Git ist ein verteiltes Versionskontrollsystem. Um diese Eigenschaft zu verstehen, ist zunächst ein kurzer Exkurs in die Welt der zentralen Versionsverwaltung notwendig: Wie der Name schon sagt, wird bei einem zentralen Versionskontrollsystem, wie z.B. RCS, CVS und Subversion, die Entwicklungsgeschichte zentral auf einem Server in dem Repository abgespeichert, und alle Entwickler synchronisieren ihre Arbeit mit diesem einen Repository. Entwickler, die etwas verändern möchten, laden sich eine aktuelle Version auf ihren Rechner herunter (Checkout), pflegen ihre Modifikationen ein und schicken diese dann wieder an den Server zurück (Commit).
Einer der großen Nachteile des zentralen Ansatzes ist, dass für die meisten Arbeitsschritte eine Verbindung zum Server bestehen muss. Möchten Sie z.B. die Geschichte einsehen oder einen Commit machen, brauchen Sie eine Netzwerkverbindung zum Server. Leider ist diese nicht immer gewährleistet, vielleicht ist der Server außer Betrieb oder Sie arbeiten gerade auf Ihrem Laptop ohne (W)LAN-Anschluss.
Bei verteilten Systemen ist das anders geregelt: Grundsätzlich verfügt hier jeder Entwickler über eine eigene, lokale Kopie des Repositorys – stellt sich also die Frage, wie Entwickler Veränderungen untereinander austauschen.
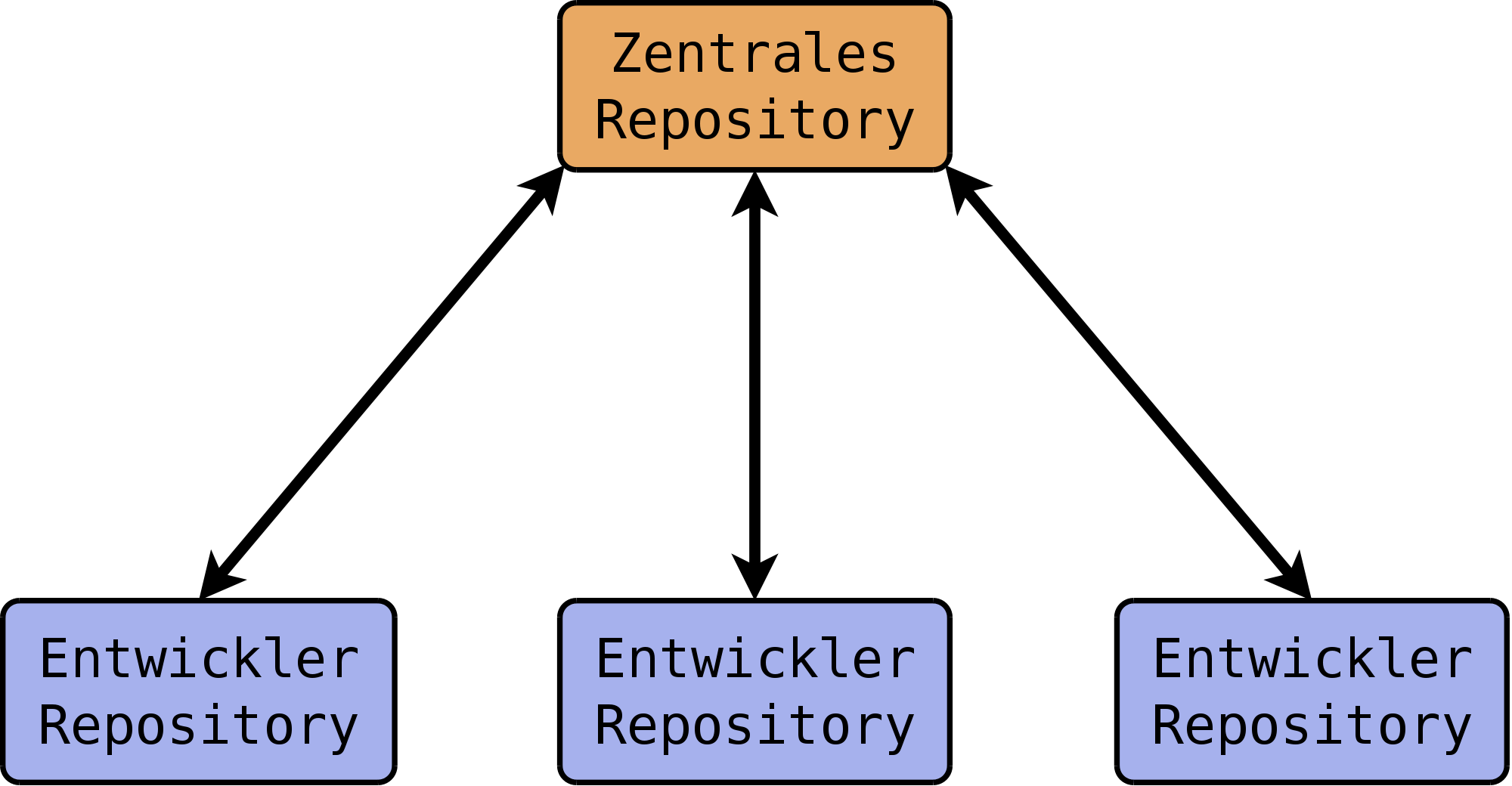
Ein Ansatz ist, ein einzelnes „Haupt-Repository“ bereitzustellen, das alle Entwickler nutzen, um ihre lokalen Repositories zu synchronisieren. Die Entwickler verbinden sich also ab und zu mit diesem Repository, laden die eigenen Commits hoch (Push) und die der Kollegen herunter (Fetch bzw. Pull). Dieser sehr zentrale Ansatz kommt in der Praxis häufig zum Einsatz. Eine Darstellung finden Sie in Abbildung 5.1, „Zentraler Workflow mit verteilter Versionsverwaltung“.
Es gibt im Git-Umfeld allerdings zwei nennenswerte Alternativen, die wir in diesem Kapitel vorstellen: den Integration-Manager-Workflow, bei dem mehrere öffentliche Repositories zum Einsatz kommen (Abschnitt 5.6, „Verteilter Workflow mit mehreren Remotes“), und den Patch-Austausch per E-Mail (Abschnitt 5.9, „Patches per E-Mail“).
Im Unterschied zu zentralen Systemen erfolgen die Commit- und Checkout-Vorgänge bei Git lokal. Auch andere alltägliche Aufgaben, wie das Einsehen der Geschichte oder das Wechseln in einen Branch, spielen sich lokal ab. Einzig das Hoch- und Herunterladen von Commits sind nicht-lokale Vorgänge. Dadurch ergeben sich im Vergleich zur zentralen Versionsverwaltung zwei wichtige Vorteile: Es wird kein Netzwerk gebraucht, und alles geht (darum) schneller. Wie häufig Sie Ihr Repository synchronisieren, hängt unter anderem von der Größe und der Entwicklungsgeschwindigkeit des Projekts ab. Arbeiten Sie gerade mit einem Kollegen an den Interna Ihrer Software, müssen Sie wahrscheinlich häufiger synchronisieren als bei einem Feature, das keine weitreichenden Auswirkungen auf die übrige Codebasis hat. Es kann durchaus sein, dass einmaliges Synchronisieren pro Tag genügt. So können Sie auch ohne permanente Netzanbindung produktiv arbeiten.
In diesem Kapitel geht es darum, wie Sie Veränderungen zwischen Ihrem lokalen und einem entfernten Repository (Remote Repository oder Remote) austauschen, was Sie beachten müssen, wenn Sie mit mehreren Remotes arbeiten, und wie Sie Patches per E-Mail verschicken, so dass sie leicht vom Empfänger einzupflegen sind.
Die wichtigsten Kommandos im Überblick:
-
git remote - Allgemeine Konfiguration von Remotes: hinzufügen, entfernen, umbenennen usw.
-
git clone - Komplette Kopie herunterladen.
-
git pullundgit fetch - Commits und Referenzen aus einem Remote herunterladen.
-
git push - Commits und Referenzen in ein Remote hochladen.
Den ersten Befehl in Zusammenhang mit den Remote-Repositories haben
Sie bereits kennengelernt: git clone. Hier illustrieren wir
den Klonvorgang mit unserem
„Git-Spickzettel“[65]:
$ git clone git://github.com/esc/git-cheatsheet-de.git
Initialized empty Git repository in /tmp/test/git-cheatsheet-de/.git/
remote: Counting objects: 77, done.
remote: Compressing objects: 100% (77/77), done.
remote: Total 77 (delta 45), reused 0 (delta 0)
Receiving objects: 100% (77/77), 132.44 KiB, done.
Resolving deltas: 100% (45/45), done.
Bei diesem Aufruf gibt Git diverse Statusmeldungen aus. Die
wichtigsten sind: die Benachrichtigung, in welches Verzeichnis das
neue Repository geklont wird (Initialized empty Git repository
in /tmp/test/git-cheatsheet-de/.git/), sowie die Bestätigung, dass
alle Objekte erfolgreich empfangen wurden (Receiving objects:
100% (77/77), 132.44 KiB, done.). Ist der Klonvorgang erfolgreich,
wird der master-Branch ausgecheckt,[66] und der Working Tree samt
Repository befindet sich in dem Verzeichnis
git-cheatsheet-de.
$ cd git-cheatsheet-de $ ls cheatsheet.pdf cheatsheet.tex Makefile README $ ls -d .* .git/
Um den Klon in einem anderen Verzeichnis zu erstellen, übergeben Sie es einfach als Argument:
$ git clone git://github.com/esc/git-cheatsheet-de.git cheatsheet Initialized empty Git repository in /tmp/test/cheatsheet/.git/ $ ls cheatsheet/
Außerdem wird das Ursprungsrepository, also die Herkunft des Klons,
als Remote-Repository mit dem Namen origin konfiguriert. Das
Kommando git remote zeigt die Einstellung an:
$ git remote
origin
Die Einstellung wird in der Konfigurationsdatei .git/config mit dem Eintrag
remote festgehalten, in diesem Fall nur für origin:
[remote "origin"]
fetch = +refs/heads/*:refs/remotes/origin/*
url = git://github.com/esc/git-cheatsheet-de.git
Sie sehen in dem Ausschnitt zwei Einstellungen: fetch und
url. Die erste, der sog. Refspec, gibt an, welche
Veränderungen bei der Synchronisation mit dem Remote-Repository
heruntergeladen werden sollen, und die zweite, mit welcher URL dies
geschieht.
Außerdem dient git remote zum Verwalten von
Remote-Repositories. Sie können z.B. mit git remote add
weitere Remote-Repositories hinzufügen, über git remote
set-url die URL für das Remote-Repository anpassen usw., doch dazu später
mehr.
Der Name origin ist nur eine Konvention; mit git
remote rename passen Sie den Namen des Ursprungsrepositorys Ihren
Wünschen entsprechend an, z.B. von origin
zu github:
$ git remote rename origin github $ git remote github
Mit der Option --origin bzw. -o setzen Sie den
Namen gleich beim Klonen:
$ git clone -o github git://github.com/esc/git-cheatsheet-de.git
Git unterstützt mehrere Protokolle, um auf ein Remote-Repository zuzugreifen, die gängigsten drei sind das Git-Protokoll, SSH und HTTP(S). Das Git-Protokoll wurde speziell für Git entwickelt und begünstigt die Datenübertragung, da immer die kleinstmögliche Datenmenge übertragen wird. Es unterstützt keine Authentifizierung und wird daher häufig in einer SSH-Verbindung übertragen. Dadurch wird sowohl eine effiziente (Git-Protokoll) als auch sichere (SSH) Übertragung gewährleistet. HTTP(S) kommt dann zum Einsatz, wenn eine Firewall sehr restriktiv konfiguriert ist und die zugelassenen Ports drastisch eingeschränkt sind.[67]
Im Allgemeinen enthält eine valide URL das Übertragungsprotokoll, die Adresse des Servers sowie den Pfad zu dem Repository:[68]
-
ssh://[user@]gitbu.ch[:port]/pfad/zum/repo.git/ -
git://gitbu.ch[:port]/pfad/zum/repo.git/ -
http[s]://gitbu.ch[:port]/pfad/zum/repo.git/
Für das SSH-Protokoll existiert noch die Kurzform:
-
[user@]gitbu.ch:pfad/zum/repo.git/
Außerdem ist es möglich, lokale Repositories mit der folgenden Syntax zu klonen:
-
/pfad/zum/repo.git/ -
file:///pfad/zum/repo.git/
Wenn Sie wissen wollen, welche URLs für ein Remote-Repository
konfiguriert sind, verwenden Sie die Option --verbose
bzw. -v von git remote:
$ git remote -v
origin git://github.com/esc/git-cheatsheet-de.git (fetch)
origin git://github.com/esc/git-cheatsheet-de.git (push)
Sie sehen, dass es zwei URLs für das Remote-Repository origin
gibt, die aber standardmäßig auf denselben Wert gesetzt sind. Die
erste URL (fetch) gibt an, von wo und mit welchem Protokoll
Veränderungen heruntergeladen werden. Die zweite URL (push)
gibt an, wohin und mit welchem Protokoll Veränderungen hochgeladen
werden. Unterschiedliche URLs sind vor allem dann interessant, wenn
Sie mit verschiedenen Protokollen herunter- bzw. hochladen. Ein
gängiges Beispiel ist, mit dem Git-Protokoll (git://)
herunterzuladen und mit dem SSH-Protokoll (ssh://) hoch. Es
wird dann ohne Authentifizierung und Verschlüsselung heruntergeladen,
was einen Geschwindigkeitsvorteil bietet, aber mit Authentifizierung
und Verschlüsselung hochgeladen, was sicherstellt, dass nur Sie oder
andere zugriffsberechtigte Personen hochladen können. Mit dem
Kommando git remote set-url passen Sie die URLs an:
$ git remote set-url --add \ --push origin git@github.com:esc/git-cheatsheet-de.git $ git remote -v origin git://github.com/esc/git-cheatsheet-de.git (fetch) origin git@github.com:esc/git-cheatsheet-de.git (push)
Tipp
Falls Sie die URL eines Repositorys anpassen wollen, ist es häufig
schneller, dies direkt in der Konfigurationsdatei .git/config
zu tun. Git stellt dafür das Kommando git config -e bereit: es öffnet
diese Datei in Ihrem Editor.
Der aktuelle Zustand des Remote-Repositorys wird lokal gespeichert. Git verwendet dazu den Mechanismus der Remote-Tracking-Branches, spezielle Branches – also lokale Referenzen – , die den Zustand der Branches im Remote, sog. Remote-Branches, widerspiegeln. Sie „verfolgen“ also die Remote-Branches und werden bei einer Synchronisation mit dem Remote entsprechend von Git vorgerückt bzw. gesetzt, sofern sich die Branches in dem Remote verändert haben. Im Hinblick auf den Commit-Graphen sind Remote-Tracking-Branches Markierungen innerhalb des Graphen, die auf die gleichen Commits zeigen wie die Branches im Remote-Repository. Sie können Remote-Tracking-Branches nicht wie normale Branches verändern, Git verwaltet sie automatisch, sorgt also für deren Aktualisierung. Wenn Sie ein Repository klonen, initialisiert Git für jeden Remote-Branch einen Remote-Tracking-Branch.
