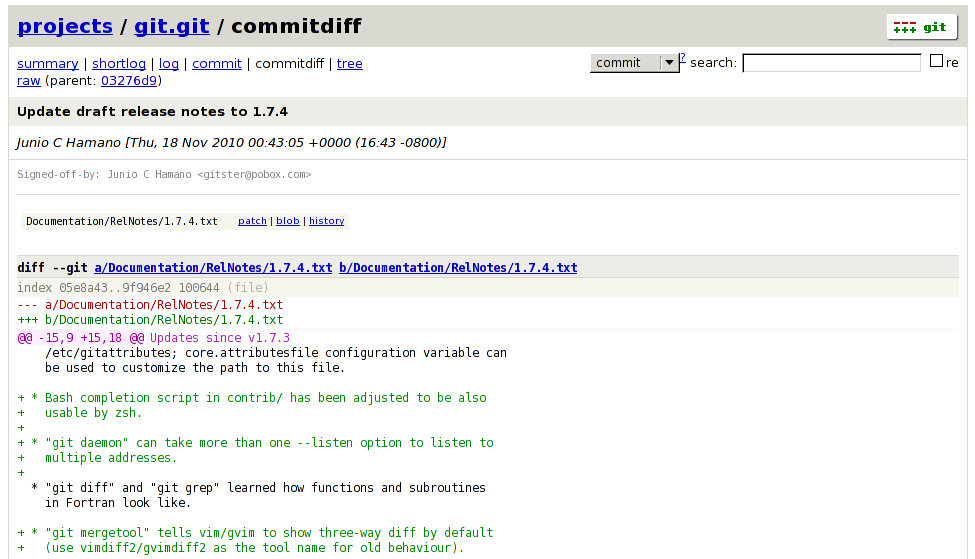
CGit („CGI für Git“) ist ein alternatives Webfrontend. Im Gegensatz zu Gitweb, das komplett in Perl geschrieben ist, ist CGit in C geschrieben und arbeitet, wo möglich, mit Caching. Dadurch ist es viel schneller als Gitweb.
Um CGit zu installieren, müssen Sie zuerst die Sourcen herunterladen. Es wird die aktuelle Git-Version benötigt, um auf Routinen aus dem Git-Quellcode zurückzugreifen. Dafür muss das bereits konfigurierte Submodul initialisiert und der Code heruntergeladen werden:
$ git clone git://git.zx2c4.com/cgit ... $ cd cgit $ git submodule init Submodule 'git' (git://git.kernel.org/pub/scm/git/git.git) registered for path 'git' $ git submodule update <Git-Sourcen werden heruntergeladen.>
Per Default installiert CGit die CGI-Datei in einem etwas obskuren
Verzeichnis /var/www/htdocs/cgit. Um etwas sinnvollere
Alternativen zu wählen, legen Sie im CGit-Verzeichnis eine Datei
cgit.conf an, die automatisch vom Makefile
inkludiert wird:
CGIT_SCRIPT_PATH=/usr/lib/cgi-bin CGIT_DATA_PATH=/usr/share/cgit
Nun lässt sich das Programm mit make install übersetzen und
installieren. Allerdings empfiehlt es sich, checkinstall[105]
zu verwenden, so dass Sie das Paket ggf. leicht wieder loswerden
können.
