In diesem Kapitel stellen wir Ihnen die wichtigsten Git-Kommandos vor, mit Hilfe derer Sie Ihre Projektdateien in Git verwalten. Unabdingbar für eine fortgeschrittene Nutzung ist das Verständnis des Git-Objektmodells; dieses wichtige Konzept behandeln wir im zweiten Abschnitt des Kapitels. Mögen die Ausführungen zunächst allzu theoretisch scheinen, so möchten wir Sie Ihnen dennoch sehr ans Herz legen. Alle weiteren Aktionen werden Ihnen mit dem Wissen um diese Hintergründe deutlich leichter von der Hand gehen.
Die Kommandos, die Sie zum Einstieg kennengelernt haben (vor allem
add und commit), arbeiten auf dem Index. Im
Folgenden werden wir uns genauer mit dem Index auseinandersetzen und
die erweiterte Benutzung dieser Kommandos behandeln.
Der Inhalt von Dateien liegt für Git auf drei Ebenen, dem
Working Tree, dem Index und dem Repository. Der
Working Tree entspricht den Dateien, wie sie auf dem Dateisystem Ihres
Arbeitsrechners liegen – wenn Sie also Dateien mit einem Editor
bearbeiten, mit grep darin suchen etc., operieren Sie immer
auf dem Working Tree.
Das Repository ist der Sammelbehälter für Commits, also Änderungen, versehen mit Angaben zu Autor, Datum und Beschreibung. Die Commits ergeben zusammen die Versionsgeschichte.
Git führt nun, im Gegensatz zu vielen anderen Versionskontrollsystemen, eine Neuerung ein, den Index. Es handelt sich um eine etwas schwierig greifbare Zwischenebene zwischen Working Tree und Repository. Er dient dazu, Commits vorzubereiten. Das bedeutet, dass Sie nicht immer alle Änderungen, die Sie an einer Datei vorgenommen haben, auch als Commit einchecken müssen.
Die Git-Kommandos add und reset agieren (in ihrer
Grundform) auf dem Index und bringen Änderungen in den Index ein bzw.
löschen diese wieder; erst das Kommando commit überträgt die
Datei, wie sie im Index vorgehalten wird, in das Repository (Abbildung 2.1, „Kommandos add, reset und commit“).

Im Ausgangszustand, das heißt wenn git status die Nachricht
nothing to commit ausgibt, sind Working Tree und Index mit
HEAD synchronisiert. Der Index ist also nicht
„leer“, sondern enthält die Dateien im gleichen Zustand, wie
sie im Working Tree vorliegen.
In der Regel ist dann der Arbeitsablauf folgender: Zuerst nehmen Sie mit
einem Editor eine Veränderung am Working Tree vor. Diese Veränderung
wird durch add in den Index übernommen und schließlich per
commit im Repository abgespeichert.
Sie können sich die Unterschiede zwischen diesen drei Ebenen jeweils
durch das diff-Kommando anzeigen lassen. Ein simples
git diff zeigt die Unterschiede zwischen Working Tree und
Index an – also die Unterschiede zwischen den (tatsächlichen) Dateien
auf Ihrem Arbeitssystem und den Dateien, wie sie eingecheckt würden,
wenn Sie git commit aufrufen würden.
Das Kommando git diff --staged zeigt hingegen die
Unterschiede zwischen Index (der auch Staging Area genannt
wird) und Repository an, also die Unterschiede, die ein Commit ins
Repository übertragen würde. Im Ausgangszustand, wenn Working Tree und Index
mit HEAD synchron sind, erzeugen weder git diff noch
git diff --staged eine Ausgabe.
Wollen Sie alle
Änderungen an allen Dateien übernehmen, gibt es zwei
Abkürzungen: Zunächst die Option -u bzw. --update
von git add. Dadurch werden alle Veränderungen in den Index
übertragen, aber noch kein Commit erzeugt. Weiter abkürzen können Sie
mit der Option -a bzw. --all von git
commit. Dies ist eine Kombination aus git add -u und
git commit, wodurch alle Veränderungen an allen Dateien in
einem Commit zusammengefasst werden – Sie umgehen den Index.
Vermeiden Sie es, sich diese Optionen zur Angewohnheit zu machen – sie
sind zwar gelegentlich als Abkürzung ganz praktisch, verringern aber
die Flexibilität.
Ein alternatives Ausgabeformat für git diff ist das
sog. Word-Diff, das über die Option
--word-diff zur Verfügung steht. Statt der entfernten
und hinzugefügten Zeilen zeigt die Ausgabe von git diff
mit einer entsprechenden Syntax sowie farblich kodiert die
hinzugekommenen (grün) und entfernten (rot)
Wörter.[12] Das ist dann praktisch, wenn Sie in
einer Datei nur einzelne Wörter ändern, beispielsweise bei der
Korrektur von AsciiDoc- oder LaTeX-Dokumenten, denn ein Diff ist schwierig zu lesen,
wenn sich hinzugefügte und entfernte Zeile nur durch ein einziges Wort
unterscheiden:
$ git diff
...
- die Option `--color-words` zur Verfgung steht. Statt der entfernten
+ die Option `--color-words` zur Verfügung steht. Statt der entfernten
...
Verwenden Sie hingegen die Option --word-diff, so werden nur geänderte
Wörter entsprechend markiert angezeigt; außerdem werden Zeilenumbrüche
ignoriert, was ebenfalls sehr praktisch ist, weil eine Neuausrichtung
der Wörter nicht als Änderung in die Diff-Ausgabe eingeht:
$ git diff --word-diff
...
--color-words zur [-Verfgung-]{Verfügung} steht.
...
Tipp
Falls Sie viel mit Fließtext arbeiten, bietet es sich an, ein Alias zur
Abkürzung dieses Befehls einzurichten, so dass Sie beispielsweise nur
noch git dw eingeben müssen:
$ git config --global alias.dw "diff --word-diff"
Warum aber sollte man Commits schrittweise erstellen – will man nicht immer alle Änderungen auch einchecken?
Ja, natürlich will man seine Änderungen in der Regel vollständig übernehmen. Es kann allerdings sinnvoll sein, sie in Schritten einzupflegen, um etwa die Entwicklungsgeschichte besser abzubilden.
Ein Beispiel: Sie haben in den vergangenen drei Stunden intensiv an Ihrem Software-Projekt gearbeitet, haben aber, weil es so spannend war, vergessen, die vier neuen Features in handliche Commits zu verpacken. Zudem sind die Features über diverse Dateien verstreut.
Im besten Fall wollen Sie also selektiv arbeiten, d.h. nicht alle Veränderungen aus einer Datei in einen Commit übernehmen, sondern nur bestimmte Zeilen (Funktionen, Definitionen, Tests, …), und das auch noch aus verschiedenen Dateien.
Der Index von Git bietet dafür die gewünschte Flexibilität. Sie sammeln einige Änderungen im Index und verpacken sie in einem Commit – alle anderen Änderungen bleiben aber nach wie vor in den Dateien erhalten.
Wir wollen das anhand des „Hello World!“-Beispiels aus dem
vorigen Kapitel illustrieren. Zur Erinnerung der Inhalt der Datei
hello.pl:
# Hello World! in Perl print "Hello World!\n";
Nun präparieren wir die Datei so, dass sie mehrere unabhängige
Veränderungen hat, die wir nicht in einem einzelnen Commit
zusammenfassen wollen. Zunächst fügen wir eine Shebang-Zeile
am Anfang hinzu.[13] Außerdem
kommt eine Zeile hinzu, die den Autor benennt, sowie eine
Perl-Anweisung use strict, die den Perl-Interpreter anweist,
bei der Syntaxanalyse möglichst streng zu sein. Wichtig ist für unser
Beispiel, dass die Datei an mehreren Stellen verändert wurde:
#!/usr/bin/perl # Hello World! in Perl # Author: Valentin Haenel use strict; print "Hello World!\n";
Mit einem einfachen git add hello.pl würden alle neuen Zeilen
dem Index hinzugefügt – der Stand der Datei im Index wäre also der
gleiche wie im Working Tree. Stattdessen verwenden wir die Option
--patch bzw. kurz -p.[14] Dies hat zur Folge, dass
wir interaktiv gefragt werden, welche Veränderungen wir dem Index
hinzufügen wollen. Git bietet uns jede Veränderung einzeln an, und wir
können von Fall zu Fall entscheiden, wie wir mit dieser verfahren
wollen:
$ git add -p
diff --git a/hello.pl b/hello.pl
index c6f28d5..908e967 100644
--- a/hello.pl
+++ b/hello.pl
@@ -1,2 +1,5 @@
+#!/usr/bin/perl
# Hello World! in Perl
+# Author: Valentin Haenel
+use strict;
print "Hello World!\n";
Stage this hunk [y,n,q,a,d,/,s,e,?]?