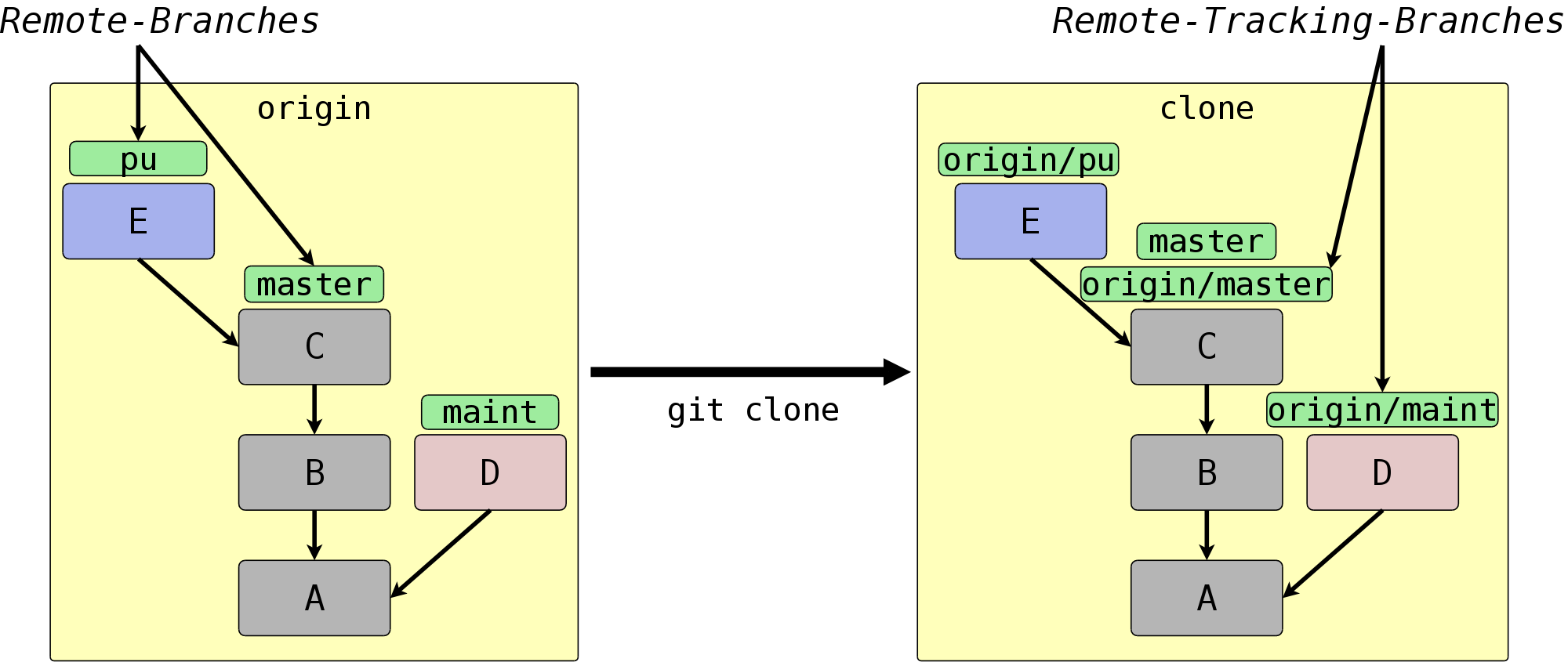
In Abbildung 5.2, „Erzeugte Remote-Tracking-Branches“ sehen Sie ein Beispiel. Das
Remote-Repository origin hat drei Branches: pu,
maint und master. Git erstellt in dem geklonten
Repository für jeden dieser Remote-Branches einen
Remote-Tracking-Branch. Außerdem wird in dem Klon ein lokaler
Branch master erstellt, der dem Remote-Branch master
entspricht. Dieser wird ausgecheckt und ist der Branch, in dem Sie
arbeiten sollten, wenn Sie vorhaben, Commits in den master
hochzuladen (siehe aber auch
Abschnitt 5.3.1, „git fetch“).
In dem Beispiel mit dem Git-Spickzettel gibt es auf der Remote-Seite
nur einen einzigen Branch, nämlich master. Darum erzeugt Git
in dem Klon auch nur einen Remote-Tracking-Branch, und zwar
origin/master. Der Befehl git branch -r zeigt alle
Remote-Tracking-Branches an:
$ git branch -r
origin/HEAD -> origin/master
origin/master
Der Sondereintrag origin/HEAD -> origin/master besagt, dass
in dem Remote-Repository der HEAD auf den Branch
master zeigt. Das ist für das Klonen insofern wichtig, als
dieser Branch nach dem Klonen ausgecheckt wird. Die Liste der
Remote-Tracking-Branches ist in dem Beispiel etwas spärlich, mehr
Einträge sehen Sie in einem Klon des Git-via-Git Repositorys:
$ git branch -r
origin/HEAD -> origin/master
origin/html
origin/maint
origin/man
origin/master
origin/next
origin/pu
origin/todo
Alle Branches lassen Sie sich mit git branch -a anzeigen:
$ git branch -a
* master
remotes/origin/HEAD -> origin/master
remotes/origin/master
In diesem Fall verwendet Git das Präfix remotes/, um
Remote-Tracking-Branches eindeutig von den normalen zu unterscheiden.
Haben Sie die Farbausgabe aktiviert, werden die
unterschiedlichen Branches zudem farblich kodiert:
der ausgecheckte Branch grün, Remote-Tracking-Branches rot.
Remote-Tracking-Branches sind auch nur Referenzen und werden daher wie
alle Referenzen unter .git/refs gespeichert. Da es sich aber
um besondere Referenzen handelt, die zudem noch mit einem
Remote-Repository verknüpft sind, landen sie unter
.git/refs/remotes/<remote-name> (siehe auch
Abschnitt 3.1.1, „HEAD und andere symbolische Referenzen“).
In Gitk werden die Remote-Tracking-Branches mit
dem Präfix remotes/<remote-name>/ angezeigt, das zudem dunkelgelb
gefärbt ist (Abbildung 5.3, „Branch next und der entsprechende Remote-Tracking-Branch in Gitk“).
Was bedeutet es nun, wenn Sie zwei Repositories synchronisieren,
etwa einen Klon mit dem Ursprung? Synchronisation bedeutet in diesem
Kontext zweierlei: erstens das Herunterladen von Commits und
Referenzen, zweitens das Hochladen. Im Hinblick auf den Commit-Graphen
muss der lokale Graph mit dem auf der Remote-Seite synchronisiert
werden, damit beide dieselbe Struktur haben. In diesem Abschnitt
behandeln wir zunächst, wie Sie Commits und Referenzen aus einem
Remote herunterladen. Dafür gibt es zwei Kommandos: git fetch
und git pull. Wir stellen zuerst beide Kommandos vor und
beschreiben in Abschnitt 5.3.3, „git fetch vs. git pull“, welches Kommando
unter welchen Umständen zu bevorzugen ist.
Sobald in einem Remote neue Commits von anderen Entwicklern angelegt wurden, wollen Sie diese in Ihr lokales Repository herunterladen. Im einfachsten Fall wollen Sie nur herausfinden, welche Commits Sie lokal noch nicht haben, diese herunterladen und die Remote-Tracking-Branches auf den neuesten Stand bringen, so dass sie den aktuellen Zustand im Remote widerspiegeln.
Verwenden Sie dazu das Kommando git fetch:
$ git fetch origin
...
From github.com:esc/git-cheatsheet-de
79170e8..003e3c7 master -> origin/master
Git quittiert den Aufruf mit einer Meldung, dass
origin/master von dem Commit 79170e8 auf den Commit
003e3c7 gesetzt wurde. Die Notation master ->
origin/master besagt, dass der Branch master aus dem
Remote verwendet wurde, um den Remote-Tracking-Branch
origin/master zu aktualisieren. Sprich: Branches aus dem
Remote auf der linken Seite und Remote-Tracking-Branches auf der
rechten.
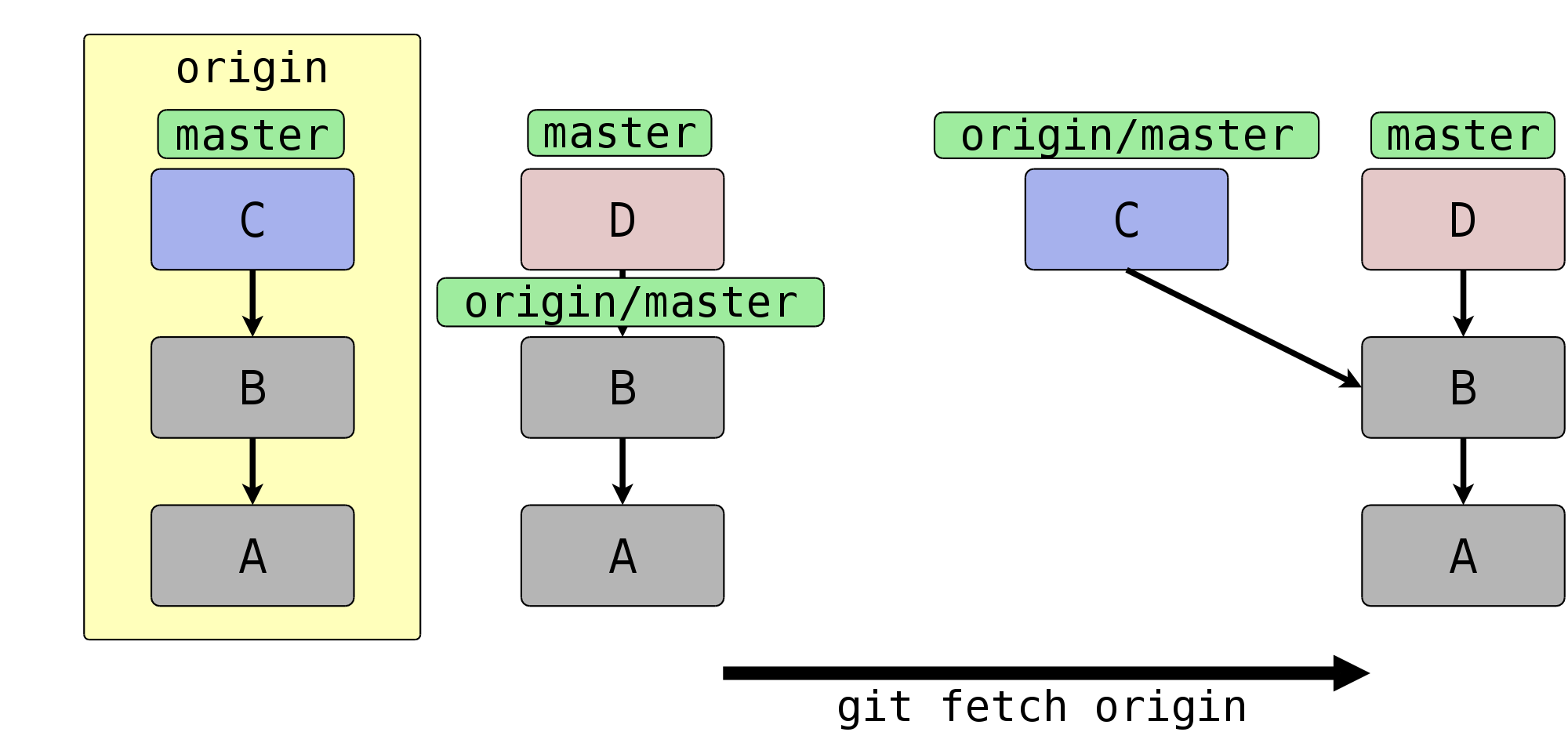
Welche Auswirkung das auf den Commit-Graphen hat, sehen Sie in
Abbildung 5.4, „Remote-Tracking-Branches werden aktualisiert“: Auf der linken Seite ist der
Ausgangszustand des Remote origin und daneben der des
Klons dargestellt. Sowohl im Remote als auch im Klon sind seit der
letzten Synchronisation neue Commits hinzugekommen (C und D). Der
Remote-Tracking-Branch origin/master im Klon zeigt auf Commit
B; dies ist der letzte Zustand des Remotes, der dem Klon bekannt ist.
Durch einen Aufruf von git fetch origin aktualisiert Git den
Remote-Tracking-Branch im Klon, damit dieser den aktuellen Zustand des
master (zeigt auf Commit C) im Remote widerspiegelt. Dazu
lädt Git den fehlenden Commit C herunter und setzt anschließend den
Remote-Tracking-Branch darauf.
Der Refspec (Reference Specification) sorgt dafür, dass die Remote-Tracking-Branches gesetzt werden. Dies ist eine Beschreibung der Referenzen, die aus dem Remote geholt werden sollen. Ein Beispiel gab es schon weiter oben:
[remote "origin"]
fetch = +refs/heads/*:refs/remotes/origin/*
url = git://github.com/esc/git-cheatsheet-de.git
In dem Eintrag fetch wird der Refspec für das Remote
gespeichert. Er hat die Form: <remote-refs>:<lokale-refs> mit
einem optionalen Plus (+). Das Beispiel ist so konfiguriert,
dass alle Branches, also alle Referenzen, die im Remote unter
refs/heads gespeichert sind, lokal unter
refs/remotes/origin
landen.[69] Somit wird
z.B. der Branch master aus dem Remote
origin (refs/heads/master) lokal als
refs/remotes/origin/master gespeichert.
Im Normalfall werden die Remote-Tracking-Branches, ähnlich wie bei
einem Fast-Forward-Merge, „vorgespult“. Der
Remote-Tracking-Branch wird also nur aktualisiert, wenn der
Ziel-Commit ein Nachfahre der aktuellen Referenz ist. Es kann
vorkommen, dass dies nicht möglich ist, z.B. nach einem Rebase. In
dem Fall verweigert Git, den Remote-Tracking-Branch zu aktualisieren.
Das Plus setzt jedoch dieses Verhalten außer Kraft, und der
Remote-Tracking-Branch wird trotzdem aktualisiert. Sollte das
vorkommen, weist Git mit dem Zusatz (forced update) darauf
hin:
+ f5225b8..0efec48 pu -> origin/pu (forced update)
Diese Einstellung ist in der Praxis sinnvoll und wird daher
standardmäßig gesetzt. Außerdem müssen Sie sich als Benutzer nicht
darum kümmern, den Refspec zu setzen, denn wenn Sie das Kommando
git clone oder git remote add verwenden, erstellt Ihnen Git automatisch den entsprechenden Default-Eintrag. Manchmal
wollen Sie den Refspec explizit einschränken. Wenn Sie
z.B. Namespaces für alle Entwickler verwenden und Sie nur an dem
master-Branch sowie an den Branches der anderen Entwickler
in Ihrem Team (Beatrice und Carlos) interessiert sind, könnte das so
aussehen:
[remote "firma"]
url = axel@example.com:produkt.git
fetch = +refs/heads/master:refs/remotes/origin/master
fetch = +refs/heads/beatrice/*:refs/remotes/origin/beatrice/*
fetch = +refs/heads/carlos/*:refs/remotes/origin/carlos/*
Im Hinblick auf den Commit-Graphen ist es so, dass Git nur die Commits herunterlädt, die notwendig sind, um Referenzen in dem Commit-Graphen zu erreichen. Das ist sinnvoll, weil Commits, die nicht durch eine Referenz „gesichert“ sind, als unerreichbar gelten, und letztlich irgendwann gelöscht werden (siehe auch Abschnitt 3.1.2, „Branches verwalten“). In dem letzten Beispiel ist es deshalb für Git nicht notwendig, Commits herunterzuladen, die durch die Branches referenziert werden, die nicht im Refspec stehen. Im Sinne der Verteiltheit muss Git also nicht zwingend den gesamten Commit-Graphen synchronisieren, es reichen die „relevanten“ Teile.