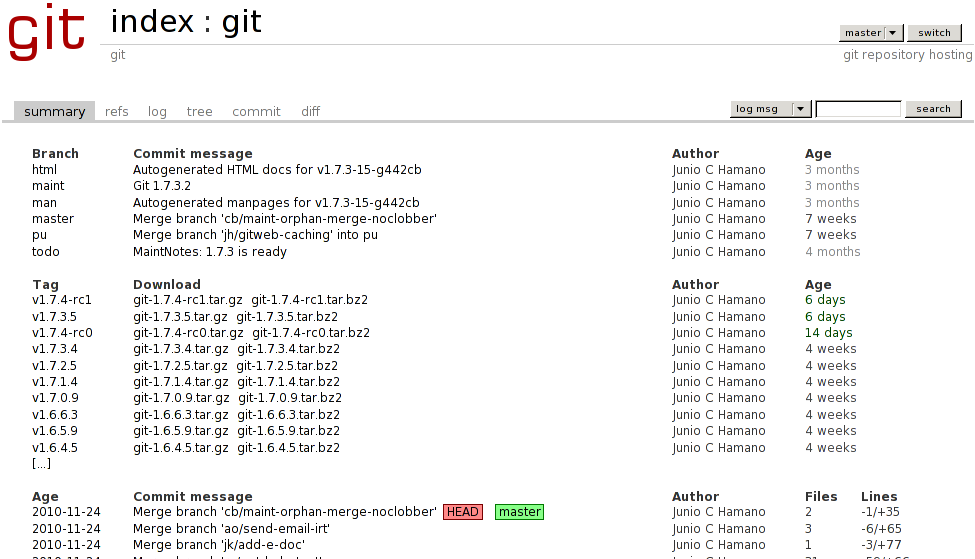
Die Einbindung in Apache und Lighttpd erfolgt ähnlich. Da CGit
allerdings „hübschere“ URLs verwendet (wie z.B. http://git.example.com/dwm/tree/dwm.c für die Datei
dwm.c aus dem dwm-Repository), muss ein wenig
Aufwand betrieben werden, um die URLs umzuschreiben.
Die folgenden Konfigurationen lassen CGit auf git.example.com
laufen:
<VirtualHost *:80> ServerName git.example.com AcceptPathInfo On Options +ExecCGI Alias /cgit.css /usr/share/cgit/cgit.css Alias /cgit.png /usr/share/cgit/cgit.png AliasMatch ^/(.*) /usr/lib/cgi-bin/cgit.cgi/$1 </VirtualHost>
Für Lighttpd muss man ein wenig tricksen. Sie dürfen nicht vergessen,
virtual-root=/ zu konfigurieren (s.u. – diese Einstellung
ist auch für Apache nicht schädlich).
$HTTP["host"] =~ "^git\.example\.com(:\d+)?$" {
alias.url = (
"/cgit.css" => "/usr/share/cgit/cgit.css",
"/cgit.png" => "/usr/share/cgit/cgit.png",
"/cgit.cgi" => "/usr/lib/cgi-bin/cgit.cgi",
"/" => "/usr/lib/cgi-bin/cgit.cgi",
)
cgi.assign = ( ".cgi" => "" )
url.rewrite-once = (
"^/cgit\.(css|png)" => "$0", # statische Seiten "durchreichen"
"^/.+" => "/cgit.cgi$0"
)
}
Die Konfiguration wird über die Datei /etc/cgitrc geregelt.
Eine Liste der unterstützten Optionen finden Sie in der Datei
cgitrc.5.txt im Quellverzeichnis von CGit (leider bringt das
Programm keine sonstige Dokumentation mit). Die wichtigsten sind
nachfolgend aufgeführt:
-
clone-prefix -
URL, unter der der Quellcode (bevorzugt per
Git-Protokoll) heruntergeladen werden kann (analog zu
@git_base_url_listvon Gitweb). -
enable-index-links - Wenn auf 1 gesetzt, erscheint in der Auflistung der Repositories eine weitere Spalte, mit direkten Links zu den Tabs „summary“, „log“ und „tree“.
-
enable-gitweb-owner -
Wenn auf 1 gesetzt, dann wird der Eigentümer
aus der Konfiguration
gitweb.ownerdes Git-Repositorys ausgelesen. Gitolite setzt diese Option automatisch, wenn Sie einen Namen festlegen, siehe Abschnitt 7.2.3, „Eigentümer und Beschreibung“. -
enable-log-filecount - Zeigt zu jedem Commit eine Spalte an, in der die Anzahl der geänderten Dateien stehen.