Hier zeigt Git alle Änderungen an, da sie im Code sehr nah beieinander liegen. Bei weit auseinanderliegenden oder auf verschiedene Dateien verteilten Veränderungen werden sie getrennt angeboten. Der Begriff Hunk bezeichnet lose zusammenhängende Zeilen im Quellcode. Wir haben an dieser Stelle unter anderem folgende Optionen:
Stage this hunk[y,n,q,a,d,/,s,e,?]?
Die Optionen sind jeweils nur einen Buchstaben lang und schwierig zu merken. Eine kleine Erinnerung erhalten Sie immer durch [?]. Die wichtigsten Optionen haben wir im Folgenden zusammengefasst.
-
y(yes) - Übernimm den aktuellen Hunk in den Index.
-
n(no) - Übernimm den aktuellen Hunk nicht.
-
q(quit) - Übernimm weder den aktuellen Hunk noch einen der folgenden.
-
a(all) - Übernimm den aktuellen Hunk und alle, die folgen (in der aktuellen Datei).
-
s(split) - Versuche, den aktuellen Hunk zu teilen.
-
e(edit) - Editiere den aktuellen Hunk.[15]
In dem Beispiel teilen wir den aktuellen Hunk und geben
s für split ein.
Stage this hunk [y,n,q,a,d,/,s,e,?]? [s]
Split into 2 hunks.
@@ -1 +1,2 @@
+#!/usr/bin/perl
# Hello World! in Perl
Git bestätigt, dass der Hunk erfolgreich geteilt werden konnte, und
bietet uns nun ein Diff an, das nur die Shebang-Zeile
enthält.[16] Wir geben y für
yes an und beim nächsten Hunk q für quit. Um
zu überprüfen, ob alles geklappt hat, verwenden wir git diff
mit der Option --staged, die den Unterschied zwischen
Index und HEAD (dem neuesten Commit)
anzeigt:
$ git diff --staged
diff --git a/hello.pl b/hello.pl
index c6f28d5..d2cc6dc 100644
--- a/hello.pl
+++ b/hello.pl
@@ -1,2 +1,3 @@
+#!/usr/bin/perl
# Hello World! in Perl
print "Hello World!\n";
Um zu sehen, welche Veränderungen sich noch nicht im Index
befinden, reicht ein einfacher Aufruf von git diff, der uns
zeigt, dass sich – wie erwartet – noch zwei Zeilen im Working Tree
befinden:
$ git diff
diff --git a/hello.pl b/hello.pl
index d2cc6dc..908e967 100644
--- a/hello.pl
+++ b/hello.pl
@@ -1,3 +1,5 @@
#!/usr/bin/perl
# Hello World! in Perl
+# Author: Valentin Haenel
+use strict;
print "Hello World!\n";
An dieser Stelle könnten wir einen Commit erzeugen, wollen zur
Demonstration aber noch einmal von vorn beginnen. Darum setzen wir
mit git reset HEAD den Index zurück.
$ git reset HEAD
Unstaged changes after reset:
M hello.pl
Git bestätigt und nennt die Dateien, in denen sich Veränderungen befinden; in diesem Fall ist es nur die eine.
Das Kommando git reset ist gewissermaßen das Gegenstück zu
git add: Statt Unterschiede aus dem Working Tree in den Index
zu übertragen, überträgt reset Unterschiede aus dem
Repository in den Index. Änderungen in den Working Tree zu
übertragen, ist möglicherweise destruktiv, da Ihre Änderungen
verlorengehen könnten. Daher ist dies nur mit der Option
--hard möglich, die wir in Abschnitt 3.2.3, „Reset und der Index“
behandeln.
Sollten Sie häufiger git add -p verwenden, ist es nur eine
Frage der Zeit, bis Sie versehentlich einen Hunk auswählen, den Sie
eigentlich gar nicht wollten. Sollte der Index leer gewesen sein, ist
dies kein Problem, da Sie ihn ja zurücksetzen können, um von vorn
anzufangen. Problematisch wird es erst, wenn Sie bereits viele
Veränderungen im Index aufgezeichnet haben und diese nicht verlieren
möchten, Sie also einen bestimmten Hunk aus dem Index entfernen, ohne
die anderen Hunks anfassen zu wollen.
Analog zu git add -p gibt es daher den Befehl git
reset -p, der einzelne Hunks wieder aus dem Index entfernt. Um das
zu demonstrieren, übernehmen wir zunächst alle Veränderungen mit
git add hello.pl und starten git reset -p.
$ git reset -p
diff --git a/hello.pl b/hello.pl
index c6f28d5..908e967 100644
--- a/hello.pl
+++ b/hello.pl
@@ -1,2 +1,5 @@
+#!/usr/bin/perl
# Hello World! in Perl
+# Author: Valentin Haenel
+use strict;
print "Hello World!\n";
Unstage this hunk [y,n,q,a,d,/,s,e,?]?
Wie bei dem Beispiel mit git add -p bietet Git nach und nach
Hunks an, jedoch sind es diesmal alle Hunks im Index. Entsprechend
lautet die Frage: Unstage this hunk [y,n,q,a,d,/,s,e,?]?, also
ob wir den Hunk wieder aus dem Index herausnehmen möchten. Wie gehabt,
erhalten wir durch die Eingabe des Fragezeichens eine erweiterte
Beschreibung der verfügbaren Optionen. Wir drücken an dieser Stelle
einmal s für split, einmal n für no
und einmal y für yes. Damit sollte sich jetzt nur die
Shebang-Zeile im Index befinden:
$ git diff --staged
diff --git a/hello.pl b/hello.pl
index c6f28d5..d2cc6dc 100644
--- a/hello.pl
+++ b/hello.pl
@@ -1,2 +1,3 @@
+#!/usr/bin/perl
# Hello World! in Perl
print "Hello World!\n";
Tipp
Bei den interaktiven Modi von git add und git
reset müssen Sie nach Eingabe einer Option die Enter-Taste
drücken. Mit folgender Konfigurationseinstellung sparen Sie sich
diesen zusätzlichen Tastendruck.
$ git config --global interactive.singlekey true
Ein Wort der Warnung:
Ein git add -p kann dazu verleiten, Versionen einer Datei
einzuchecken, die nicht lauffähig oder syntaktisch korrekt sind
(z.B. weil Sie eine wesentliche Zeile vergessen haben). Verlassen
Sie sich daher nicht darauf, dass Ihr Commit korrekt ist, nur weil
make – was auf den Dateien des Working Tree arbeitet! – erfolgreich durchläuft. Auch wenn ein späterer Commit das Problem
behebt, stellt dies unter anderem bei der automatisierten Fehlersuche
via Bisect (siehe Abschnitt 4.8, „Regressionen finden – git bisect“) ein Problem dar.
Sie wissen nun, wie Sie Änderungen zwischen Working Tree, Index und
Repository austauschen. Wenden wir uns nun dem Kommando git
commit zu, mit dem Sie Änderungen im Repository
„festschreiben“.