Sie können alternativ auch den Refspec auf der Kommandozeile angeben:
$ git fetch origin +refs/heads/master:refs/remotes/origin/master
Sollte ein Refspec vorliegen, der keine Referenz auf der rechten Seite
des Doppelpunkts hat, liegt kein Ziel zum Speichern vor. In dem Fall
legt Git die Referenz stattdessen in der Datei
.git/FETCH_HEAD ab, und Sie können den Spezialbegriff
FETCH_HEAD für einen Merge verwenden:
$ git fetch origin master From github.com:esc/git-cheatsheet-de * branch master -> FETCH_HEAD $ cat .git/FETCH_HEAD 003e3c70ce7310f6d6836748f45284383480d40e branch 'master' of github.com:esc/git-cheatsheet-de $ git merge FETCH_HEAD
Das Feature kann nützlich sein, wenn Sie ein einziges Mal an einem Branch im Remote interessiert sind, für den Sie keinen Remote-Tracking-Branch konfiguriert haben und das auch nicht tun wollen.
Sollte ein Remote-Branch gelöscht werden (wie z.B. in Abschnitt 5.4.1, „Remote-Referenzen löschen“ beschrieben), bezeichnet man den entsprechenden Remote-Tracking-Branch als stale („abgelaufen“ bzw. „verfallen“). Da solche Branches meist keinen weiteren Nutzen haben, löschen Sie sie (engl. prune, „beschneiden“):
$ git remote prune origin
Direkt beim Herunterladen löschen:
$ git fetch --prune
Da dies häufig das gewünschte Verhalten ist, bietet Git die Option
fetch.prune an. Setzen Sie diese auf true, dann verhält sich git fetch
bei jedem Aufruf so, als ob Sie es mit der Option --prune aufgerufen
hätten.
Bisher haben wir nur besprochen, wie Sie die Veränderung in einem Remote verfolgen. Wenn Sie selbst Veränderungen vornehmen, die auf einem der Branches im Remote aufbauen, müssen Sie zuerst einen lokalen Branch erstellen, in dem Sie Commits machen dürfen:[70]
$ git checkout -b next origin/next Branch next set up to track remote branch next from origin. Switched to a new branch next
Wenn noch kein lokaler Branch mit Namen next existiert,
funktioniert auch folgende Abkürzung:
$ git checkout next Branch next set up to track remote branch next from origin. Switched to a new branch next
Die Meldung set up to track besagt, dass Git den Branch
next aus dem Remote origin als
Upstream-Branch für den lokalen Branch next
konfiguriert. Dies ist eine Art „Verknüpfung“, die anderen
Git-Kommandos zugute kommt. Genaueres finden Sie in Abschnitt 5.3.2, „git pull“.
In dem lokalen Branch können Sie wie gewohnt arbeiten. Beachten Sie
aber, dass Sie die Commits immer nur lokal tätigen. Um Ihre
Arbeit zu veröffentlichen, also in ein Remote hochzuladen, brauchen
Sie noch das Kommando git push (Abschnitt 5.4, „Commits hochladen: git push“).
Angenommen, Sie wollen Commits aus dem Remote-Repository in Ihren lokalen Branch
übernehmen. Dazu führen Sie zuerst ein git fetch aus, um neue Commits
zu holen, und anschließend mergen Sie die Veränderung aus dem entsprechenden
Remote-Tracking-Branch:[71]
$ git merge origin/master
Updating 79170e8..003e3c7
Fast-forward
cheatsheet.pdf | Bin 89792 -> 95619 bytes
cheatsheet.tex | 19 +++++++++++++++++---
2 files changed, 16 insertions(+), 3 deletions(-)
Für diesen Anwendungsfall stellt Git das Kommando git pull
bereit, um Ihren Workflow zu beschleunigen. Es ist eine Kombination
von git fetch und git merge oder git
rebase.
Neue Commits von origin herunterladen und alle Commits, die
vom dortigen master referenziert werden, in den aktuellen
Branch mergen ist also mit folgendem Kommando zu erledigen:
$ git pull origin master
...
From github.com:esc/git-cheatsheet-de
79170e8..003e3c7 master -> origin/master
Updating 79170e8..003e3c7
Fast-forward
cheatsheet.pdf | Bin 89792 -> 95619 bytes
cheatsheet.tex | 19 ++++++++++++++++---
2 files changed, 16 insertions(+), 3 deletions(-)
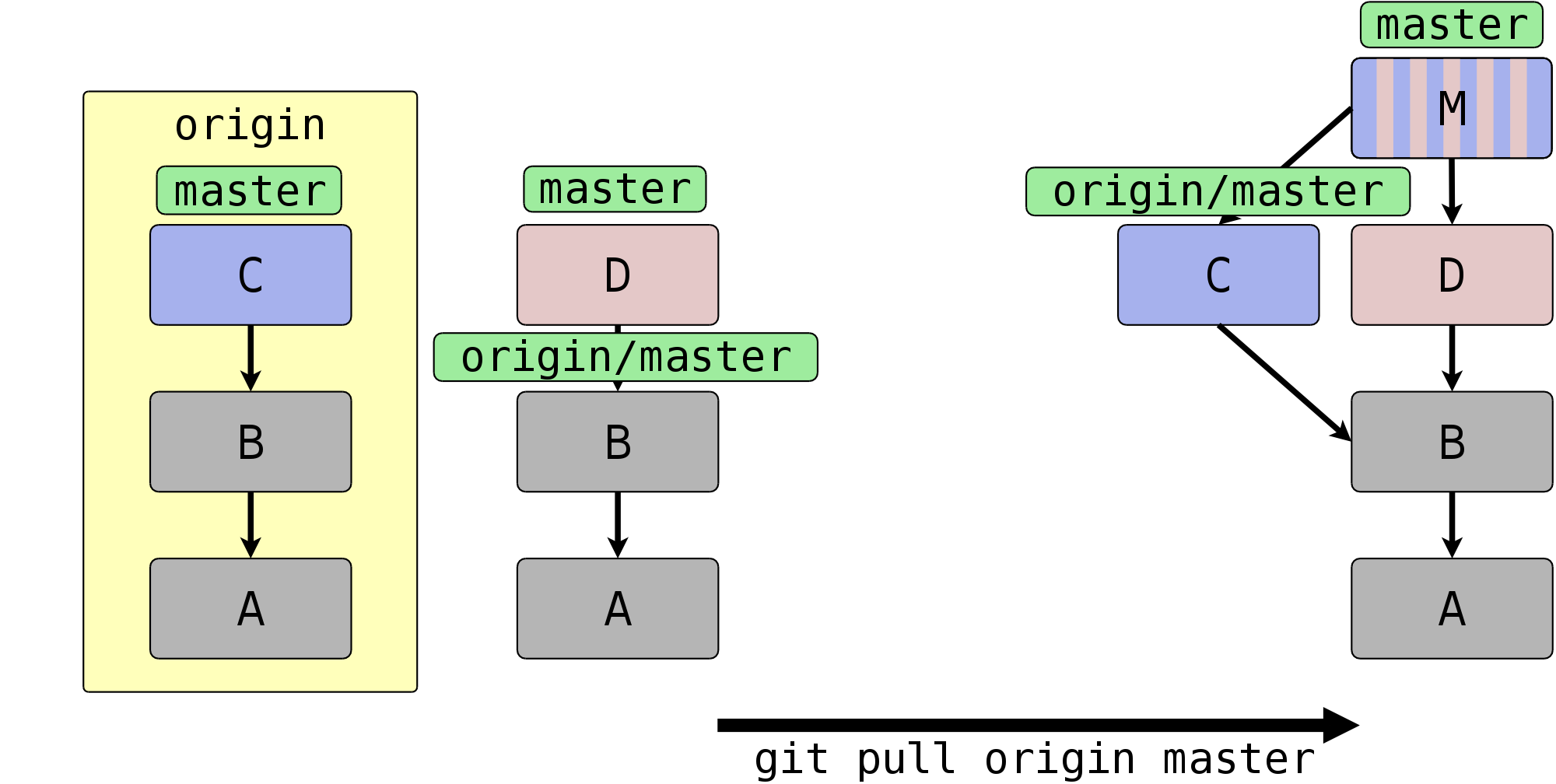
In Abbildung 5.5, „Was bei einem Pull passiert“ illustrieren wir den Vorgang. Auf
der linken Seite sehen Sie das Remote-Repository origin und
daneben den aktuellen Zustand des lokalen Repositorys. Das Repository
wurde geklont, als es nur die Commits A und B enthielt, daher zeigt
der Remote-Tracking-Branch origin/master auf B. Mittlerweile
sind sowohl im Remote (C) als auch im lokalen Repository (D) Commits
hinzugekommen.
Auf der rechten Seite ist der Zustand nach git
pull origin master abgebildet. Commit C wurde ins lokale
Repository übernommen. Der im pull enthaltene
fetch-Aufruf hat den Remote-Tracking-Branch aktualisiert,
d.h. er zeigt auf denselben Commit wie der master in
origin und spiegelt somit den dortigen Zustand wider.
Außerdem hat der im pull enthaltene merge-Aufruf den
master aus origin in den lokalen master
integriert, was Sie an dem Merge-Commit M sowie der
aktuellen Position des lokalen master erkennen.
Alternativ weist die Option --rebase das Pull-Kommando an, nach dem
fetch den lokalen Branch per Rebase auf den
Remote-Tracking-Branch aufzubauen:
$ git pull --rebase origin master
In Abbildung 5.6, „Was bei einem Pull mit Rebase passiert“ sehen Sie, was passiert, wenn Sie statt des Standard-Merge einen Rebase ausführen.
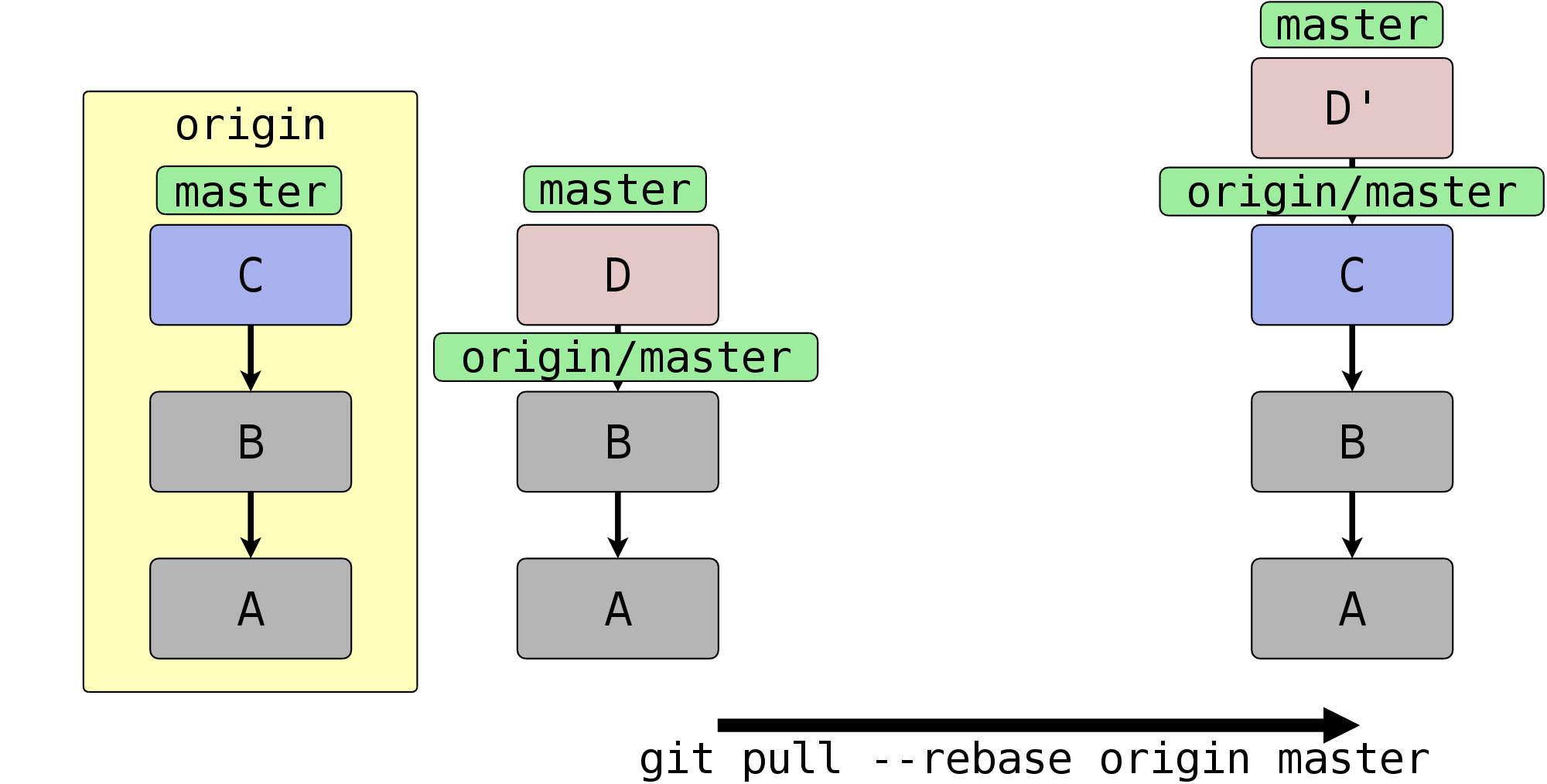
Die Ausgangssituation ist dieselbe wie in
Abbildung 5.5, „Was bei einem Pull passiert“. Der im pull enthaltene fetch
rückt den Remote-Tracking-Branch origin/master auf den Commit
C. Der rebase erzeugt jedoch keinen Merge-Commit; stattdessen
erhält der Commit D durch einen Aufruf von rebase eine neue
Basis, und der lokale master wird auf den neuen Commit D'
gesetzt. (Rebase wird ausführlich in Abschnitt 4.1, „Commits verschieben – Rebase“ beschrieben.)
Oft werden git fetch, git pull und git push ohne
Argumente ausgeführt. Git verwendet in dem Fall unter anderem die Konfiguration
der Upstream-Branches, um zu entscheiden, was zu tun ist. Aus der Config des
Repositorys:
[branch "master"]
remote = origin
merge = refs/heads/master
Der Eintrag besagt, dass der lokale Branch master mit dem
Remote-Branch master im origin-Repository verknüpft
ist.