-
enable-log-linecount -
Analog zu
-filecount, zeigt eine Bilanz von hinzugekommenen/entfernten Zeilen an. -
scan-path -
Pfad, den CGit nach Git-Repositories durchsuchen
soll. Achtung: Diese Option berücksichtigt nicht, ob das Repository
durch die Datei
git-daemon-export-okfreigegeben wurde (siehe auchproject-list)! Beachten Sie außerdem, dass die auf diese Weise hinzugefügten Repositories nur die Einstellungen erben, die bis dahin getätigt wurden. Es empfiehlt sich daher, diescan-path-Zeile als letzte in der Datei aufzuführen. -
project-list -
Liste von Projektdateien, die im
scan-pathberücksichtigt werden sollen. Gitolite legt eine solche Datei für alle öffentliches Repositories an. Siehe die Beispielkonfiguration weiter unten. -
remove-suffix -
Wenn die Option auf 1 gesetzt wird: Das Suffix
.gitwird aus URLs bzw. aus dem Namen von Repositories entfernt. -
root-title - Überschrift, die auf der Startseite neben dem Logo angezeigt wird.
-
root-desc - Schriftzug, der auf der Startseite unter der Überschrift angezeigt wird.
-
side-by-side-diffs - Wird die Option auf 1 gesetzt, werden bei der Diff-Ausgabe zwei Dateien nebeneinander angezeigt, anstatt das Unified-Diff-Format zu verwenden.
-
snapshots -
Gibt an, welche Snapshot-Formate angeboten werden. Per
Default werden keine angeboten. Möglich sind
tar,tar.gz,tar.bz2undzip. Geben Sie die gewünschten Formate durch Leerzeichen getrennt an. -
virtual-root -
Legt fest, welche URL CGit jedem Link voranstellen
soll. Sofern Sie CGit auf „oberster“ Ebene, also
z.B.
http://git.example.com, laufen lassen wollen, sollte diese Option den Wert/erhalten (dies ist vor allem notwendig, wenn Sie Lighttpd verwenden). Wollen Sie CGit stattdessen in einem Unterverzeichnis laufen lassen, sollten Sie diese Option entsprechend anpassen, z.B. auf/git.
Mit folgender Konfiguration taucht jedes Repository, auf dem Sie in
Gitolite dem Nutzer gitweb Zugriff erlaubt haben, in der
Auflistung auf – außerdem werden Beschreibung und Autor (sofern
angegeben, siehe Abschnitt 7.2.3, „Eigentümer und Beschreibung“) angezeigt:
virtual-root=/ enable-gitweb-owner=1 remove-suffix=1 project-list=/var/git/projects.list scan-path=/var/git/repositories
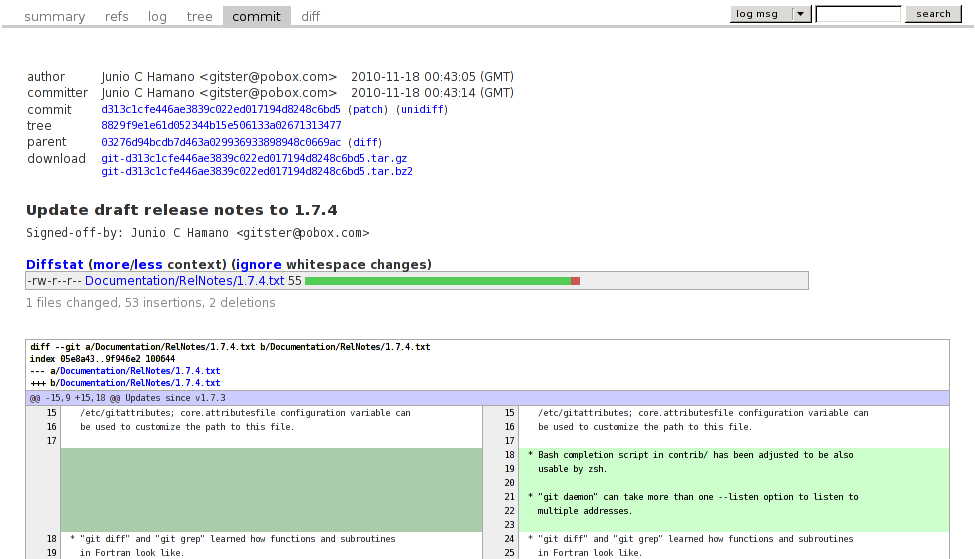
Durch die oben erläuterte Option scan-path ist es in
Kombination mit Gitolite in der Regel nicht nötig, Repositories
einzeln hinzuzufügen und zu konfigurieren. Wollen Sie dies aber tun
bzw. sind Ihre Repositories nicht an einer zentralen Stelle gelagert,
können Sie dies pro Repository wie folgt:
repo.url=foo repo.path=/pub/git/foo.git repo.desc=the master foo repository repo.owner=fooman@example.com
Für weitere repositoryspezifische Konfigurationen konsultieren Sie die
Beispiel-Konfigurationsdatei bzw. in die Erläuterungen der Optionen
in der Datei cgitrc.5.txt im Quellverzeichnis von CGit. Sie
können diese händisch konfigurierten Repositories auch unter
verschiedenen Sektionen gruppieren (Option
section).