Ein Commit hält den Stand aller Dateien Ihres Projekts zu einem bestimmten Zeitpunkt fest und enthält zudem Metainformationen:[17]
- Name des Autors und E-Mail-Adresse
- Name des Committers und E-Mail-Adresse
- Erstellungsdatum
- Commit-Datum
Tatsächlich ist es so, dass der Name des Autors nicht der Name
des Committers (der den Commit einpflegt) sein muss. Häufig werden
Commits von Maintainern integriert oder bearbeitet (z.B.
durch rebase, was auch die Committer-Informationen anpasst,
siehe Abschnitt 4.1, „Commits verschieben – Rebase“). Die Committer-Informationen sind aber
in der Regel von nachrangiger Bedeutung – die meisten Programme
zeigen nur den Autor und das Datum der Commit-Erstellung an.
Wenn Sie einen Commit erstellen, verwendet Git die im vorherigen
Abschnitt konfigurierten Einstellungen user.name und
user.email, um den Commit zu kennzeichnen.
Bei einem Aufruf von git commit ohne zusätzliche Argumente
fasst Git alle Veränderungen im Index zu einem Commit zusammen und
öffnet einen Editor, mit dem Sie eine Commit-Message erstellen. Die
Nachricht enthält jedoch immer eine mit Rautezeichen (#)
auskommentierte Anleitung bzw. Informationen darüber, welche Dateien
durch den Commit geändert werden. Rufen Sie git commit -v
auf, erhalten Sie unterhalb der Anleitung noch ein Diff der
Änderungen, die Sie einchecken werden. Das ist vor allem praktisch, um
einen Überblick über die Änderungen zu behalten und die
Auto-Vervollständigungsfunktion Ihres Editors zu verwenden.
Sobald Sie den Editor beenden, erstellt Git den Commit. Geben Sie keine Commit-Nachricht an oder löschen den gesamten Inhalt der Datei, bricht Git ab und erstellt keinen Commit.
Wollen Sie nur eine Zeile schreiben, bietet sich die Option
--message oder kurz -m an, mit der Sie direkt auf
der Kommandozeile die Nachricht angeben und so den Editor umgehen:
$ git commit -m "Dies ist die Commit-Nachricht"
Wenn Sie vorschnell git commit eingegeben haben, den Commit aber noch geringfügig verbessern wollen, hilft die
Option --amend („berichtigen“). Die Option
veranlasst Git, die Änderungen im Index dem eben getätigten Commit
„hinzuzufügen“.[18] Außerdem können Sie die
Commit-Nachricht anpassen. Beachten Sie, dass sich die SHA-1-Summe des
Commits in jedem Fall ändert.
Mit dem Aufruf git commit --amend verändern Sie nur den
aktuellen Commit auf einem Branch. Wie Sie weiter zurückliegende
Commits verbessern, beschreibt Abschnitt 4.1.9, „Einen Commit verbessern“.
Tipp
Der Aufruf von git commit --amend startet automatisch einen Editor, so
dass Sie auch noch die Commit-Nachricht bearbeiten können. Häufig wollen
Sie aber nur noch eine kleine Korrektur an einer Datei vornehmen, ohne die
Nachricht anzupassen. Für die Autoren bewährt sich in dieser Situation
ein Alias fixup:
$ git config --global alias.fixup "commit --amend --no-edit"
Wie sollte eine Commit-Nachricht aussehen? An der äußeren Form lässt sich nicht viel ändern: Die Commit-Nachricht muss mindestens eine Zeile lang sein, die am besten aber maximal 50 Zeichen umfasst. Das macht Auflistungen der Commits besser lesbar. Sofern Sie eine genauere Beschreibung hinzufügen wollen (was äußerst empfehlenswert ist!), trennen Sie diese von der ersten Zeile durch eine Leerzeile. Keine Zeile sollte – wie auch bei E-Mails üblich – länger als 76 Zeichen sein.
Commit-Nachrichten folgen oft den Gewohnheiten oder Besonderheiten eines Projekts. Möglicherweise gibt es Konventionen, wie zum Beispiel Referenzen zum Bugtracking- oder Ticket-System oder ein Link zur entsprechenden API-Dokumentation.
Beachten Sie die folgenden Punkte beim Verfassen einer Commit-Beschreibung:
-
Erstellen Sie niemals leere Commit-Nachrichten. Auch
Commit-Nachrichten wie
Update,Verbesserung,Fixetc. sind ebenso aussagekräftig wie eine leere Nachricht – dann können Sie es auch gleich lassen. - Ganz wichtig: Beschreiben Sie, warum etwas verändert wurde und welche Implikationen das haben kann. Was verändert wurde, ist immer aus dem Diff ersichtlich!
- Seien Sie kritisch und vermerken Sie, wenn Sie glauben, dass noch Verbesserungsbedarf besteht oder der Commit möglicherweise an anderer Stelle Fehler einführt.
- Die erste Zeile sollte nicht länger als 50 Zeichen sein, damit bleibt die Ausgabe der Versionsgeschichte stets gut formatiert und lesbar.
- Wird die Nachricht länger, sollte in der ersten Zeile eine kurze Zusammenfassung (mit den wichtigen Schlagwörtern) stehen. Nach einer Leerzeile folgt dann eine umfangreiche Beschreibung.
Wir können nicht häufig genug betonen, wie wichtig eine gute Commit-Beschreibung ist. Beim Commit sind einem Entwickler die Änderungen noch gut im Gedächtnis, aber schon nach wenigen Tagen ist die Motivation dahinter oft vergessen. Auch Ihre Kollegen oder Projektmitstreiter werden es Ihnen danken, weil sie Änderungen viel schneller erfassen können.
Eine gute Commit-Nachricht zu schreiben hilft auch, kurz darüber zu reflektieren, was schon geschafft ist und was noch ansteht. Vielleicht merken Sie beim Schreiben, dass Sie noch ein wesentliches Detail vergessen haben.
Man kann auch über eine Zeitbilanz argumentieren: Die Zeit, die Sie benötigen, um eine gute Commit-Nachricht zu schreiben, beläuft sich auf ein bis zwei Minuten. Um wie viel Zeit wird sich die Fehlersuche aber verringern, wenn jeder Commit gut dokumentiert ist? Wie viel Zeit sparen Sie anderen (und sich selbst), wenn Sie zu einem – möglicherweise schwer verständlichen – Diff noch eine gute Beschreibung mitliefern? Auch das Blame-Tool, das jede Zeile einer Datei mit dem Commit, der sie zuletzt geändert hat, annotiert, wird bei ausführlichen Commit-Beschreibungen zu einem unerlässlichen Hilfsmittel werden (siehe Abschnitt 4.3, „Wer hat diese Änderungen gemacht? – git blame“).
Wenn Sie nicht gewöhnt sind, ausführliche Commit-Nachrichten zu schreiben, fangen Sie heute damit an. Übung macht den Meister, und wenn Sie sich erst einmal daran gewöhnt haben, geht die Arbeit schnell von der Hand – Sie selbst und andere profitieren davon.
Das Repository des Git-Projekts ist ein Paradebeispiel für gute Commit-Nachrichten. Ohne Details von Git zu kennen, wissen Sie schnell, wer warum was geändert hat. Außerdem sieht man, durch wie viele Hände solch ein Commit geht, bevor er integriert wird.
Leider sind die Commit-Nachrichten in den meisten Projekten dennoch sehr spartanisch gehalten; seien Sie also nicht enttäuscht, wenn Ihre Mitstreiter schreibfaul sind, sondern gehen Sie mit gutem Beispiel und ausführlichen Beschreibungen voran.
Wenn Sie Dateien, die von Git verwaltet werden, löschen oder
verschieben wollen, dann verwenden Sie dafür git rm bzw.
git mv. Sie wirken wie die regulären Unix-Kommandos,
modifizieren aber darüber hinaus den Index, so dass die Aktion in den
nächsten Commit einfließt.[19]
Analog zu den Standard-Unix-Kommandos akzeptiert git rm auch
die Optionen -r und -f, um rekursiv zu löschen bzw.
das Löschen zu erzwingen. Auch git mv bietet eine Option
-f (force), falls der neue Dateiname schon existiert
und überschrieben werden soll. Beide Kommandos akzeptieren die Option
-n bzw. --dry-run, die bewirkt, dass der Vorgang
simuliert wird, Dateien also nicht modifiziert werden.