Der Eintrag remote weist git fetch und git
pull an, von welchem Remote aus Commits heruntergeladen werden. Der
Eintrag merge wiederum weist git pull an, dass die
neuen Commits aus dem Remote-Branch master in den lokalen
master gemergt werden sollen. Das erlaubt es, beide Kommandos
ohne Argumente zu verwenden, was in der Praxis sehr häufig vorkommt.
$ git fetch ... From github.com:esc/git-cheatsheet-de 79170e8..003e3c7 master -> origin/master $ git pull ... From github.com:esc/git-cheatsheet-de 79170e8..003e3c7 master -> origin/master Updating 79170e8..003e3c7 Fast-forward cheatsheet.pdf | Bin 89792 -> 95619 bytes cheatsheet.tex | 19 ++++++++++++++++--- 2 files changed, 16 insertions(+), 3 deletions(-)
Wenn kein Upstream-Branch konfiguriert ist, versucht es git fetch mit
origin und bricht ansonsten ab:
$ git fetch
fatal: No remote repository specified. Please, specify either a URL or
a remote name from which new revisions should be fetched.
Tipp
Wenn Sie möchten, dass die Änderungen aus einem Upstream-Branch bei
git pull standardmäßig per Rebase statt mit einem Merge übernommen
werden, setzen Sie den Wert der Einstellung branch.<name>.rebase
auf true, z.B.:
$ git config branch.master.rebase true
Git-Anfängern stellt sich häufig die Frage, ob sie nun fetch
oder pull verwenden sollen. Die Antwort hängt davon ab, wie
entwickelt wird: Wie groß ist das Projekt? Wie viele Remotes gibt es?
Wie stark werden Branches eingesetzt?
Besonders für Anfänger ist es sinnvoll, dass alle Teilnehmer auf
demselben Branch arbeiten (meist master), sich mit demselben
Repository synchronisieren (zentraler Workflow) und nur git
pull zum Herunterladen bzw. git push zum Hochladen
verwenden. Das erübrigt die Auseinandersetzung mit komplexeren
Aspekten wie Objektmodell, Branching und Verteilung; und die Teilnehmer
können mit einigen wenigen Kommandos Verbesserungen beisteuern.
Es entsteht der folgende Arbeitsablauf:
# Repository Klonen $ git clone <URL> # Arbeiten und lokale Commits machen $ git add ... $ git commit # Veränderungen von Anderen herunterladen $ git pull # Eigene Veränderungen hochladen $ git push # Weiter arbeiten, und Synchronisation bei Bedarf wiederholen $ git commit
Dieser Ansatz hat Vor- und Nachteile. Von Vorteil ist sicherlich, dass
nur ein geringes Verständnis von Git notwendig ist, um dem
Arbeitsablauf erfolgreich zu folgen. Die automatische Konfiguration
der Upstream-Branches sorgt dafür, dass git push und
git pull auch ohne Argument das „Richtige“ tun.
Außerdem ähnelt dieser Workflow dem, was Umsteiger von Subversion
gewöhnt sind.
Allerdings gibt es auch Nachteile, die hauptsächlich mit dem
impliziten Merge zusammenhängen. Angenommen, das Team besteht aus zwei
Teilnehmern, Beatrice und Carlos. Beide haben lokale Commits gemacht,
und Beatrice hat ihre bereits hochgeladen. Carlos führt nun
git pull aus und erhält die Meldung Merge made by
recursive. Behält man den Commit-Graphen im Hinterkopf, ist das
logisch: Der lokale Branch und der master des Remote sind
auseinandergelaufen (diverged), darum wurden sie durch einen
Merge wieder vereint. Jedoch versteht Carlos die Meldung nicht, da er
ja an einem anderen Teil des Codes gearbeitet hat als seine Kollegin
und seines Erachtens kein Merge notwendig war. Ein Problem liegt
darin, dass der Term Merge bei vielen, die zentrale
Versionsverwaltung gewohnt sind, die Assoziation hat, Veränderungen
würden an derselben Datei zusammengeführt. Bei Git jedoch ist ein
Merge in jedem Fall als Zusammenführung von Commits in einem
Commit-Graphen zu verstehen. Dies kann das Zusammenführen von
Veränderungen an derselben Datei meinen, setzt das aber nicht voraus.
Neben der Verwirrung der Nutzer sorgt dieser Arbeitsablauf
für „unsinnige“ Commits in der Geschichte. Im Idealfall
sollen Merge-Commits ein sinnvoller Eintrag in der Geschichte sein.
Ein Außenstehender erkennt sofort, dass ein Entwicklungszweig
eingeflossen ist. Jedoch kommt bei diesem Arbeitsablauf zwangsläufig
hinzu, dass der lokale master und dessen Pendant im Remote
auseinanderlaufen und durch einen Merge wieder zusammengeführt werden.
Die dabei entstehenden Merge-Commits sind aber nicht sinnvoll – sie
sind eigentlich nur eine Nebenwirkung des Workflows und verringern die
Lesbarkeit der Geschichte. Zwar bietet die Option --rebase
für git pull Abhilfe, aber die Man-Page rät explizit vom
Einsatz der Option ab, sofern Sie nicht schon das Prinzip des Rebase
verinnerlicht haben. Haben Sie dieses verstanden, ist Ihnen auch die
Entstehung des Commit-Graphen vertraut und wie er zu manipulieren ist – dann lohnt es sich für Sie, als Workflow gleich die
featuregetriebene Entwicklung mit Branches anzustreben.
Sobald Sie das Objektmodell und den Commit-Graphen verstanden haben,
empfehlen wir Ihnen einen Workflow einzusetzen, der im Wesentlichen
aus git fetch, manuellen Merges und vielen Branches besteht.
Es folgen als Anregung einige Rezepte.
Sofern Sie master als Integrationsbranch verwenden, müssen
Sie nach einem Aufruf von git fetch Ihren lokalen
master vorrücken. Um genau zu sein, müssen Sie alle lokalen
Branches, die eine Entsprechung auf der Remote-Seite haben, vorrücken.
Git bietet dafür die Syntax @{upstream} bzw.
@{u} an, was dem für den aktuellen Branch konfigurierten
Remote-Tracking-Branch entspricht. Dies kann sehr hilfreich sein.
# Veränderungen von Anderen herunterladen $ git remote update ... 79170e8..003e3c7 master -> origin/master # Den Status der Remote-Tracking-Branches abfragen $ git branch -vv * master 79170e8 [origin/master: behind 1] Lizenz hinzugefügt # Veränderungen einsehen $ git log -p ..@{u} # Heruntergeladene Änderungen übernehmen $ git merge @{u} Updating 79170e8..003e3c7 Fast-forward ... # ... oder eigene Änderungen darauf neu aufbauen $ git rebase @{u} # Änderungen dann hochladen $ git push
Tipp
Wenn Sie häufiger lokale Branches mit Ihrem Remote-Tracking-Branch synchronisieren, empfehlen wir Ihnen folgendes Alias:
$ git config --global alias.fft "merge --ff-only @{u}"
Damit können Sie ganz bequem mit git fft
(Fast-Forward-Tracking) einen Branch vorrücken. Die Option
--ff-only verhindert, dass versehentlich Merge-Commits
entstehen, wo eigentlich keine hingehören.
Hilfreich ist in diesem Kontext auch Kapitel 6, Workflows, wo beschrieben wird, wie Sie übersichtlich mit vielen Topic-Branches arbeiten.
Das Gegenstück zu fetch und pull bildet das Kommando
git push. Damit laden Sie Git-Objekte und Referenzen in ein
Remote hoch – z.B. den lokalen master in den Branch
master im Remote origin:
$ git push origin master:master
Wie bei git fetch geben Sie die Referenzen zum Hochladen mit
einem Refspec an. Dieser hat jedoch die umgekehrte Form:
<lokale-refs>:<remote-refs>
Diesmal befinden sich die lokalen Referenzen auf der linken Seite des Doppelpunktes, und die Remote-Referenzen auf der rechten.
Lassen Sie den Doppelpunkt und die Remote-Referenz weg, wird der lokale Name auch auf der Remote-Seite verwendet und von Git erstellt, falls er nicht existiert:
$ git push origin master
Counting objects: 73, done.
Compressing objects: 100% (33/33), done.
Writing objects: 100% (73/73), 116.22 KiB, done.
Total 73 (delta 42), reused 68 (delta 40)
Unpacking objects: 100% (73/73), done.
To git@github.com:esc/git-cheatsheet-de.git
* [new branch] master -> master
Den Vorgang hinter git push zeigt
Abbildung 5.7, „Referenzen und Commits hochladen“. Die Ausgangssituation sehen Sie auf
der linken Seite (es ist das Ergebnis eines pull-Aufrufes).
Die fehlenden Commits D und M lädt Git in das Remote origin
hoch. Gleichzeitig wird der Remote-Branch master auf den
Commit M vorgerückt, so dass dieser dem lokalen Branch master
entspricht. Außerdem wird der Remote-Tracking-Branch
origin/master vorgerückt, damit er den aktuellen Zustand im
Remote widerspiegelt.
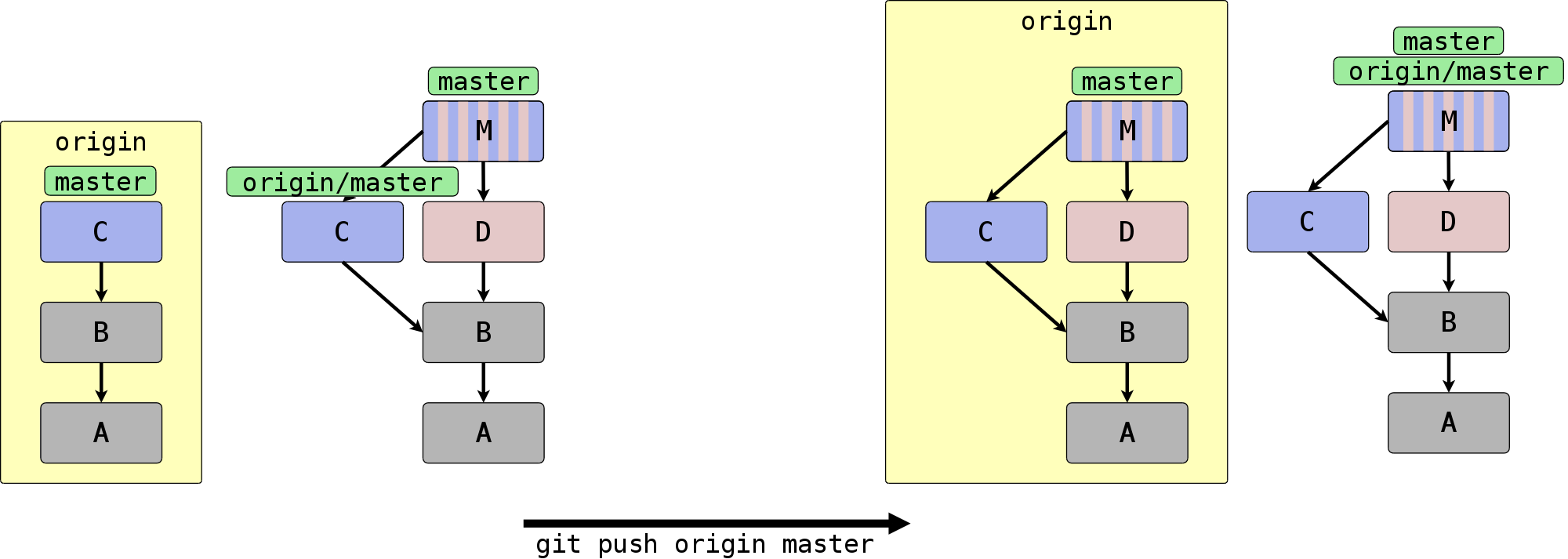
Analog zu fetch weigert sich Git, Referenzen zu aktualisieren,
bei denen der Ziel-Commit kein Nachfahre des aktuellen Commits ist:
$ git push origin master
...
! [rejected] master -> master (non-fast-forward)
error: failed to push some refs to 'git@github.com:esc/git-cheatsheet-de.git'
To prevent you from losing history, non-fast-forward updates were
rejected
Merge the remote changes before pushing again. See the 'Note about
fast-forwards' section of 'git push --help' for details.
Dieses Verhalten setzen Sie entweder durch ein vorangestelltes Plus
(+) im Refspec oder durch die Option --force bzw.
kurz -f außer Kraft:[72]
$ git push origin --force master $ git push origin +master
Vorsicht! Es können Commits auf der Remote-Seite verloren gehen – zum
Beispiel wenn sie per git reset --hard einen Branch
verschoben haben und Commits nicht mehr referenziert werden.
Sie erhalten die Fehlermeldung auch, wenn Sie Commits, die bereits per
git push veröffentlicht wurden, nachträglich mit git
rebase oder git commit --amend modifiziert haben. Daher
hier noch einmal die ausdrückliche Warnung: Vermeiden Sie es, Commits,
die Sie bereits veröffentlicht haben, nachträglich zu verändern!
Durch die veränderten SHA-1-Summen kommt es zu Doppelungen, wenn
Andere die ursprünglichen Commits bereits heruntergeladen haben.
Es gibt zwei Möglichkeiten, um Referenzen im Remote wieder zu löschen: Die ältere (vor Git Version 1.7.0) ist, beim Refspec die lokale Referenz wegzulassen – diese Anweisung bedeutet, Sie möchten „nichts“ hochladen. Sie ersetzen also eine existierende durch die leere Referenz.
$ git push origin :bugfix
In neueren Git-Versionen wird aber in der Regel das Kommando git
push mit der Option --delete verwendet, was syntaktisch viel
deutlicher ist:
$ git push origin --delete bugfix
Beachten Sie, dass in anderen Klonen der ggf. vorhandene
Remote-Tracking-Branch origin/bugfix dadurch nicht automatisch verschwindet!
Siehe dafür den Abschnitt über Pruning weiter oben (Abschnitt 5.3, „Commits herunterladen“).
Im Alltag führen Sie git push oft ohne Angabe von Remote und Refspec
aus. In dem Fall entscheidet Git anhand der Konfigurationseinträge
(Upstream-Branch und push.default), welche Referenzen wohin geschickt
werden.
$ git push
...
To git@github.com:esc/git-cheatsheet-de.git
79170e8..003e3c7 master -> master
Git geht standardmäßig so vor:[73]
Wenn Sie kein Remote angeben, dann sucht Git die Upstream-Konfiguration
des aktuellen Branches heraus. Sofern der Name des Branches auf der
Remote-Seite mit dem Namen des lokalen Branches übereinstimmt, wird die
entsprechende Referenz hochgeladen (dies soll Sie davor schützen, bei
fehlerhafter Upstream-Konfiguration zum Beispiel Ihren Branch devel nach
master hochzuladen). Ist kein Upstream-Branch konfiguriert, bricht Git
mit einer Fehlermeldung ab:
$ git push
fatal: The current branch master has no upstream branch.