CGit ist im Vergleich zu Gitweb besonders schnell, weil es in C geschrieben ist und außerdem Caching unterstützt. Das ist vor allem dann notwendig, wenn Sie viele Repositories und/oder viele Seitenzugriffe in kurzer Zeit haben.
CGit verwendet einen simplen Hash-Mechanismus, um zu überprüfen, ob
eine Anfrage schon im Cache vorhanden und nicht zu alt ist
(konfigurierbar, siehe folgende Liste). Wenn ein
solcher Cache-Eintrag vorhanden ist, wird dieser ausgeliefert, statt
die gleiche Seite neu zu erzeugen (der HTTP-Header
Last-Modified bleibt auf dem alten Stand, d.h. der Browser
weiß, von wann die Seite ist).
CGit speichert auch das Resultat von scan-path zwischen. So
muss CGit für die Übersichtsseite nicht jedes Mal alle Repositories
einzeln hinzufügen.
-
cache-root -
Pfad, unter dem die Cache-Dateien gespeichert werden;
der Default ist
/var/cache/cgit. -
cache-size - Anzahl der Einträge (d.h. einzelne Seiten), die der Cache enthält. Der Default-Wert ist 0, also ist Caching ausgeschaltet. Ein Wert ab 500 sollte selbst für große Seiten reichen.
-
cache-<typ>-ttl -
Zeit in Minuten, die ein Cache-Eintrag als
„aktuell“ gilt. Die Zeit können Sie für einzelne Seiten speziell
konfigurieren. Mögliche Typen sind:
scanrcfür das Ergebnis vonscan-path,rootfür die Auflistung der Repositories,repofür die „Startseite“ eines Repositorys sowiedynamicbzw.staticfür die „dynamischen“ Seiten (wie z.B. für Branch-Namen) bzw. statische Seiten (wie z.B. für einen Commit, der anhand seiner SHA-1-Summe identifiziert wird). Per Default sind diese Werte auf fünf Minuten gesetzt, bis aufscanrc(15).
Ein weiterer wichtiger Faktor, der beeinflusst, wie schnell sich die Index-Seite aufbaut, ist die Verwendung von sogenannten Agefiles. Die Spalte Idle („untätig“) wird normalerweise jedes Mal neu erzeugt, indem CGit die Branches jedes Repositorys durchgeht und das Alter notiert. Das ist allerdings nicht sehr schnell.
Praktischer ist es, pro Repository eine Datei zu verwenden, die
angibt, wann der letzte Commit hochgeladen wurde. Das lässt sich am
besten mit Hooks (siehe Abschnitt 8.2, „Hooks“) erledigen. Verwenden
Sie dieses Kommando im Hook post-update:
mkdir -p info/web || exit 1
git for-each-ref \
--sort=-committerdate \
--format='%(committerdate:iso8601)' \
--count=1 'refs/heads/*' \
> info/web/last-modified
Wenn Sie statt info/web/last-modified (relativ zu
$GIT_DIR) einen anderen Pfad verwenden wollen, nutzen Sie
für die Angabe den CGit-Konfigurationsschlüssel agefile.