Tipp
Um eine Datei nur aus dem Index zu löschen, verwenden Sie
git rm --cached. Sie bleibt dann im Working Tree
erhalten.
Sie werden häufiger vergessen, eine Datei über git mv zu
verschieben oder per git rm zu löschen, und stattdessen die
Standard-Unix-Kommandos verwenden. In diesem Fall markieren Sie die
(schon per rm gelöschte) Datei einfach auch als gelöscht im
Index, und zwar per git rm <datei>.
Für eine Umbenennung gehen Sie so vor: Markieren Sie zunächst den
alten Dateinamen per git rm <alter-name> als gelöscht. Fügen
Sie dann die neue Datei hinzu: git add <neuer-name>.
Überprüfen Sie anschließend per git status, ob die Datei als
„umbenannt“ gekennzeichnet ist.
Tipp
Intern spielt es für Git keine Rolle, ob Sie eine Datei regulär per
mv verschieben, dann git add <neuer-name> und git rm
<alter-name> ausführen. In jedem Fall wird lediglich die Referenz auf
ein Blob-Objekt geändert (siehe Abschnitt 2.2, „Das Objektmodell“).
Git kommt allerdings mit einer sogenannten Rename Detection: Wenn ein Blob gleich ist und nur von einem anderen Dateinamen referenziert wird, dann fasst Git dies als eine Umbenennung auf. Wollen Sie die Geschichte einer Datei untersuchen und ihr bei eventuellen Umbenennungen folgen, verwenden Sie das folgende Kommando:
$ git log --follow -- <datei>
Wenn Sie nach einem Ausdruck in allen Dateien Ihres Projektes suchen
wollen, bietet sich normalerweise ein Aufruf von grep -R
<ausdruck> . an.
Git bietet allerdings ein eigenes Grep-Kommando, das Sie per
git grep <ausdruck> aufrufen. In der Regel sucht das
Kommando den Ausdruck in allen von Git verwalteten Dateien. Wollen Sie
stattdessen nur einen Teil der Dateien untersuchen, können Sie das
Muster explizit angeben. Mit folgendem Kommando finden Sie alle
Vorkommnisse von border-color in allen CSS-Dateien:
$ git grep border-color -- '*.css'
Die Grep-Implementation von Git unterstützt alle gängigen Flags, die
auch in GNU Grep vorhanden sind. Allerdings ist ein Aufruf von
git grep in der Regel um eine Größenordnung schneller, da Git
durch die Objektdatenbank sowie das Multithread-Design des Kommandos
wesentliche Performance-Vorteile hat.
Tipp
Die populäre grep-Alternative ack zeichnet sich vor allem dadurch
aus, dass es die auf das Suchmuster passenden Zeilen einer Datei unter
einer entsprechenden „Überschrift“ zusammenfasst, sowie prägnante
Farben verwendet. Sie können die Ausgabe von ack mit git grep
emulieren, indem Sie folgendes Alias verwenden:
$ git config alias.ack '!git -c color.grep.filename="green bold" \ -c color.grep.match="black yellow" -c color.grep.linenumber="yellow bold" \ grep -n --break --heading --color=always --untracked'
Mit git log untersuchen Sie die Versionsgeschichte des
Projekts. Die Optionen dieses Kommandos (die großteils auch für
git show funktionieren) sind sehr umfangreich, wir werden im
Folgenden die wichtigsten vorstellen.
Ohne weitere Argumente gibt git log für jeden Commit Autor,
Datum, Commit-ID sowie die komplette Commit-Nachricht aus. Das ist
dann praktisch, wenn Sie einen schnellen Überblick benötigen, wer wann
was gemacht hat. Allerdings ist die Liste etwas unhandlich, sobald Sie
viele Commits betrachten.
Wollen Sie nur die kürzlich erstellten Commits anschauen, begrenzen Sie die
Ausgabe von git log durch die Option -<n> auf n
Commits. Die letzten vier Commits erhalten Sie zum Beispiel mit:
$ git log -4
Um einen einzelnen Commit anzuzeigen, geben Sie stattdessen ein:
$ git log -1 <commit>
Das Argument <commit> ist eine legale Bezeichnung für einen einzelnen
Commit, z.B. die Commit-ID bzw. SHA-1-Summe. Wenn Sie jedoch
nichts angeben, verwendet Git automatisch HEAD. Abgesehen von einzelnen
Commits versteht das Kommando allerdings auch sog. Commit-Ranges (Reihe
von Commits), siehe Abschnitt 2.1.7, „Commit-Ranges“.
Die Option -p (--patch) fügt den vollen Patch im
Unified-Diff-Format unter der Beschreibung an. Damit ist also ein
git show <commit> von der Ausgabe äquivalent zu git
log -1 -p <commit>.
Wollen Sie die Commits in komprimierter Form anzeigen, empfiehlt sich
die Option --oneline: Sie fasst jeden Commit mit seiner
abgekürzten SHA-1-Summe und der ersten Zeile der Commit-Nachricht
zusammen. Daher ist es wichtig, dass Sie in dieser Zeile möglichst
hilfreiche Informationen verpacken! Das sieht dann zum Beispiel so
aus:[20]
$ git log --oneline 25f3af3 Correctly report corrupted objects 786dabe tests: compress the setup tests 91c031d tests: cosmetic improvements to the repo-setup test b312b41 exec_cmd: remove unused extern
Die Option --oneline ist nur ein Alias für
--pretty=oneline. Es gibt noch andere Möglichkeiten, die
Ausgabe von git log anzupassen. Die möglichen Werte für die
Option --pretty sind:
-
oneline - Commit-ID und erste Zeile der Beschreibung
-
short - Commit-ID, erste Zeile der Beschreibung sowie Autor des Commits; Ausgabe umfasst vier Zeilen.
-
medium - Default; Ausgabe von Commit-ID, Autor, Datum und kompletter Beschreibung.
-
full - Commit-ID, Name des Autors, Name des Committers und vollständige Beschreibung – kein Datum.
-
fuller -
Wie
medium, aber zusätzlich Datum und Name des Committers. -
email -
Formatiert die Informationen von
mediumso, dass sie wie eine E-Mail aussehen. -
format:<string> -
Durch Platzhalter beliebig
anpassbares Format; für Details siehe die Man-Page
git-log(1), Abschnitt „Pretty Formats“.
Unabhängig davon können Sie unterhalb der Commit-Nachricht weitere Informationen über die Veränderungen durch den Commit ausgeben. Betrachten Sie folgende Beispiele, in denen deutlich wird, welche Dateien an wie vielen Stellen geändert wurden:
$ git log -1 --oneline 4868b2ea
4868b2e setup: officially support --work-tree without --git-dir
$ git log -1 --oneline --name-status 4868b2ea
4868b2e setup: officially support --work-tree without --git-dir
M setup.c
M t/t1510-repo-setup.sh
$ git log -1 --oneline --stat 4868b2ea
4868b2e setup: officially support --work-tree without --git-dir
setup.c | 19
Sie können die anzuzeigenden Commits zeitlich eingrenzen, und zwar mit
den Optionen --after bzw. --since sowie
--until bzw. --before. Die Optionen sind jeweils
synonym, liefern also dieselben Ergebnisse.
Sie können absolute Daten in jedem gängigen Format angeben oder auch relative Daten, hier einige Beispiele:
$ git log --after='Tue Feb 1st, 2011' $ git log --since='2011-01-01' $ git log --since='two weeks ago' --before='one week ago' $ git log --since='yesterday'
Geben Sie nach einem git log-Aufruf einen oder mehrere Datei-
oder Verzeichnisnamen an, wird Git nur die Commits anzeigen, die
zumindest eine der angegebenen Dateien betrifft. Gute Strukturierung
eines Projekts vorausgesetzt, lässt sich die Ausgabe der Commits stark
begrenzen und eine bestimmte Änderung rasch finden.