To push the current branch and set the remote as upstream, use
git push --set-upstream origin master
Wenn Sie mit git push <remote> zwar ein Remote, aber keinen Branch
angeben, so versucht Git, den aktuellen Branch unter dem gleichen Namen
in das Remote hochzuladen.
Die hier beschriebene Strategie wird auch als simple bezeichnet. Sie
tut für die meisten Anwendungsfälle das, was der Nutzer erwartet, und
schützt vor vermeidbaren Fehlern. Die dafür zuständige Option
push.default können Sie aber bei Bedarf auch auf einen der folgenden
Werte setzen:
-
nothing - Nichts hochladen. Dies ist sinnvoll, wenn Sie immer explizit angeben wollen, welchen Branch Sie wohin hochladen wollen.
-
upstream - Wenn der aktuelle Branch einen Upstream-Branch hat, dorthin pushen.
-
current - Den aktuellen Branch in einen Remote-Branch gleichen Namens pushen.
-
matching - Lädt alle lokal existierenden Referenzen hoch, für die es im entsprechenden Remote bereits eine Referenz gleichen Namens gibt. Achtung: Sie laden dadurch potentiell mehrere Branches gleichzeitig hoch!
Git nimmt die Konfiguration von Upstream-Branches in einigen Fällen
automatisch vor (zum Beispiel nach einem git clone). Insbesondere für
neue Branches, die Sie das erste Mal hochladen, müssen Sie dies
allerdings explizit tun.
Sie können dafür entweder im Nachhinein die Option --set-upstream-to
oder kurz -u von git branch verwenden:
$ git push origin new-feature $ git branch -u origin/new-feature Branch new-feature set up to track remote branch new-feature from origin.
Alternativ und wenn Sie daran denken, können Sie aber auch gleich beim
Aufruf von git push mit der Option -u die Konfiguration schreiben
lassen:
$ git push -u origin new-feature
Um die Upstream-Konfiguration Ihrer Branches anzuzeigen, rufen Sie git
branch -vv auf. In der Ausgabe wird (falls vorhanden) der
Upstream-Partner eines Branches in eckigen Klammern angezeigt.
In diesem Abschnitt stellen wir Techniken vor, mit denen Sie ein Remote einsehen und Ihr lokales Repository damit vergleichen.
Das Kommando git remote show gibt eine prägnante
Zusammenfassung des Remotes, inklusive den dort verfügbaren Branches,
ob diese lokal verfolgt werden (Tracking-Status) und welche lokalen
Branches für bestimmte Aufgaben konfiguriert sind.
Das Kommando muss beim Remote den aktuellen Stand erfragen,
d.h. der Befehl scheitert, wenn das Remote nicht verfügbar ist,
z.B. aufgrund fehlender Netzwerkverbindung. Die Option -n
unterbindet die Abfrage.
$ git remote show origin
* remote origin
Fetch URL: git://git.kernel.org/pub/scm/git/git.git
Push URL: git://git.kernel.org/pub/scm/git/git.git
HEAD branch: master
Remote branches:
html tracked
maint tracked
man tracked
master tracked
next tracked
pu tracked
todo tracked
Local branches configured for 'git pull':
master merges with remote master
pu merges with remote pu
Local refs configured for 'git push':
master pushes to master (local out of date)
pu pushes to pu (up to date)
Haben Sie einen Upstream-Branch konfiguriert, erhalten Sie beim
Wechseln des Branches (git checkout) und Abfragen des Status
(git status) eine Benachrichtigung über den Zustand des
Branches im Vergleich mit dem Upstream, z.B.:
$ git checkout master
Your branch is behind 'origin/master' by 73 commits, and can be
fast-forwarded.
Hier gibt es vier verschiedene Möglichkeiten:
- Die Branches zeigen auf denselben Commit. Git zeigt keine besondere Nachricht an. Dieser Zustand heißt auch up-to-date.
-
Der lokale Branch hat Commits, die noch nicht im Upstream verfügbar sind:
Your branch is ahead of 'origin/master' by 16 commits. -
Der Remote-Tracking-Branch hat Commits, die in dem lokalen Branch noch nicht verfügbar sind:
Your branch is behind 'origin/master' by 73 commits, and can be fast-forwarded. -
Sowohl die zweite als auch die dritte Bedingung treffen zu, ein Zustand der im Git-Jargon als diverged bezeichnet wird:
Your branch and 'origin/master' have diverged, and have 16 and 73 different commit(s) each, respectively.
Mit der Option -v (nur den Vergleich) oder -vv
(Vergleich und Upstream-Bezeichnung) zeigt git branch die
entsprechenden Informationen für lokale Branches:
$ git branch -vv * master 0a464e9 [origin/master: ahead 1] docs: fix grammar in git-tags.txt feature cd3065f Merge branch 'kc/gitweb-pathinfo-w-anchor' next be8b495 [origin/next] Merge branch master into next pu 0c0c536 [origin/pu: behind 3] Merge branch 'jk/maint-merge-rename-create' into pu
Das Kommando gibt für alle Branches das SHA-1-Präfix sowie die
Commit-Message des aktuellen Commits aus. Ist für den Branch ein
Upstream konfiguriert, liefert Git sowohl den Namen als auch einen
Vergleich zum Upstream. In dem Beispiel sehen Sie vier verschiedene
Branches. master hat einen zusätzlichen Commit, der noch
nicht ins Remote hochgeladen wurde, und ist daher ahead. Der
Branch feature wiederum hat keinen Upstream-Branch
konfiguriert, ergo: er existiert momentan nur lokal. Der Branch
next ist auf demselben Stand wie der entsprechende
Remote-Tracking-Branch (up-to-date). Der Branch pu
andererseits „hinkt“ seinem Upstream hinterher und wird
daher als behind angezeigt. Der einzige Zustand, der hier fehlt,
ist diverged – dann werden sowohl ahead als auch
behind inklusive der Anzahl der „fehlenden“ Commits
angezeigt.
Git unterstützt das Arbeiten mit mehreren Remotes. Ein beliebter Workflow, der sich diese Eigenschaft zu Nutze macht, ist der Integration-Manager Workflow. Hier gibt es kein „zentrales“ Repository im eigentlichen Sinne, das heißt eines, auf das alle aktiven Entwickler Schreibzugriff haben. Stattdessen gibt es nur ein quasi-offizielles Repository, das blessed („gesegnet“) genannt wird. Es ist beispielsweise über die jeweilige Projekt-Domain erreichbar und erlaubt nur den wichtigsten Maintainern (oder gar nur einem) Schreibzugriff.
Jeder, der zu dem Projekt beitragen will, klont das Blessed Repository und beginnt mit der Arbeit. Sobald er Fehler behoben oder ein neues Feature implementiert hat, stellt er seine Verbesserungen über ein öffentlich zugängliches Repository, einem sog. Developer-Public, zur Verfügung. Danach sendet er an einen der Maintainer des offiziellen Repositorys (oder an die Mailingliste) einen sog. Pull-Request, also die Aufforderung, gewissen Code aus seinem öffentlichen Repository in das offizielle Repository zu übernehmen. Die Infrastruktur für diesen Ablauf sehen Sie in Abbildung 5.8, „Integration-Manager Workflow“. Es ist zwar theoretisch möglich, Interessenten direkten Zugriff auf die eigene Entwicklungsmaschine zu geben, das geschieht in der Praxis aber beinahe nie.
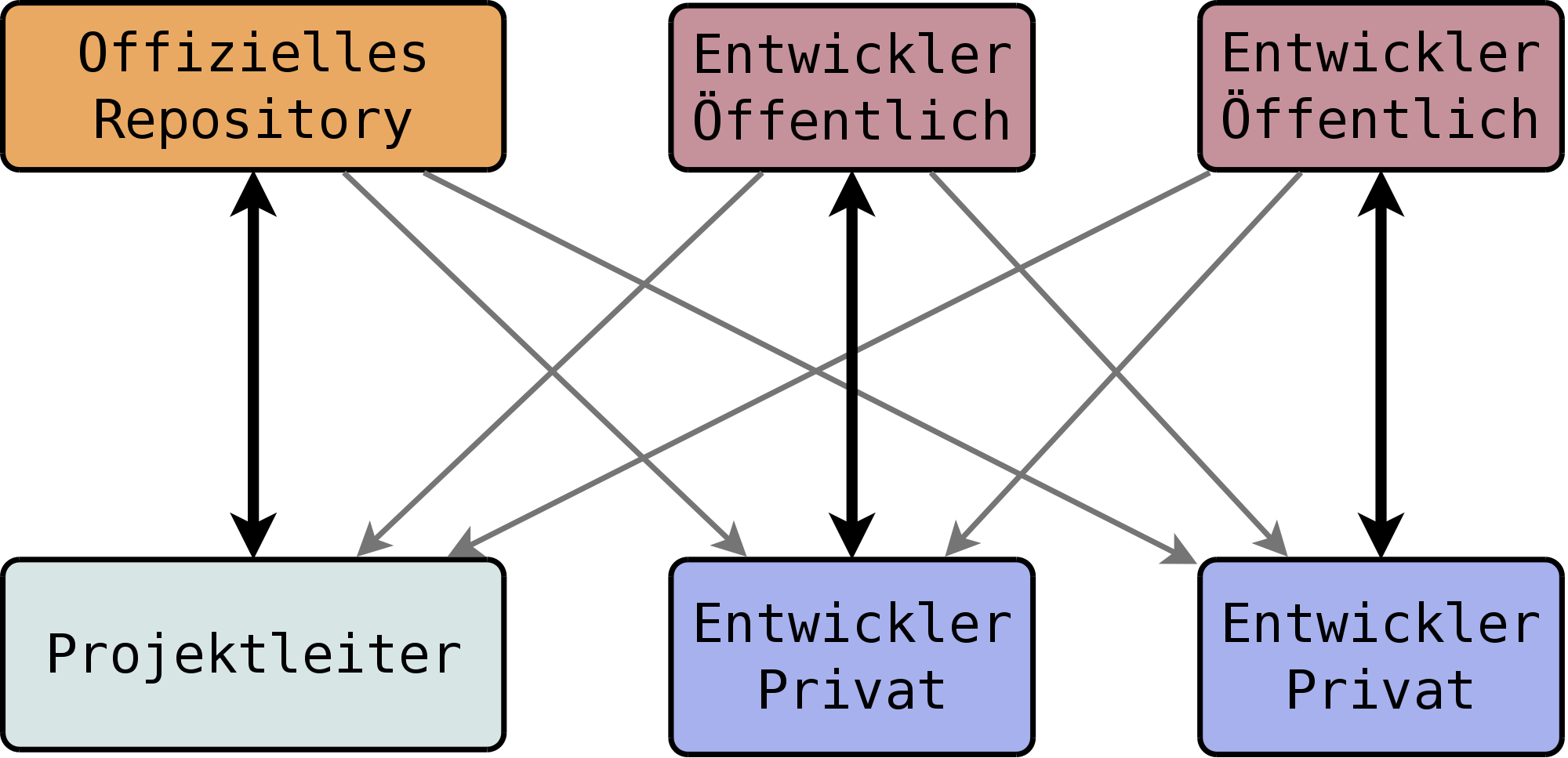
Einer der Maintainer, die Zugriff auf das Haupt-Repository haben, überprüft dann, ob der Code funktioniert, ob er den Qualitätsanforderungen entspricht usw. Eventuelle Fehler oder Unklarheiten teilt er dem Autor des Codes mit, der diese dann wiederum in seinem Repository korrigiert. Erst wenn der Maintainer zufrieden ist, übernimmt er die Änderungen in das Haupt-Repository, so dass der Code in einem der folgenden Releases mitgeliefert wird. Maintainer, die neuen Code eingliedern, werden oft als Integration Manager bezeichnet, was dem Workflow seinen Namen gegeben hat. Oft haben solche Maintainer mehrere Remotes konfiguriert, eines für jeden Mitwirkenden.
Einer der großen Vorteile dieses Workflows ist, dass außer den Maintainern auch interessierte User Zugriff auf die öffentlichen Entwickler-Repositories haben, etwa Kollegen oder Freunde des Entwicklers. Diese müssen nicht warten, bis der Code seinen Weg in das offizielle Repository gefunden hat, sondern können direkt nach der Bereitstellung die Verbesserungen ausprobieren. Insbesondere die Hosting-Plattform Github setzt sehr stark auf diesen Workflow. Die dort eingesetzte Weboberfläche bietet eine Vielzahl von Features, um diesen Workflow zu unterstützen, z.B. eine Visualisierung, die alle verfügbaren Klons eines Projekts und die darin enthaltenen Commits anzeigt, sowie die Möglichkeit, Merges direkt im Webinterface durchzuführen. Eine ausführliche Beschreibung dieses Dienstes finden Sie in Kapitel 11, Github.
Mit git remote verwalten Sie zusätzliche Remotes. Um
z.B. ein neues Remote eines anderen Entwicklers hinzuzufügen,
verwenden Sie das Kommando git remote add. Meist wollen
Sie im Anschluss die Remote-Tracking-Branches initialisieren, was Sie
mit git fetch erreichen:
$ git remote add example git://example.com/example.git $ git fetch example ...
Tipp
Um beide Arbeitsschritte in einem Aufruf zu erledigen, verwenden
Sie die Option -f, für fetch:
$ git remote add -f example git://example.com/example.git
Brauchen Sie das Remote nicht mehr, können Sie es mit
git remote rm aus Ihrer lokalen Konfiguration wieder
entfernen. Dadurch werden auch alle Remote-Tracking-Branches für
dieses Remote wieder gelöscht:
$ git remote rm example
Remotes müssen nicht zwingend per git remote add konfiguriert
werden. Sie können einfach die URL auf der Kommandozeile
verwenden,[74] zum Beispiel, um die
Objekte und Referenzen für einen Bugfix herunterzuladen:
$ git fetch git://example.com/example.git bugfix:bugfix
Selbstverständlich geht das auch mit pull und push.
Arbeiten Sie mit mehreren Remotes, bietet sich das Kommando
git remote update --prune an. Damit führen Sie
fetch für alle Remotes durch, wobei die Option
--prune dafür sorgt, dass alle abgelaufenen
Remote-Tracking-Branches gelöscht werden.
Tipp
Folgendes Alias hat sich bei uns sehr bewährt, da es viele Arbeitsschritte, die in der Praxis oft hintereinander ausgeführt werden, vereint:
$ git config --global alias.ru "remote update --prune"
Um einen Pull-Request automatisch zu generieren, gibt es das
Git-Kommando request-pull. Die Syntax lautet:
git request-pull <Anfang> <URL> [<Ende>]
Als <URL> geben Sie Ihr öffentliches Repository an (entweder als
tatsächliche URL oder als konfiguriertes Remote-Repository), und als
<Anfang> wählen Sie die Referenz, auf die das Feature aufbaut (in
vielen Fällen den Branch master, der mit dem Master-Branch des
offiziellen Repositorys übereinstimmen sollte). Optional können Sie ein
<Ende> angeben; lassen Sie diese Angabe weg, so verwendet Git
HEAD.