[92] Eine genauere Beschreibung findet sich im Git-Quellrepository im Verzeichnis Documentation/technical. Dort finden sich drei Dateien, die das Packfile-Format erklären, teilweise entstanden aus Erklärungen von Linus Torvalds im IRC: pack-format.txt, pack-heuristics.txt, pack-protocol.txt. Moderne Versionen von Git verwenden außerdem zusätzlich einen „Bitmap Reachability Index“, der in bitmap-format.txt erklärt ist.
[93] Die hier beschriebene Installation und Konfiguration bezieht sich auf Gitolite in Version 3.6. Seit Gitolite Version 1.5, das in der ersten Auflage dieses Buches beschrieben wurde, gab es einige inkompatible Änderungen, die Sie hier nachlesen können: http://gitolite.com/gitolite/migr.html
[94] Ein Nutzer kann sich nur mit seinem privaten Schlüssel bei einem SSH-Server authentifizieren, wenn er eine mit seinem öffentlichen (und bei Gitolite hinterlegten) Schlüssel verschlüsselte Nachricht entschlüsseln kann. Anhand des Schlüssels, gegen den sich der Nutzer authentifiziert, kann Gitolite also den internen Nutzernamen ableiten.
[95] Einige Distributionen stellen auch vorgefertigte Pakete von Gitolite zur Verfügung. Von deren Einsatz ist allerdings eher abzuraten, weil sie meist veraltet sind und außerdem global und mit einer bestimmten Konfiguration installiert werden. Wenn Sie dann einen anderen Nutzernamen als den von den Entwicklern ausgesuchten wählen, müssen Sie einen erheblichen Mehraufwand betreiben, um Gitolite zum Laufen zu bringen.
[96] Ein Release Candidate einer Software
ist eine Vorab-Version eines neuen Releases, das der Öffentlichkeit
(und nicht nur einer kleinen Gruppe von Beta-Testern) zugänglich
gemacht wird. In das finale Release fließen dann nur noch Bugfixes
ein. Auf Version 1.0 RC 1 (v1.0-rc1) folgt RC 2
(v1.0-rc2) usw., bis Version 1.0 herausgegeben wird
(v1.0).
[97] Den lesenden Zugriff auf ein Unterverzeichnis kann Gitolite natürlich nicht verbieten; das würde das Konzept des Git-Objekt-Modells mit seiner kryptografisch garantierten Integrität ad absurdum führen.
[98] Beachten Sie auch, dass es hier wieder zu Problemen bei der Erstellung von Branches kommen kann, s.o.
[99] Die Dokumentation findet sich unter http://gitolite.com/. Der Autor hat außerdem das Buch „Gitolite Essentials“ veröffentlicht (Packt Publishing, 2014).
[100] Streng genommen ist es dafür nötig,
dass der kopierte HEAD mit dem der Gegenseite übereinstimmt.
Besser noch überprüfen Sie ein von einem Entwickler signiertes
Versions-Tag.
[101] In manchen Distributionen, wie
z.B. Debian, heißt der Daemon openbsd-inetd.
[102] Das Programm sv ist Teil des
Init-Frameworks runit
(http://smarden.org/runit/). Es ersetzt die Funktionalität
des SysV-Init, kann aber auch darin integriert werden.
[103] Beachten Sie, dass eine Instanz des Git-Daemons nicht „teuer“ ist. Das Zusammenpacken der angeforderten Objekte ist es allerdings. Nur weil Ihr Server also mehrere Dutzend HTTP-Abfragen pro Sekunde schafft, heißt das nicht, dass er auch dieselbe Anzahl Git-Verbindungen schafft.
[104] Beachten Sie, dass die Reihenfolge in der
alias.url-Direktive wichtig ist. Wenn Sie die Zeile
"/" => ... nach oben verschieben, startet Lighttpd nicht
mehr bzw. die Alias-Zuordnung wird nicht die gewünschte sein.
[105] Das Tool checkinstall baut
automatisch Debian- oder RPM-Pakete, die alle Dateien enthalten, die
durch make install installiert worden wären. Homepage des
Programmes:
http://www.asic-linux.com.mx/~izto/checkinstall/