Da Dateinamen möglicherweise mit Branches oder Tags kollidieren,
sollten Sie die Dateinamen sicherheitshalber nach einem --
angeben, der besagt, dass nur noch Datei-Argumente folgen.
$ git log -- main.c $ git log -- *.h $ git log -- Documentation/
Diese Aufrufe geben nur die Commits aus, in denen Änderungen an der
Datei main.c, einer .h-Datei respektive an einer
Datei unterhalb von Documentation/ vorgenommen wurden.
Sie können auch im Stile von grep nach Commits suchen; hier
stehen die Optionen --author, --committer und
--grep zur Verfügung.
Die ersten beiden Optionen filtern die Commits erwartungsgemäß nach Autor- bzw. Committer-Name oder -Adresse. So listen Sie zum Beispiel alle Commits, die Linus Torvalds seit Anfang 2010 gemacht hat:
$ git log --since='2010-01-01' --author='Linus Torvalds'
Hier können Sie auch nur Teile des Namens bzw. der E-Mail-Adresse angeben; die
Suche nach 'Linus' würde also dasselbe Ergebnis produzieren.
Mit --grep suchen Sie zum Beispiel nach Schlagwörtern oder
Satzteilen in der Commit-Nachricht, etwa nach allen Commits, in denen
das Wort „fix“ vorkommt (ohne die Groß- und Kleinschreibung
zu beachten):
$ git log -i --grep=fix
Die Option -i (bzw. --regexp-ignore-case) bewirkt, dass
git log die Groß- und Kleinschreibung des Musters ignoriert
(funktioniert auch in Verbindung mit --author und
--committer).
Alle drei Optionen behandeln die Werte – wie grep auch – als reguläre Ausdrücke (siehe die Man-Page regex(7)). Durch
-E und -F wird das Verhalten der
Optionen analog zu egrep und fgrep umgestellt:
erweiterte reguläre Ausdrücke zu verwenden bzw. nach dem literalen
Suchterm (dessen spezielle Zeichen ihre Bedeutung verlieren) zu suchen.
Tipp
Um nach Änderungen zu suchen, verwenden Sie das sog. Pickaxe-Tool
(„Spitzhacke“). So finden Sie Commits, in deren Diff ein bestimmter
regulärer Ausdruck vorkommt („grep für Diffs“):
$ git log -p -G<regex>
Der <regex> ist direkt, d.h. ohne Leerzeichen, nach der
Pickaxe-Option -G anzugeben. Die Option --pickaxe-all bewirkt, dass
alle Veränderungen des Commits aufgelistet werden, nicht nur
diejenigen, die die gesuchte Änderung enthalten.
Beachten Sie, dass in früheren Git-Versionen für diese Operation die
Option -S zuständig war, die allerdings einen Unterschied zu
-G aufweist: Sie findet nur die Commits, die die Anzahl der
Vorkommnisse des Musters ändern – insbesondere werden
Code-Verschiebungen, also Entfernen und Hinzufügen an anderer Stelle in
einer Datei, nicht gefunden.
Mit diesen Werkzeugen gerüstet, können Sie nun selbst Massen von Commits bändigen. Geben Sie nur entsprechend viele Kriterien an, um die Anzahl der Commits zu verringern.
Bisher haben wir lediglich Kommandos betrachtet, die nur einen
einzelnen Commit als Argument fordern, explizit identifiziert durch
seine Commit-ID oder implizit durch den symbolischen Namen
HEAD, der den jeweils aktuellsten Commit referenziert.
Das Kommando git show zeigt Informationen zu einem Commit an,
das Kommando git log beginnt bei einem Commit, und geht dann
so weit in der Versionsgeschichte zurück, bis der Anfang des
Repositorys (der sogenannte Root-Commit) erreicht ist.
Ein wichtiges Hilfsmittel, um eine Reihe von Commits anzugeben, sind
sogenannte Commit-Ranges der Form <commit1>..<commit2>. Da
wir bislang noch nicht mit mehreren Branches (Zweigen) arbeiten,
ist dies einfach ein Ausschnitt der Commits in einem Repository, und
zwar von <commit1> exklusive bis <commit2>
inklusive. Sofern Sie eine der beiden Grenzen weglassen, nimmt Git
dafür den Wert HEAD an.
Das Kommando git show bzw. git log -p hat bisher
immer nur den Unterschied zu dem jeweils vorherigen Commit ausgegeben.
Wollen Sie die Unterschiede mehrerer Commits einsehen, hilft
das Kommando git diff.
Das Diff-Kommando erfüllt mehrere Aufgaben. Wie bereits gesehen,
können Sie ohne weitere Angabe von Commits die Unterschiede zwischen
Working Tree und Index bzw. mit der Option --staged die
Unterschiede zwischen Index und HEAD untersuchen.
Wenn Sie dem Kommando aber zwei Commits bzw. eine Commit-Range übergeben, wird stattdessen der Unterschied zwischen diesen Commits angezeigt.
Git basiert auf einem simplen, aber äußerst mächtigen Objektmodell. Es dient dazu, die typischen Elemente eines Repositorys (Dateien, Verzeichnisse, Commits) und die Entwicklung über die Zeit abzubilden. Das Verständnis dieses Modells ist von großer Bedeutung und hilft sehr dabei, von typischen Git-Arbeitsschritten zu abstrahieren und sie so besser zu verstehen.
Im Folgenden dient uns als Beispiel wieder ein „Hello World!“-Programm, diesmal in der Programmiersprache Python.[21]

Das Projekt besteht aus der Datei hello.py sowie einer
README-Datei und einem Verzeichnis test. Führt man
das Programm mit dem Befehl python hello.py aus, erhält
man die Ausgabe: Hello World!. In dem Verzeichnis
test liegt ein simples Shell-Script, test.sh,
das eine Fehlermeldung anzeigt, sollte das Python-Programm nicht
wie erwartet den String Hello World! ausgeben.
Das Repository für dieses Projekt besteht aus den folgenden vier Commits:
$ git log --oneline
e2c67eb Kommentar fehlte
8e2f5f9 Test Datei
308aea1 README Datei
b0400b0 Erste Version
SHA-1 ist ein sicherer Hash-Algorithmus (Secure Hash
Algorithm), der eine Prüfsumme digitaler Informationen berechnet:
die SHA-1-Summe. Der Algorithmus wurde 1995 vom amerikanischen
National Institute of Standards and Technology (NIST) und der
National Security Agency (NSA) vorgestellt. SHA-1 wurde für
kryptographische Zwecke entwickelt und findet bei der
Integritätsprüfung von Nachrichten sowie als Basis für digitale
Signaturen Anwendung. Die Funktionsweise stellt Abbildung 2.3, „SHA-1-Algorithmus“ dar, wo wir die Prüfsumme von hello.py
berechnen.
Es handelt sich bei dem Algorithmus um eine mathematische Einwegfunktion, die eine Bit-Sequenz mit maximaler Länge 264-1 Bit (ca. 2 Exbibyte) auf eine Prüfsumme der Länge 160 Bit (20 Byte) abbildet. Die Prüfsumme wird üblicherweise als hexadezimale Zeichenkette der Länge 40 dargestellt. Der Algorithmus führt bei dieser Länge der Prüfsumme zu 2160 (ca. 1.5 · 1049) verschiedenen Kombinationen, und daher ist es sehr, sehr unwahrscheinlich, dass zwei Bit-Sequenzen die gleiche Prüfsumme haben. Diese Eigenschaft wird als Kollisionssicherheit bezeichnet.