Die Ausgabe erfolgt nach Standard-Out und enthält die URL sowie den
Branch-Namen des Repositorys, die Kurzbeschreibung aller Commits nach
Autor sowie ein Diff-Stat, also eine Bilanz von hinzugekommenen und
gelöschten Zeilen nach Dateien. Diese Ausgabe lässt sich bequem an
ein E-Mail-Programm weiterleiten. Fügen Sie noch die Option
-p hinzu, wird unter den Text noch ein Patch mit allen
Änderungen angehängt.
Zum Beispiel um jemanden darum zu bitten, die zwei neuesten Commits aus einem Repository herunterzuladen:
$ git request-pull HEAD~2 origin
The following changes since commit d2640ac6a1a552781[...]c48e08e695d53:
README verbessert (2010-11-20 21:27:20 0100)
are available in the git repository at:
git@github.com:esc/git-cheatsheet-de.git master
Valentin Haenel (2):
Lizenz hinzugefügt
URL hinzugefügt und Metadaten neu formatiert
cheatsheet.pdf | Bin 89513 -> 95619 bytes
cheatsheet.tex | 18 ++++++++++++++++--
2 files changed, 16 insertions(), 2 deletions(-)
Tags werden ebenfalls mit den Remote-Kommandos fetch bzw.
pull und push ausgetauscht. Im Gegensatz zu
Branches, die sich verändern, sind Tags jedoch „statisch“.
Aus diesem Grund werden Remote-Tags nicht noch einmal zusätzlich lokal
referenziert, es gibt also kein Äquivalent zu den
Remote-Tracking-Branches für die Tags. Tags, die Sie aus Ihren
Remote-Repositories erhalten, speichert Git ganz normal unter
.git/refs/tags/ bzw. .git/packed-refs.
Prinzipiell lädt Git neue Tags automatisch bei einem Aufruf von
git fetch bzw. git pull herunter. Das heißt, wenn
Sie einen Commit herunterladen, auf den ein Tag zeigt, so wird dieses
Tag mitgeliefert. Schließen Sie jedoch mit einem Refspec einzelne
Branches aus, so werden Commits in diesen Branches nicht
heruntergeladen – und somit auch keine Tags, die evtl. auf diese
Commits zeigen. Fazit: Git lädt nur relevante Tags herunter. Mit den
Optionen --no-tags (keine Tags) und --tags
bzw. -t (alle Tags) passen Sie das Standardverhalten an.
Beachten Sie aber, dass Sie mit --tags nicht nur die Tags
herunterladen, sondern notwendigerweise auch die Commits, auf die die
Tags zeigen.
Git benachrichtigt Sie, wenn neue Tags eintreffen:
$ git fetch
[fetch output]
From git://git.kernel.org/pub/scm/git/git
* [new tag] v1.7.4.2 -> v1.7.4.2
Wenn Sie wissen wollen, welche Tags auf der Remote-Seite vorhanden
sind, verwenden Sie git ls-remote mit der Option
--tags. Zum Beispiel erhalten Sie alle Release-Candidates der
Git-Version 1.7.1 mit folgendem Aufruf:
$ git ls-remote origin --tags v1.7.1-rc*
bdf533f9b47dc58ac452a4cc92c81dc0b2f5304f refs/tags/v1.7.1-rc0
537f6c7fb40257776a513128043112ea43b5cdb8 refs/tags/v1.7.1-rc0^{}
d34cb027c31d8a80c5dbbf74272ecd07001952e6 refs/tags/v1.7.1-rc1
b9aa901856cee7ad16737343f6a372bb37871258 refs/tags/v1.7.1-rc1^{}
03c5bd5315930d8d88d0c6b521e998041a13bb26 refs/tags/v1.7.1-rc2
5469e2dab133a197dc2ca2fa47eb9e846ac19b66 refs/tags/v1.7.1-rc2^{}
Git gibt die SHA-1-Summen der Tags und deren Inhalt[75] aus.
Git lädt Tags nicht automatisch hoch. Sie müssen diese, ähnlich den
Branches, explizit an git push übergeben, z.B. um das Tag
v0.1 hochzuladen:
$ git push origin v0.1
Wenn Sie gleich alle Tags hochladen wollen, verwenden Sie die Option
--tags. Aber Vorsicht: Vermeiden Sie diese Option, wenn Sie,
wie in Abschnitt 3.1.3, „Tags – Wichtige Versionen markieren“ beschrieben,
Annotated Tags zur Kennzeichnung von Versionen verwenden und
Lightweight Tags, um lokal etwas zu markieren. Denn mit der Option
würden Sie, wie schon gesagt, alle Tags hochladen.
Achtung: Wenn Sie ein Tag einmal hochgeladen haben, sollten Sie es auf
keinen Fall verändern! Der Grund: Angenommen, Axel verändert ein Tag,
etwa v0.7, das er bereits veröffentlicht hat. Zunächst zeigte
es auf den Commit 5b6eef und nun auf bab18e.
Beatrice hatte bereits die erste Version, die auf 5b6eef
zeigt, heruntergeladen, Carlos aber noch nicht. Beim nächsten Mal,
wenn Beatrice git pull aufruft, lädt Git nicht die
neue Version von dem Tag v0.7 herunter; die Annahme ist, dass
sich Tags nicht verändern, und darum überprüft Git die Gültigkeit des
Tags nicht! Führt Carlos nun git pull aus, erhält er auch
das Tag v0.7, das aber jetzt auf bab18e zeigt.
Zuletzt sind zwei Versionen des Tags – die jeweils auf
unterschiedliche Commits zeigen – im Umlauf. Keine besonders
hilfreiche Situation. Wirklich verwirrend wird es, wenn sowohl Carlos
als auch Beatrice dasselbe, öffentliche Repository verwenden und
standardmäßig alle Tags hochladen.[76] Das Tag
„springt“ quasi im öffentlichen Repository zwischen zwei
Commits hin und her; welche Version Sie mit einem Klon erhalten, hängt
davon ab, wer zuletzt gepusht hat.
Sollte Ihnen dieses Missgeschick doch einmal passieren, haben Sie zwei Möglichkeiten:
-
Die vernünftige Alternative: Statt das Tag zu ersetzen, erstellen Sie
ein neues und laden es ebenfalls hoch. Benennen Sie das neue Tag
entsprechend den Projektkonventionen. Heißt das alte
v0.7, nennen Sie das neue etwav0.7.1. - Wenn Sie das Tag wirklich ersetzen wollen: Geben Sie öffentlich zu (Mailingliste, Wiki, Blog), dass Sie einen Fehler gemacht haben. Weisen Sie alle Entwickler und Nutzer darauf hin, dass sich ein Tag geändert hat, und bitten Sie darum, dass jeder dieses Tag bei sich überprüft. Die Größe des Projekts und Ihre Risikobereitschaft entscheiden, ob diese Lösung machbar ist.
Eine Alternative zum Einrichten eines öffentlichen Repositorys ist es, automatisch Patches per E-Mail zu verschicken. Das Format der E-Mail wird dabei so gewählt, dass die Maintainer die per E-Mail empfangenen Patches automatisch von Git einspielen lassen können. Gerade für kleine Fehlerkorrekturen und sporadische Mitarbeit ist das meist weniger aufwändig und schneller. Es gibt viele Projekte, die auf diese Art des Austauschs setzen, allen voran das Git-Projekt selbst.
Der Großteil der Patches für Git wird über die Mailingliste beigesteuert. Dort
durchlaufen sie einen stringenten Review-Prozess, der meistens zu Korrekturen
und Verbesserungen führt. Die Patches werden vom Autor so lange verbessert und
erneut an die Liste geschickt, bis ein Konsens erreicht ist. Währenddessen
speichert der Maintainer die Patches regelmäßig in einem Branch in seinem
Repository, und stellt sie über den pu-Branch zum Testen bereit. Sofern
die Patch-Serie von den Teilnehmern auf der Liste als fertig betrachtet wird,
wandert der Branch über die verschiedenen Integrations-Branches pu und
next, wo die Veränderungen auf Kompatibilität und Stabilität geprüft
werden. Ist alles in Ordnung, landet der Branch schließlich im master
und bildet von dort aus einen Teil des nächsten Releases.
Der Ansatz Patches per E-Mail wird durch folgende Git-Kommandos realisiert:
-
git format-patch - Commits zum Verschicken als Patches formatieren.
-
git send-email - Patches verschicken.
-
git am - Patches aus einer Mailbox in den aktuellen Branch einpflegen (apply from mailbox).
Das Kommando git format-patch exportiert einen oder mehrere
Commits als Patches im Unix-Mailbox-Format und gibt pro Commit eine
Datei aus. Die Dateinamen bestehen aus einer sequenziellen
Nummerierung und der Commit-Message und enden auf
.patch.[77] Als Argument erwartet das
Kommando entweder einen einzelnen Commit oder eine Auswahl wie
z.B. A..B. Geben Sie einen einzelnen Commit an, wertet Git dies als
die Auswahl von dem Commit bis zum HEAD.

Abbildung 5.9, „Drei Commits nach master als Patches formatieren“ zeigt die
Ausgangssituation. Wir wollen die drei Commits in dem Branch
fix-git-svn-docs, also alle Commits ab master, als
Patches exportieren:
$ git format-patch master
0001-git-svn.txt-fix-usage-of-add-author-from.patch
0002-git-svn.txt-move-option-descriptions.patch
0003-git-svn.txt-small-typeface-improvements.patch
Tipp
Um nur den HEAD zu exportieren, verwenden Sie die Option
-1. Dann erzeugt format-patch nur für den ersten
Commit einen Patch:
$ git format-patch -1
0001-git-svn.txt-small-typeface-improvements.patch
Das geht auch für beliebige SHA-1-Summen:
$ git format-patch -1 9126ce7
0001-git-svn.txt-fix-usage-of-add-author-from.patch
Die generierten Dateien enthalten unter anderem die Header-Felder
From, Date und Subject, die zum Verschicken
als E-Mail dienen. Diese Felder werden anhand der im Commit
vorhandenen Information – Autor, Datum und Commit-Message – vervollständigt. Des weiteren enthalten die Dateien eine
Diff-Stat-Zusammenfassung sowie die Veränderungen selbst als Patch im
Unified-Diff-Format. Den Zusatz [PATCH m/n][78] in der
Betreff-Zeile nutzt Git später, um die Patches in der richtigen
Reihenfolge anzuwenden.
Es folgt ein entsprechender Ausschnitt:
$ cat 0003-git-svn.txt-small-typeface-improvements.patch
From 6cf93e4dae1e5146242338b1b9297e6d2d8a08f4 Mon Sep 17 00:00:00 2001
From: Valentin Haenel <valentin.haenel@gmx.de>
Date: Fri, 22 Apr 2011 18:18:55 0200
Subject: [PATCH 3/3] git-svn.txt: small typeface improvements
Signed-off-by: Valentin Haenel <valentin.haenel@gmx.de>
Acked-by: Eric Wong <normalperson@yhbt.net>
---
Documentation/git-svn.txt | 8 ++++----
1 files changed, 4 insertions(), 4 deletions(-)
diff --git a/Documentation/git-svn.txt b/Documentation/git-svn.txt
...
Wenn Sie vorhaben, eine Serie von Patches zu verschicken, ist
es empfehlenswert, mit der Option --cover-letter eine Art
„Deckblatt“ zu erzeugen, in dem Sie die Serie beschreiben.
Die Datei heißt standardmäßig 0000-cover-letter.patch.
Abgesehen von den Standard-Headern, sieht eine solche Datei wie folgt aus:
Subject: [PATCH 0/3] *** SUBJECT HERE *** *** BLURB HERE *** Valentin Haenel (3): git-svn.txt: fix usage of --add-author-from git-svn.txt: move option descriptions git-svn.txt: small typeface improvements Documentation/git-svn.txt | 22 +++++++++++----------- 1 files changed, 11 insertions(+), 11 deletions(-)
Wie Sie sehen, ist im Subject: noch das Präfix [PATCH
0/3] eingetragen; so sehen alle Empfänger sofort, dass es sich
um ein Deckblatt handelt. Außerdem enthält die Datei die Ausgabe von
git shortlog sowie git diff --stat. Ersetzen Sie
*** SUBJECT HERE *** durch einen Betreff und *** BLURB
HERE *** durch eine Zusammenfassung der Patch-Serie. Verschicken
Sie die Datei zusammen mit den Patch-Dateien.
Tipp
Häufig werden Mailing-Listen, auf die Patches geschickt werden, dazu verwendet, die Patches inhaltlich und syntaktisch zu kritisieren und den Autor um Verbesserung zu bitten. Hat der Autor die Verbesserungen vorgenommen, schickt er die korrigierte Serie als Reroll erneut an die Liste. Je nach Größe der Patch-Serie und Anforderungen des Projektes kann eine Patch-Serie durchaus mehrere Rerolls durchlaufen, bis sie angenommen wird.
Wenn Sie eine Patch-Serie an eine Mailing-Liste schicken: Halten Sie die
Commits auf einem eigenen Branch vor, und arbeiten Sie die
Korrekturen in neuen Commits (bei fehlender Funktionalität) oder mit
interaktivem Rebase (zum Anpassen bestehender Commits) ein. Verwenden
Sie anschließend das Kommando git format-patch mit der Option
--reroll-count=<n> (oder kurz -v <n>): Sie erzeugen so Patches,
die als Subject-Zeile z.B. [PATCH v2] tragen und machen so deutlich,
dass es sich um den ersten Reroll dieser Serie handelt.
Versenden Sie die generierten Dateien mit git send-email
(oder einem E-Mail-Client Ihrer Wahl). Das Kommando erwartet als
einziges zwingendes Argument entweder eine oder mehrere Patch-Dateien,
ein Verzeichnis voller Patches oder aber eine Auswahl von Commits (in
dem Fall ruft Git zusätzlich intern git format-patch auf):
$ git send-email 000* 0000-cover-letter.patch 0001-git-svn.txt-fix-usage-of-add-author-from.patch 0002-git-svn.txt-move-option-descriptions.patch 0003-git-svn.txt-small-typeface-improvements.patch Who should the emails appear to be from? [Valentin Haenel <valentin.haenel@gmx.de>] $ git send-email master /tmp/HMSotqIfnB/0001-git-svn.txt-fix-usage-of-add-author-from.patch /tmp/HMSotqIfnB/0002-git-svn.txt-move-option-descriptions.patch /tmp/HMSotqIfnB/0003-git-svn.txt-small-typeface-improvements.patch Who should the emails appear to be from? [Valentin Haenel <valentin.haenel@gmx.de>]
Das Kommando git send-email setzt die Felder
Message-Id sowie In-Reply-To. Damit sehen alle
E-Mails nach der ersten wie Antworten auf diese aus und werden dadurch
von den meisten Mail-Programmen als zusammenhängender Thread
angezeigt:[79]

Das Kommando können Sie über Optionen – beispielsweise --to, --from und --cc – anpassen (siehe die Man-Page git-send-email(1)). Die
unbedingt benötigten Angaben werden aber, sofern nicht angegeben,
interaktiv abgefragt – vor allem wird eine Adresse benötigt, an die
die Patches geschickt werden sollen.[80]
Bevor die E-Mails tatsächlich versendet werden,
wird Ihnen der Header nochmals angezeigt; Sie sollten überprüfen, ob
alles Ihren Wünschen entspricht, und anschließend die Frage
Send this email? ([y]es|[n]o|[q]uit|[a]ll): mit y
für „yes“ beantworten. Um sich mit dem Kommando vertraut zu
machen, kann man zunächst alle E-Mails nur an sich selbst schicken
oder die Option --dry-run verwenden.