Allen Bemühungen der Kryptologen zum Trotz wurden vor einigen Jahren verschiedene theoretische Angriffe auf SHA-1 bekannt, die das Erzeugen von Kollisionen mit einem erheblichen Rechenaufwand möglich machen sollen.[22] Aus diesem Grund empfiehlt das NIST heute die Verwendung der Nachfolger von SHA-1: SHA-256, SHA-384 und SHA-512, die über längere Prüfsummen verfügen und somit das Erzeugen von Kollisionen erschweren. Auf der Git-Mailingliste wurde debattiert, ob man zu einer dieser Alternativen wechseln solle, doch wurde dieser Schritt nicht als nötig erachtet.[23]
Denn obwohl ein theoretischer Angriffsvektor auf den SHA-1-Algorithmus besteht, beeinträchtigt dies nicht die Sicherheit von Git. Die Integrität eines Repositorys wird nämlich nicht vorrangig durch die Kollisionssicherheit eines Algorithmus geschützt, sondern dadurch, dass viele Entwickler identische Kopien des Repositorys haben.
Der SHA-1-Algorithmus spielt bei Git eine zentrale Rolle, da er
verwendet wird, um Prüfsummen von den im Git-Repository gespeicherten
Daten, den Git-Objekten, zu bilden. Damit sind diese leicht und
eindeutig als SHA-1-Summe ihres Inhalts zu referenzieren. Im
täglichen Umgang mit Git werden Sie meist nur SHA-1-Summen von Commits
verwenden, sog. Commit-IDs. Diese Referenz kann an viele
Git-Kommandos, wie z.B. git show und git diff,
übergeben werden. Je nach Repository müssen Sie oft nur die ersten
Zeichen einer SHA-1-Summe angeben, da ein Präfix in der Praxis
ausreicht, um einen Commit eindeutig zu identifizieren.
Alle in einem Repository gespeicherten Daten liegen als Git-Objekte vor. Man unterscheidet vier Typen:[24]
Tabelle 2.1. Git-Objekte
| Objekt | Speichert… | Referenziert andere Objekte | Entsprechung |
|---|---|---|---|
|
Blob |
Dateiinhalt |
Nein |
Datei |
|
Tree |
Blobs und Trees |
Ja |
Verzeichnis |
|
Commit |
Projekt-Zustand |
Ja, einen Tree und weitere Commits |
Snapshot/Archiv zu einem Zeitpunkt |
|
Tag |
Tag-Informationen |
Ja, ein Objekt |
Benennung wichtiger Snapshots oder Blobs |
Abbildung 2.4, „Git-Objekte“ zeigt drei Objekte aus dem
Beispielprojekt – einen Blob, einen Tree und einen
Commit.[25]
Die Darstellung der einzelnen Objekte enthält den Objekttyp, die Größe
in Byte, die SHA-1-Summe sowie den Inhalt. Der Blob enthält den Inhalt
der Datei hello.py (aber nicht den Dateinamen). Der Tree
enthält Referenzen auf je einen Blob für jede Datei in dem Projekt,
also eine für hello.py sowie eine für README,
außerdem einen Tree pro Unterverzeichnis, also in diesem Fall nur
einen einzigen für test. Die Dateien in den
Unterverzeichnissen werden separat in den jeweiligen Trees
referenziert, die diese Unterverzeichnisse abbilden.

Das Commit-Objekt enthält also genau eine Referenz auf einen Tree, und zwar auf den Tree des Projekt-Inhalts – dies ist ein Schnappschuss des Projekt-Zustands. Des weiteren enthält das Commit-Objekt eine Referenz auf dessen direkten Vorfahren sowie die Metadaten „Autor“ und „Committer“ und die Commit-Nachricht.
Viele Git-Kommandos erwarten als Argument einen Tree. Da aber z.B. ein Commit einen Tree referenziert, spricht man hier von einem sog. tree-ish, d.h. Tree-artigen Argument. Gemeint ist damit jedes Objekt, das sich zuletzt auf einen Tree auflösen lässt. In diese Kategorie fallen auch Tags (vgl. Abschnitt 3.1.3, „Tags – Wichtige Versionen markieren“). Analog bezeichnet commit-ish ein Argument, das sich auf einen Commit auflösen lässt.
Dateiinhalte werden immer in Blobs gespeichert. Trees enthalten nur Referenzen zu Blobs und anderen Trees in Form der SHA-1-Summen dieser Objekte. Ein Commit wiederum referenziert einen Tree.
Alle Git-Objekte werden in der Objektdatenbank gespeichert und sind durch ihre eindeutige SHA-1-Summe identifizierbar, d.h. Sie können ein Objekt, nachdem es gespeichert wurde, über seine SHA-1-Summe in der Datenbank finden. Dadurch funktioniert die Objektdatenbank im Prinzip wie eine große Hash-Tabelle, wo die SHA-1-Summen als Schlüssel für den gespeicherten Inhalt[26] dienen:
e2c67eb -> commit 8e2f5f9 -> commit 308aea1 -> commit b0400b0 -> commit a26b00a -> tree 6cf9be8 -> blob (README) 52ea6d6 -> blob (hello.py) c37fd6f -> tree (test) e92bf15 -> blob (test/test.sh) 5b4b58b -> tree dcc027b -> blob (hello.py) e4dc644 -> tree a347f5e -> tree
Sie sehen zunächst die vier Commits, die das Repository ausmachen,
unter anderem auch den in Abbildung 2.4, „Git-Objekte“ gezeigten
Commit e2c67eb. Darauf folgen Trees und Blobs, jeweils mit
Datei- bzw. Verzeichnisentsprechung. Sogenannte Top-Level
Trees haben keinen Verzeichnisnamen: Sie referenzieren die oberste
Ebene eines Projekts. Ein Commit referenziert immer einen Top-Level
Tree, daher gibt es davon auch vier Stück.
Die hierarchische Beziehung der oben aufgelisteten Objekte stellt Abbildung 2.5, „Hierarchische Beziehung der Git-Objekte“ dar. Sie sehen auf der linken Seite die vier Commits, die sich bereits im Repository befinden, auf der rechten Seite die referenzierten Inhalte des aktuellsten Commits (C4). So enthält jeder Commit, wie schon beschrieben, eine Referenz zu seinem direkten Vorfahren (auf den so entstehenden Graph von Commits wird weiter unten eingegangen). Dieser Zusammenhang wird durch die Pfeile, die von einem Commit zum nächsten zeigen, illustriert.