Tipp
Alternativ zu git send-email können Sie den Inhalt der
Dateien in einen der vielen online Pastebin-Dienste, zum
Beispiel
dpaste[81]
oder
gist.github[82]
einwerfen und den Verweis darauf per IRC oder Jabber verschicken.
Zum Einpflegen lädt sich der Empfänger den Inhalt in eine Datei
herunter und übergibt diese an git am (s.u.).
Wenn Sie Ihren bevorzugten Mail User Agent (MUA) (z.B. Thunderbird, Kmail o.a.) verwenden wollen, um Patches zu verschicken, gibt es eventuell einiges zu beachten. Manche MUAs sind berüchtigt, Patches so zu verstümmeln, dass sie Git nicht mehr als solche erkennt.[83]
Mit git format-patch exportierte Patch-E-Mails werden von dem
Git-Kommando git am (apply from mailbox) wieder in
Commits zurückübersetzt. Aus jeder E-Mail wird ein neuer Commit
erzeugt, dessen Meta-Informationen (Autor, Commit-Message usw.) aus
den Header-Zeilen der E-Mail (From, Date) generiert
werden. Wie schon erwähnt, erkennt Git an der Nummer im Subject, in
welcher Reihenfolge die Commits einzupflegen sind. Um das Beispiel
von vorhin zu vollenden: Befinden sich die E-Mails im
Maildir-Verzeichnis patches, dann reicht:
$ git am patches
Applying: git-svn.txt: fix usage of --add-author-from
Applying: git-svn.txt: move option descriptions
Applying: git-svn.txt: small typeface improvements
Tipp
Das Kommando versteht neben den Formaten Maildir
und mbox auch Dateien, die die Ausgabe von
git format-patch enthalten:
$ git \ am 0001-git-svn.txt-fix-usage-of-add-author-from.patch Applying: git-svn.txt: fix usage of --add-author-from
Wenn Sie Patches von Anderen mit git am einpflegen,
unterscheiden sich die Werte von Author/AuthorDate
und Committer/CommitDate. Somit werden sowohl der Autor
des Commits als auch der, der ihn einspielt, gewürdigt. Insbesondere
bleiben die Attribuierungen erhalten; es bleibt nachvollziehbar, wer
welche Codezeilen geschrieben hat. Mit Gitk werden die Author- und
Committer-Werte standardmäßig angezeigt; auf der Kommandozeile setzen
Sie die Option --format=fuller ein, die unter anderem von
git log und git show akzeptiert wird:
$ git show --format=fuller 12d3065
commit 12d30657d411979af3ab9ca7139b5290340e4abb
Author: Valentin Haenel <valentin.haenel@gmx.de>
AuthorDate: Mon Apr 25 23:36:15 2011 +0200
Commit: Junio C Hamano <gitster@pobox.com>
CommitDate: Tue Apr 26 11:48:34 2011 -0700
git-svn.txt: fix usage of --add-author-from
Bei dem Workflow Dictator and Lieutenants (Abschnitt 5.10, „Ein verteilter, hierarchischer Workflow“) kommt es vor, dass mehr als nur zwei Personen in
einen Commit involviert sind. In dem Fall ist es sinnvoll, dass jeder,
der den Patch begutachtet, ihn auch „absegnet“, allen voran
der Autor. Zu diesem Zweck gibt es die Option --signoff
(kurz -s) für die Kommandos git commit und
git am, die Name und E-Mail des Committers der Commit-Message
anhängt:
Signed-off-by: Valentin Haenel <valentin.haenel@gmx.de>
Das Feature ist vor allem bei größeren Projekten von Vorteil, meist haben diese auch Richtlinien, wie Commits zu formatieren sind und wie sie am besten verschickt werden.[84]
Beim Einpflegen von Patches mit git am kann es zu Konflikten
kommen, z.B. wenn die Patches auf einer älteren Version beruhen und
die betreffenden Zeilen bereits verändert wurden. In dem Fall wird der
Prozess unterbrochen und Sie haben dann mehrere Möglichkeiten, wie Sie
weiter vorgehen. Entweder Sie lösen den Konflikt, aktualisieren den
Index und führen den Prozess mit git am --continue fort,
oder Sie überspringen den Patch mit git am --skip. Mit
git am --abort brechen Sie den Prozess ab und
stellen den ursprünglichen Zustand des aktuellen Branches wieder her.
Da die Patches meist Veränderungen von Anderen enthalten, kann es
mitunter schwierig sein, die richtige Lösung für einen Konflikt zu
finden. Die beste Strategie für Patches, die sich nicht anwenden
lassen, ist es, den Autor der Patches zu bitten, diese per Rebase auf
eine wohldefinierte Basis, bspw. den aktuellen master,
aufzubauen und erneut zu schicken.
Tipp
Eine Alternative zu git am ist das etwas rudimentäre
Kommando git apply. Es dient dazu, einen Patch auf den
Working Tree oder Index (mit der Option --index)
anzuwenden. Es ähnelt so dem klassischen Unix-Kommando
patch. Es ist vor allem dann nützlich, wenn Sie den Patch
bzw. die Metadaten vor dem Commit noch bearbeiten wollen oder auch
wenn Ihnen jemand die Ausgabe von git diff statt
git format-patch als Patch geschickt hat.
Der Integration-Manager-Workflow skaliert nicht mit der Größe des Projekts. Bei großem Wachstum ist irgendwann der Maintainer mit der Komplexität des Projekts und der Anzahl der eingehenden Patches überfordert. Der sog. Dictator and Lieutenants-Workflow, der ausgiebig bei der Entwicklung des Linux-Kerns angewandt wird, schafft hier Abhilfe. In diesem Fall ist die Software meist in verschiedene Subsysteme unterteilt, und Beiträge werden von den Lieutenants (auch Subsystem-Maintainer) untersucht und dann an den Benevolent Dictator („Gütiger Diktator“) weitergeleitet. Dieser lädt die Veränderungen schließlich in das blessed („gesegnete“) Repository hoch, mit dem sich wiederum alle Mitstreiter synchronisieren.
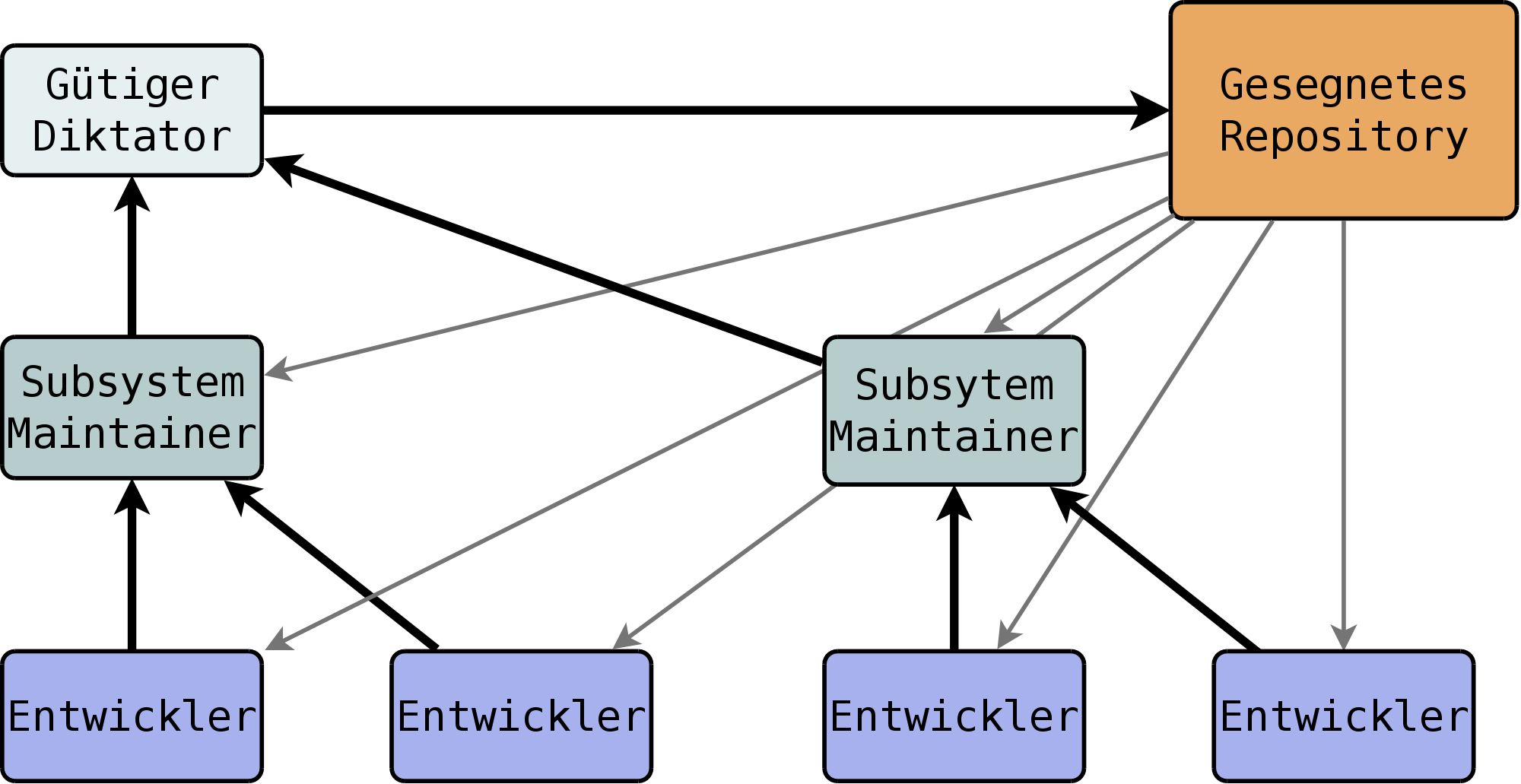
Der Workflow basiert auf Vertrauen: Der Diktator vertraut seinen Lieutenants und übernimmt deren weitergeleitete Modifikationen meist ohne Kontrolle. Vorteil ist, dass der Diktator entlastet wird, aber trotzdem ein Vetorecht behält, was zu dem Titel Benevolent Dictator führte.
Historisch bedingt ist das offizielle Repository oft nur das öffentliche Repository des aktuellen Haupt-Maintainers oder des Original-Autors. Wichtig ist, dass dieses Repository nur aufgrund sozialer Konventionen existiert. Sollte eines Tages ein anderer Entwickler das Projekt besser vorantreiben, kann es sein, dass sein öffentliches Repository das neue Blessed Repository wird. Aus technischer Sicht spricht nichts dagegen.
Die Projekte, die in der Praxis diesen Workflow einsetzen, favorisieren den Patch-Austausch per Mail. Jedoch ist die Art des Austauschs eher zweitrangig, und die Subsystem-Maintainer könnten genauso gut Pull-Requests von den ihnen bekannten Entwicklern erhalten; oder aber die Mitstreiter mischen ganz nach Belieben öffentliche Repositories und per E-Mail verschickte Patches. Die Flexibilität von Git – insbesondere die Vielzahl von verschiedenen Methoden zum Austausch von Veränderungen – unterstützen jeden erdenklichen Workflow im Sinne der freien, offenen Entwicklung. Sicherlich eine Eigenschaft, die maßgeblich zur Beliebtheit von Git beigetragen hat.
Bei größeren Softwareprojekten ist es bisweilen nötig, bestimmte Teile eines Programms in eigene Projekte auszulagern. Das ist zum Beispiel in den folgenden Situationen der Fall:
- Ihre Software hängt von einer bestimmten Version einer Bibliothek ab, die Sie mit dem Quellcode zusammen ausliefern wollen.
- Ihr anfänglich kleines Projekt wird mit der Zeit so groß, dass Sie die Funktionalität in eine Bibliothek auslagern wollen, die als eigenständiges Projekt verwaltet werden soll.
- Eigenständige Teile Ihrer Software werden von anderen Entwicklergruppen verwaltet.
Mit Git können Sie auf zwei verschiedene Weisen damit umgehen: Sie verwalten die Module als sogenannte Git-Submodules oder als Subtrees – in beiden Fällen verwalten Sie Quellcode in einem Unterverzeichnis Ihres Projekts.
Als Submodule verwalten Sie ein abgekoppeltes Repository, das nichts mit Ihrem übergeordneten Repository zu tun hat. Arbeiten Sie stattdessen mit Subtrees, dann wird die Projektgeschichte des Unterverzeichnisses untrennbar mit dem übergeordneten Projekt verbunden. Beides hat Vor- und Nachteile.
Wir betrachten beide Techniken beispielhaft, indem wir ein fiktionales
Projekt erstellen, das die libgit2 benötigt. Die Bibliothek
bietet, ähnlich der libgit.a, eine API, um Git-Repositories
zu untersuchen und zu verändern.[85] Die in C geschriebene Bibliothek kann ihre Funktionen
u.a. auch nach Lua, Ruby, Python, PHP und JavaScript herausreichen.
Submodules werden von Git als Unterverzeichnisse verwaltet, die einen
speziellen Eintrag in der Datei .gitmodules besitzen.
Zuständig für den Umgang mit ihnen ist das Kommando git
submodule.
Zunächst müssen wir die Bibliothek importieren. Das geschieht mit dem folgenden Kommando:
$ git submodule add git://github.com/libgit2/libgit2.git libgit2
Cloning into libgit2...
remote: Counting objects: 4296, done.
remote: Compressing objects: 100% (1632/1632), done.
remote: Total 4296 (delta 3214), reused 3530 (delta 2603)
Receiving objects: 100% (4296/4296), 1.92 MiB | 788 KiB/s, done.
Resolving deltas: 100% (3214/3214), done.
An der Ausgabe von git status können wir nun erkennen, dass
ein neues Verzeichnis libgit2 vorliegt, sowie die Datei
.gitmodules mit folgendem Inhalt erstellt wurde:
[submodule "libgit2"] path = libgit2 url = git://github.com/libgit2/libgit2.git
Diese Datei wurde auch schon dem Index hinzugefügt, also für den
Commit vorbereitet. Das Verzeichnis libgit2 hingegen taucht
in der Ausgabe von git diff --staged nicht wie gewohnt auf:
$ git diff --staged -- libgit2
diff --git a/libgit2 b/libgit2
new file mode 160000
index 0000000..b64e11d
--- /dev/null
+++ b/libgit2
@@ -0,0 +1 @@
+Subproject commit 7c80c19e1dffb4421f91913bc79b9cb7596634a4
Anstatt alle Dateien des Verzeichnisses aufzulisten, speichert Git
eine „spezielle“ Datei (erkennbar an dem unüblichen
Datei-Modus 160000), die lediglich den Commit, auf dem das
Modul gerade steht, festhält.