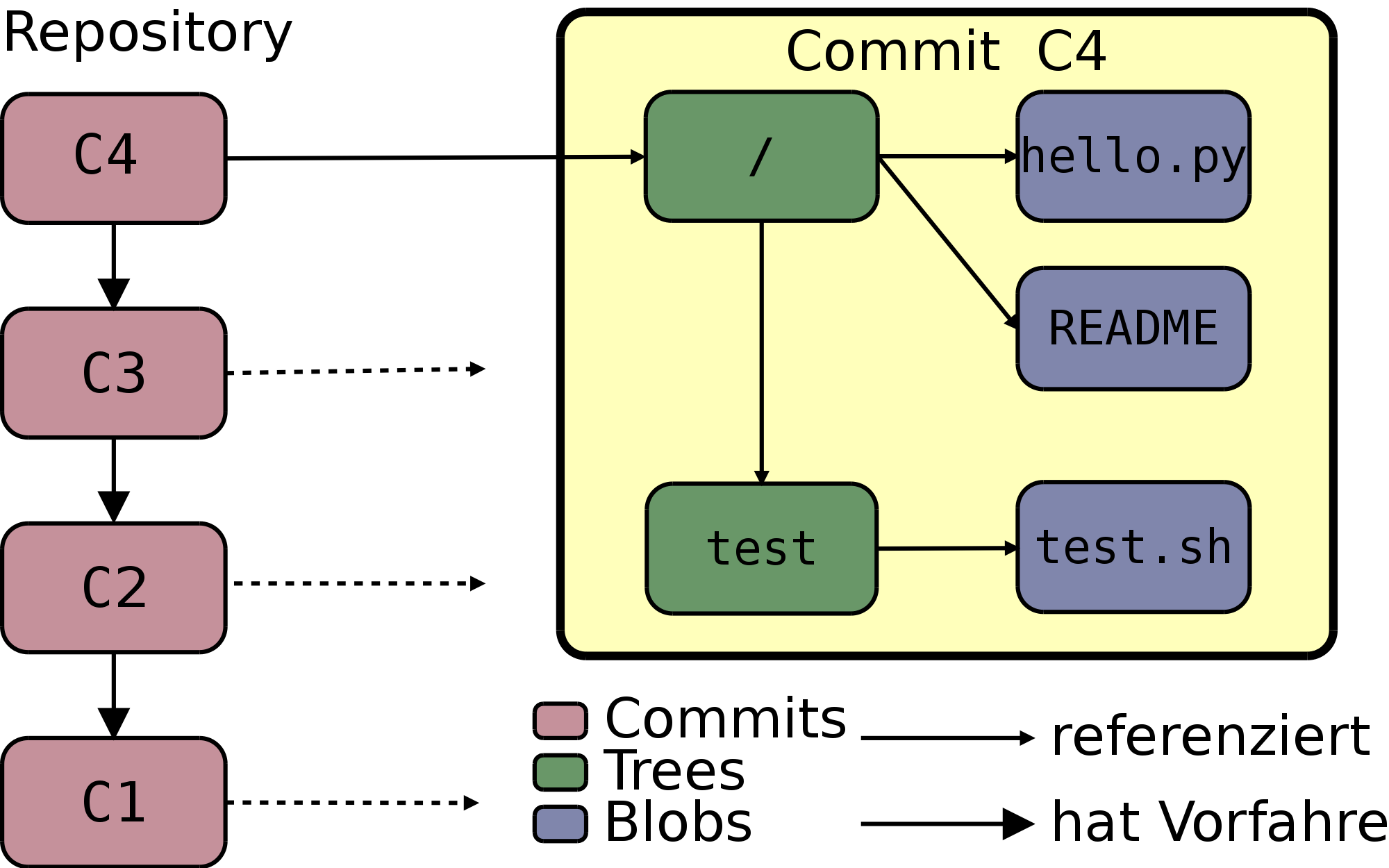
Jeder Commit referenziert den Top-Level Tree – auch der Commit
C4 in dem Beispiel. Der Top-Level Tree wiederum referenziert
die Dateien hello.py und README in Form von Blobs
sowie das Unterverzeichnis test in Form eines weiteren
Trees. Durch diesen hierarchischen Aufbau und das Verhältnis der
einzelnen Objekte zueinander ist Git in der Lage, die Inhalte eines
hierarchischen Dateisystems als Git-Objekte abzubilden und in der
Objektdatenbank zu speichern.
In einem kleinen Exkurs gehen wir darauf ein, wie man die Objektdatenbank von Git untersucht. Dafür stellt Git sogenannte Plumbing-Kommandos („Klempner-Kommandos“) zur Verfügung, eine Gruppe von Low-Level-Tools für Git, im Gegensatz zu den Porcelain-Kommandos, mit denen Sie in der Regel arbeiten. Diese Kommandos sind also nicht wichtig für Git-Anfänger, sondern sollen nur einen anderen Zugang zum Konzept der Objektdatenbank vermitteln. Für mehr Informationen siehe Abschnitt 8.3, „Eigene Git-Kommandos schreiben“.
Schauen wir uns zuerst den aktuellen Commit an. Wir verwenden dazu das
Kommando git show mit der Option --format=raw,
lassen uns also den Commit im Rohformat ausgeben, so dass alles, was
dieser Commit enthält, auch angezeigt wird.
$ git show --format=raw e2c67eb commit e2c67ebb6d2db2aab831f477306baa44036af635 tree a26b00aaef1492c697fd2f5a0593663ce07006bf parent 8e2f5f996373b900bd4e54c3aefc08ae44d0aac2 author Valentin Haenel <valentin.haenel@gmx.de> 1294515058 +0100 committer Valentin Haenel <valentin.haenel@gmx.de> 1294516312 +0100 Kommentar fehlte ...
Wie Sie sehen, werden alle Informationen aus Abbildung 2.4, „Git-Objekte“ ausgegeben: die SHA-1-Summen des Commits, des Trees und des direkten Vorfahren, außerdem Autor und Committer (inkl. Datum als Unix-Timestamp) sowie die Commit-Beschreibung. Das Kommando liefert zudem die Diff-Ausgabe zum vorherigen Commit – diese ist aber strenggenommen nicht Teil des Commits und wird daher hier ausgelassen.
Als nächstes schauen wir uns den Tree an, der von diesem Commit
referenziert wurde, und zwar mit git ls-tree, ein
Plumbing-Kommando zum Auflisten der in einem Tree gespeicherten
Inhalte. Es entspricht in etwa einem ls -l, nur eben in der
Objektdatenbank. Mit --abbrev=7 kürzen wir die
ausgegebenen SHA-1-Summen auf sieben Zeichen ab.
$ git ls-tree --abbrev=7 a26b00a 100644 blob 6cf9be8 README 100644 blob 52ea6d6 hello.py 040000 tree c37fd6f test
Analog zu Abbildung 2.4, „Git-Objekte“ enthält der von dem Commit
referenzierte Tree je einen Blob für beide Dateien sowie einen Tree
(auch: Subtree) für das test-Verzeichnis. Dessen
Inhalte können wir uns wieder mit ls-tree ansehen, da wir ja
nun die SHA-1-Summe des Trees kennen. Wie erwartet sehen Sie, dass
der test-Tree ganz genau einen Blob referenziert, und zwar
den Blob für die Datei test.sh.
$ git ls-tree --abbrev=7 c37fd6f 100755 blob e92bf15 test.sh
Zuletzt überzeugen wir uns noch davon, dass in dem Blob für
hello.py auch wirklich unser „Hello
World!“-Programm enthalten ist und dass die SHA-1-Summe
stimmt. Das Kommando git show zeigt beliebige Objekte an.
Übergeben wir die SHA-1-Summe eines Blobs, wird dessen Inhalt
ausgegeben. Zum Überprüfen der SHA-1-Summe verwenden wir das
Plumbing-Kommando git hash-object.
$ git show 52ea6d6 #! /usr/bin/env python """ Hello World! """ print 'Hello World!' $ git hash-object hello.py 52ea6d6f53b2990f5d6167553f43c98dc8788e81
Ein Hinweis für neugierige Leser: git hash-object
hello.py liefert nicht die gleiche Ausgabe wie das Unix-Kommando
sha1sum hello.py. Das liegt daran, dass nicht nur der
Dateiinhalt in einem Blob gespeichert wird. Stattdessen wird
zusätzlich der Objekttyp, in diesem Fall blob, sowie die
Größe, in diesem Fall 67 Bytes, in einem Header am Anfang des
Blobs abgespeichert. Das hash-object-Kommando errechnet also
nicht die Prüfsumme des Dateiinhalts, sondern des Blob-Objekts.
Die vier Commits, aus denen das Beispiel-Repository besteht, sind in
Abbildung 2.6, „Inhalt des Repositorys“ nochmals dargestellt, doch auf andere
Weise: Die gestrichelt umrandeten Tree- und Blob-Objekte bezeichnen
unveränderte Objekte, alle anderen wurden in dem entsprechenden Commit
neu hinzugefügt bzw. verändert. Die Leserichtung geht hier von unten
nach oben: zuunterst steht C1, der nur die Datei hello.py
enthält.
Da Trees nur Referenzen auf Blobs und weitere Trees enthalten, speichert jeder Commit zwar den Stand aller Dateien, aber nicht deren Inhalt. Normalerweise ändern sich bei einem Commit wenige Dateien. Für die neuen Dateien oder die, an denen Veränderungen vorgenommen wurden, werden nun neue Blob-Objekte (und daher auch neue Tree-Objekte) erzeugt. Die Referenzen auf die unveränderten Dateien bleiben aber die gleichen.