Wir importieren diese Änderungen und können von nun an die
libgit2 in ihrem Unterverzeichnis kompilieren und dann gegen
sie linken:
$ git commit -m "libgit2-submodule importiert"
Das übergeordnete Projekt und die libgit2 sind nun im Working
Tree zusammengeführt – ihre Versionsgeschichte aber ist und bleibt
getrennt. In dem Git-Repository der libgit2 können Sie sich
genau so verhalten wie in einem „echten“ Repository. Sie
können sich zum Beispiel die Ausgabe von git log in dem
übergeordneten Projekt und nach einem cd libgit2 in dem
Submodule anschauen.
Nun hat die libgit2 als Default-Branch (also der
HEAD auf der Serverseite) den Branch development
ausgewählt. Es ist möglicherweise nicht die beste Idee, diesen
Entwicklungsbranch mehr oder weniger mit Ihrem Repository zu
verdrahten.
Wir wechseln also in das Verzeichnis libgit2 und checken das
neueste Tag aus, v0.10.0:
$ cd libgit2 $ git checkout v0.10.0 # Nachricht über "detached HEAD state" $ cd .. $ git diff diff --git a/libgit2 b/libgit2 index 7c80c19..7064938 160000 --- a/libgit2 +++ b/libgit2 @@ -1 +1 @@ -Subproject commit 7c80c19e1dffb4421f91913bc79b9cb7596634a4 +Subproject commit 7064938bd5e7ef47bfd79a685a62c1e2649e2ce7
Das übergeordnete Git-Repository sieht also einen Wechsel des
HEAD, der durch das Kommando git checkout v0.10.0 in
libgit2/ passiert ist, als Änderung der Pseudo-Datei
libgit2, die nun auf den entsprechenden neuen Commit zeigt.
Jetzt können wir diese Änderung dem Index hinzufügen und als Commit abspeichern:
$ git add libgit2 $ git commit -m "Libgit2-Version auf v0.10.0 setzen"
Achtung: Fügen Sie niemals Dateien aus libgit2 oder
das Verzeichnis libgit2/ (endet mit
Slash) hinzu – das zerbricht das Modulkonzept von Git, Sie verwalten
dann auf einmal Dateien aus dem Submodule in dem übergeordneten
Projekt.
Analog können Sie per submodule update (oder
git remote update im Verzeichnis libgit2/) neue
Commits runterladen und ein Update der Bibliothek entsprechend im
übergeordneten Repository festhalten.
Wie sieht das Ganze nun aus Sicht eines Nutzer aus, der das Projekt zum ersten Mal klont? Zunächst ist offensichtlich, dass das oder die Submodules nicht fest mit dem Repository verbunden sind und nicht mit ausgeliefert werden:
$ git clone /dev/shm/super clone-super $ cd clone-super $ ls bar.c foo.c libgit2/ $ ls -l libgit2 total 0
Das Verzeichnis libgit2/ ist leer. Alles, was Git also über
die Submodules weiß, steckt in der Datei .gitmodules. Sie
müssen dieses Modul erst initialisieren und dann das Repository des
Moduls herunterladen:
$ git submodule init Submodule 'libgit2' (git://github.com/libgit2/libgit2.git) registered for path 'libgit2' $ git submodule update ... Submodule path 'libgit2': checked out '7064938bd5e7ef47bfd79a685a62c1e2649e2ce7'
Wir sehen also, dass libgit2 automatisch auf den in unserem
Repository festgelegten Stand von v0.10.0 gesetzt wird.
Prinzipiell kann nun aber der Nutzer auch in das Verzeichnis wechseln,
den Branch development auschecken und das Projekt gegen diese
Version kompilieren. Submodules erhalten die Flexibilität des
Unter-Repositorys – der Eintrag, auf welchem Stand das Modul steht,
ist also nur eine „Empfehlung“.
Im Gegensatz zu Submodules, die ihren Charakter als eigenständiges Git-Repository wahren, verschmelzen Sie die Geschichte zweier Projekte direkt, wenn Sie mit Subtrees arbeiten. Eine Gegenüberstellung beider Ansätze folgt im Anschluss.
Im Wesentlichen basiert diese Technik auf sogenannten Subtree-Merges,
auf die schon kurz in Abschnitt 3.3.3, „Merge-Strategien“
über Merge-Strategien eingegangen wurde. In unserem Beispiel erfolgt ein
Subtree-Merge, indem reguläre Commits aus dem Repository der
libgit2 unterhalb des Trees (Verzeichnisses)
libgit2/ gemergt werden – eine Datei auf oberster Ebene in
dem Repository der Bibliothek wird also zu einer Datei auf oberster
Ebene des Trees libgit2/, der wiederum Teil eines
Repositorys ist.
Git verfügt über ein Kommando, um Subtree-Merges zu
verwalten.[86]
Dabei müssen Sie immer explizit durch -P <prefix> angeben, auf welches
Unterverzeichnis Sie sich beziehen. Um die libgit2 in Version 0.8.0 zu
importieren, verwenden Sie:
$ git subtree add -P libgit2 \ git://github.com/libgit2/libgit2.git v0.8.0 git fetch git://github.com/libgit2/libgit2.git v0.8.0 From git://github.com/libgit2/libgit2 * tag v0.8.0 -> FETCH_HEAD Added dir 'libgit2'
Das Kommando lädt automatisch alle benötigten Commits herunter und
erzeugt einen Merge-Commit, der alle Dateien der libgit2 unterhalb des
Verzeichnisses libgit2/ erstellt.
Der Merge-Commit verknüpft nun die bisherige Versionsgeschichte mit
der der libgit2 (dadurch, dass ein Original-Commit
referenziert wird und der wiederum andere Commits referenziert).
Dieses Vorgehen hat nun zur Folge, dass in Ihrem Repository von nun an
alle relevanten Commits der libgit2 vorhanden sind.
Ihr Repository hat also nun zwei Root-Commits (siehe auch
Multi-Root-Repositories in Abschnitt 4.7, „Mehrere Root-Commits“).
Die Dateien liegen nun untrennbar mit dem Projekt verbunden vor. Ein
git clone dieses Repositorys würde auch alle Dateien
unterhalb von libgit2 übertragen.[87]
Was passiert nun, wenn Sie ein „Upgrade“ auf
v0.10.0 machen wollen? Verwenden Sie dafür das pull-Kommando von
git subtree:
$ git subtree -P libgit2 \ pull git://github.com/libgit2/libgit2.git v0.10.0 From git://github.com/libgit2/libgit2 * tag v0.10.0 -> FETCH_HEAD Merge made by the 'recursive' strategy. ...
Beachten Sie:
Da die Original-Commits der libgit2 vorliegen, ändern diese
Commits auch scheinbar Dateien auf oberster Ebene (z.B. COPYING, wenn Sie per git log --name-status die
Versionsgeschichte untersuchen). Tatsächlich werden diese Änderungen
aber in libgit2 ausgeführt – dafür ist der jeweilige
Merge-Commit verantwortlich, der die Trees entsprechend ausrichtet.
Tipp
Wenn Sie nicht an der Versionsgeschichte eines Unterprojektes
interessiert sind, aber einen bestimmten Stand im Repository verankern
wollen, können Sie die Option --squash verwenden. Die Kommandos git
subtree add/pull mergen dann nicht die entsprechenden Commits, sondern
erzeugen nur einen Commit, der alle Änderungen enthält. Achtung:
Verwenden Sie diese Option nicht, wenn Sie das Projekt nicht auch per
--squash importiert haben; dies führt zu Merge-Konflikten.
Möglicherweise stehen Sie irgendwann vor der Aufgabe, ein Unterverzeichnis Ihres Projektes als eigenes Repository verwalten zu wollen. Sie möchten die Änderungen aber weiterhin in dem ursprünglichen Projekt integrieren.
Beispielsweise wird die Dokumentation, die unter doc/ lag,
von nun an in einem eigenen Repository verwaltet. Gelegentlich, das
heißt alle paar Wochen, wollen Sie die neuesten Entwicklungen dann in
das Haupt-Repository übernehmen.
Das Kommando git subtree bietet dafür ein eigenes Subkommando
split an, mit dem Sie diesen Schritt automatisieren können. Es
erstellt eine Versionsgeschichte, die alle Änderungen eines
Verzeichnisses enthält, und gibt den neuesten Commit aus – diesen können
Sie dann in ein (leeres) Remote hochladen.
$ git subtree split -P doc --rejoin Merge made by the 'ours' strategy. 563c68aa14375f887d104d63bf817f1357482576 $ git push <neues-doku-repo> 563c68aa14375:refs/heads/master
Die Option --rejoin bewirkt, dass die so abgespaltene
Versionsgeschichte direkt wieder per git subtree merge in das aktuelle
Projekt integriert wird. Sie können von nun an per git subtree pull
die neuen Commits integrieren. Wollen Sie stattdessen mit der Option
--squash arbeiten, lassen Sie --rejoin weg.
Die Frage „Submodules oder Subtrees?“ lässt sich nicht generell, sondern nur von Fall zu Fall beantworten. Ausschlaggebendes Kriterium sollte die Zugehörigkeit des Unterprojektes zu dem übergeordneten sein: Wenn Sie fremde Software einbinden, dann vermutlich eher als Submodule, eigene mit begrenztem Aufkommen an Commits und einer direkten Relation zum Hauptprojekt eher als Subtree.
Beispielsweise müssen Sie bei der Installation von CGit (siehe
Abschnitt 7.5, „CGit – CGI for Git“) ein Submodule initialisieren und updaten, um die
libgit.a zu kompilieren. CGit benötigt also den Sourcecode
von Git, will aber nicht die Entwicklungsgeschichte mit der von Git
verschmelzen (die im Vergleich wenigen CGit-Commits würden darin auch
untergehen!). Sie können aber CGit auch gegen eine andere Git-Version
kompilieren, wenn Sie das möchten – die Flexibilität des
Unter-Repositorys bleibt gewahrt.
Der grafische Repository-Browser Gitk hingegen wird als Subtree
verwaltet. Er wird in git://ozlabs.org/~paulus/gitk
entwickelt, aber im Haupt-Git-Repository mit der
Subtree-Merge-Strategie unterhalb von gitk-git/ eingebunden.
[65] Wir haben den Spickzettel im Zusammenhang mit verschiedenen Git-Workshops erarbeitet. Er steht unter einer Creative-Commons-Lizenz und wird mit der Git-Hosting-Plattform Github, die wir in Kapitel 11, Github beschreiben, verwaltet.
[66] Genau genommen checkt Git nicht
„blind“ den Branch master aus. Tatsächlich schaut
Git nach, welchen Branch der HEAD der Gegenseite
referenziert, und checkt diesen aus.
[67] Weitere Informationen zu dem Git-Protokoll finden Sie in Abschnitt 7.1.1, „Das Git-Protokoll“ (siehe auch Abschnitt 3.1.1, „HEAD und andere symbolische Referenzen“).
[68] Eine
vollständige Auflistung der möglichen URLs finden Sie in der Man-Page
git-clone(1) im Abschnitt „Git URLs“.
[69] Der Stern (*) wird
wie bei der Shell auch als Wildcard interpretiert und zieht
alle Dateien in einem Verzeichnis in Betracht.
[70] Remote-Tracking-Branches sind nur dazu gedacht, die Branches in einem Remote zu verfolgen. Das Auschecken eines Remote-Tracking-Branches führt zu einem Detached-Head-State samt entsprechender Warnung.
[71] Das Mergen von origin/master nach master ist ein ganz normaler
Merge-Vorgang. Im obigen Beispiel wurden in der Zwischenzeit keine weiteren
lokalen Commits getätigt und von daher auch keine Merge-Commits erstellt. Der
master wurde per Fast-Forward auf origin/master vorgerückt.
[72] Das „Forcieren“ findet aber nur lokal statt: Der Empfänger-Server kann trotz Angabe der Option -f das Hochladen unterbinden. Dafür ist die Option receive.denyNonFastForwards zuständig, bzw. die Rechtezuweisung RW bei Gitolite (siehe Abschnitt 7.2.2, „Gitolite-Konfiguration“).
[73] Dies ist das Standard-Verhalten
seit Version 2.0 (push.default=simple). Frühere Git-Versionen
verwendeten ohne weitere Konfiguration die Einstellung
push.default=matching, die besonders für Anfänger fehlerträchtig sein
kann.
[74] Im Git-Jargon werden solche Remotes als Anonymous bezeichnet.
[75] Die Syntax <tag>^{} dereferenziert ein
Tag-Objekt, liefert also das Commit-, Tree- oder Blob-Objekt, auf das
das Tag zeigt.
[76] Zum
Beispiel mit dem Alias push = push --tags.
[77] Wie Sie die
Nummerierung, den Text und das Datei-Suffix anpassen, finden Sie in
der Man-Page git-format-patch(1).
[78] Die Zahl n ist
die Gesamtzahl an Patches, die exportiert wurden, und m ist
die Nummer des aktuellen Patches. In der Betreff-Zeile des dritten
Patch von fünf steht dann z.B. [PATCH 3/5].
[79] Sie sehen in Abbildung 5.10, „Patch-Serie als Mail-Thread“ eine etwas andere Reihenfolge der Patches als in den bisherigen Beispielen. Das liegt daran, dass die erste Version der Patch-Serie aus nur zwei Patches bestand, und das dritte erst nach dem Feedback von der Git-Mailingliste dazukam. Die Serie wurde dann erweitert und per Rebase auf den Stand gebracht, wie sie in diesem Abschnitt abgebildet ist.
[80] Sofern auf Ihrem System kein Mail Transfer Agent (MTA) installiert bzw. für den E-Mail-Versand konfiguriert ist, können Sie auch einen externen SMTP-Server verwenden. Passen Sie dafür die in der Sektion „Use GMail as the SMTP server“ der bereits erwähnten Man-Page beschriebenen Einstellungen an.
[83] Nützliche Tipps und Tricks für diverse MUAs finden Sie in der Datei Documentation/SubmittingPatches im Git-via-Git-Repository im Abschnitt „MUA specific hints“ sowie in der Man-Page von git-format-patch(1) in den Abschnitten „MUA-specific Hints“ und „Discussion“.
[84] Für das Git-Projekt
finden Sie diese unter: Documentation/SubmittingPatches im
Quellcode-Repository.
[85] Die libgit.a wird beim
Kompilieren von Git erzeugt und versammelt alle Funktionen, die in
Git „öffentlich“ sind. Sie ist allerdings nicht
reentrant oder Thread-sicher, so dass sie nur eingeschränkt
verwendet werden kann. Diese Einschränkungen hat libgit2
nicht.
[86] Das Kommando ist kein Standard-Kommando von Git,
wird aber von einigen Linux-Distributionen (z.B. Debian, Archlinux)
sowie im Windows-Git-Installer automatisch mit installiert. Überprüfen
Sie durch einen Aufruf von git subtree, ob das Kommando installiert
ist. Falls nicht, können Sie das Script unter /usr/share/doc/git/contrib/subtree/
suchen, oder aus dem Quellcode von Git (unter contrib/subtree)
kopieren.
[87] Achten Sie daher darauf, dass Sie mit dieser Technik nur Inhalte einbinden, die Sie auch weitergeben dürfen. Je nach Lizenz ist die Benutzung einer Software möglicherweise erlaubt, aber nicht die Weiterverbreitung (engl. Distribution).