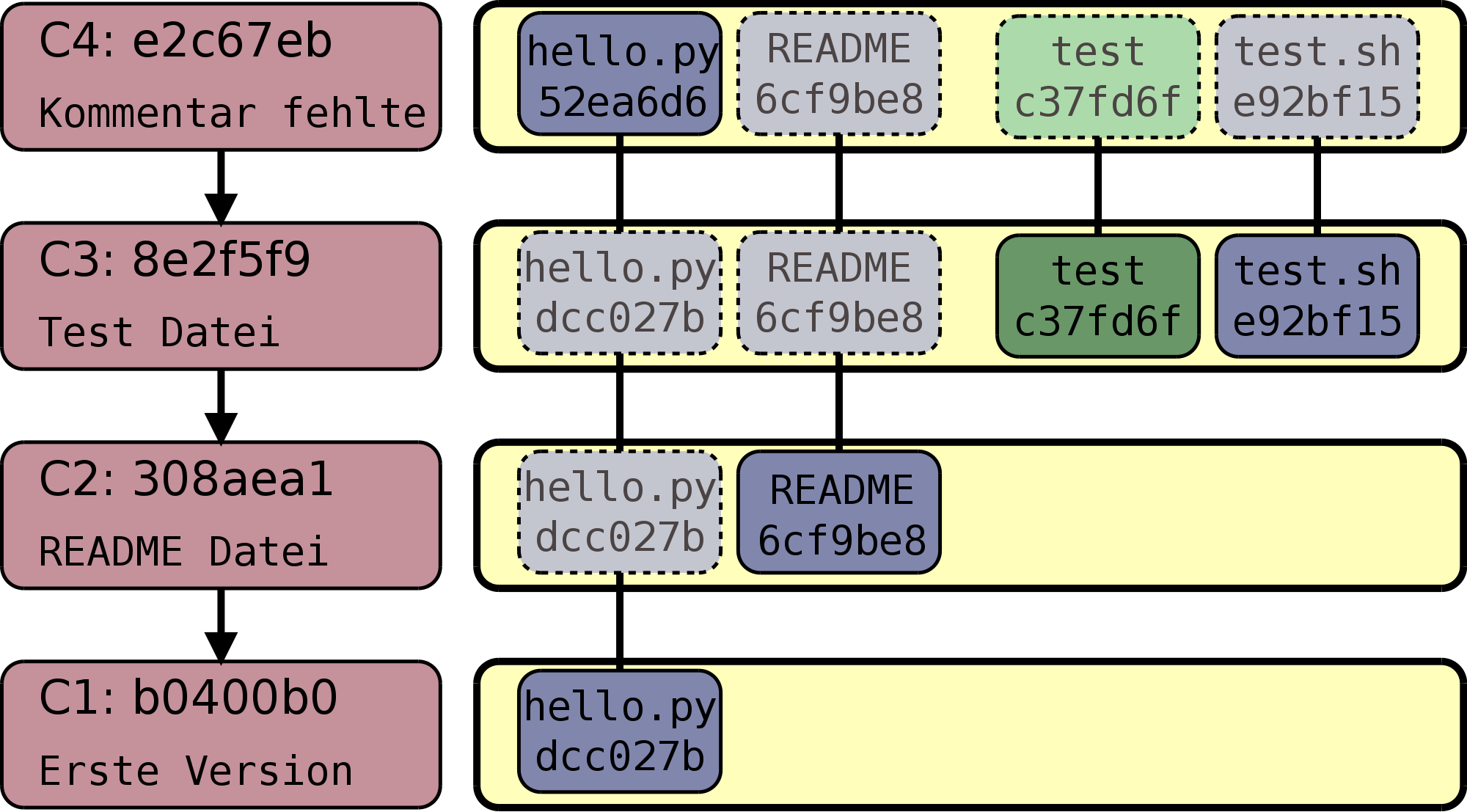
Mehr noch: Eine Datei, die zweimal existiert, existiert nur einmal in der Objektdatenbank. Der Inhalt dieser Datei liegt als Blob in der Objektdatenbank und wird an zwei Stellen von einem Tree referenziert. Diesen Effekt bezeichnet man als Deduplizierung (Deduplication): Duplikate werden nicht nur verhindert, sondern gar nicht erst möglich gemacht. Deduplizierung ist ein wesentliches Merkmal von sog. Content-Addressable File Systems, also Dateisystemen, die Dateien nur unter ihrem Inhalt kennen (wie z.B. Git, indem es einem Objekt die SHA-1-Summe seiner selbst als „Namen“ gibt).
Konsequenterweise nimmt ein Repository, in dem die gleiche, 1 MB große Datei 1000 Mal existiert, nur etwas mehr als 1 MB ein. Git muss im Wesentlichen den Blob verwalten, außerdem einen Commit und einen Tree mit 1000 Blob-Einträgen (Größe jeweils 20 Byte plus Länge des Dateinamens). Ein Checkout dieses Repositorys hingegen verbraucht ca. 1 GB Speicherplatz auf dem Dateisystem, weil Git die Deduplizierung auflöst.[27]
Mit den Befehlen git checkout und git reset stellen
Sie einen früheren Zustand so wieder her (siehe auch Abschnitt 3.2, „Versionen wiederherstellen“): Sie geben die Referenz
des entsprechenden Commits an, und Git sucht diesen aus der
Objektdatenbank heraus. Danach wird anhand der Referenz das
Tree-Objekt dieses Commits aus der Objektdatenbank herausgesucht.
Schließlich sucht Git anhand der in dem Tree-Objekt enthaltenen
Referenzen alle weiteren Tree- und Blob-Objekte aus der
Objektdatenbank heraus und repliziert sie als Verzeichnisse und
Dateien auf das Dateisystem. Somit kann genau der Projektzustand, der
damals mit dem Commit abgespeichert wurde, wiederhergestellt werden.
Da jeder Commit seine direkten Vorfahren speichert, entsteht eine Graph-Struktur. Genauer gesagt erzeugt die Anordnung der Commits einen gerichteten, azyklischen Graphen (Directed Acyclic Graph, DAG). Ein Graph besteht aus zwei Kernelementen: den Knoten und den Kanten, die diese Knoten verbinden. In einem gerichteten Graphen zeichnen sich die Kanten zusätzlich durch eine Richtung aus, das heißt, wenn Sie den Graphen ablaufen, so können Sie, um von einem Knoten zum nächsten zu gelangen, nur diejenigen Kanten verwenden, die in die entsprechende Richtung zeigen. Die azyklische Eigenschaft schließt aus, dass man auf irgendeinem Weg durch den Graphen von einem Knoten erneut zu diesem zurück finden kann. Man kann sich also nicht im Kreis bewegen.[28]
Tipp
Die meisten Git-Kommandos dienen dazu, den Graphen zu manipulieren: um Knoten hinzuzufügen/zu entfernen oder die Relation der Knoten untereinander zu ändern. Sie wissen, dass Sie eine fortgeschrittene Git-Kompetenz erreicht haben, wenn Sie dieses eher abstrakte Konzept verinnerlicht haben und beim täglichen Arbeiten mit Branches stets an den dahinterliegenden Graphen denken. Das Verständnis von Git auf dieser Ebene ist die erste und einzige wirkliche Hürde, um Git sicher im Alltag zu meistern.
Die Graph-Struktur ergibt sich aus dem Objektmodell, weil jeder Commit seinen direkten Vorfahren (bei einem Merge-Commit evtl. auch mehrere) kennt. Die Commits bilden die Knoten dieses Graphen – die Referenzen auf Vorfahren die Kanten.
Einen beispielhaften Graphen sehen Sie in Abbildung 2.7, „Ein Commit-Graph“. Er besteht aus mehreren Commits, die eingefärbt sind, um deren Zugehörigkeit zu verschiedenen Entwicklungssträngen (Branches) leichter voneinander zu unterscheiden. Zuerst wurden die Commits A, B, C und D gemacht. Sie bilden den Hauptentwicklungszweig. Commits E und F enthalten eine Feature-Entwicklung, die mit Commit H in den Hauptzweig übernommen wurde. Commit G ist ein einzelner Commit, der noch nicht in den Hauptentwicklungszweig integriert wurde.
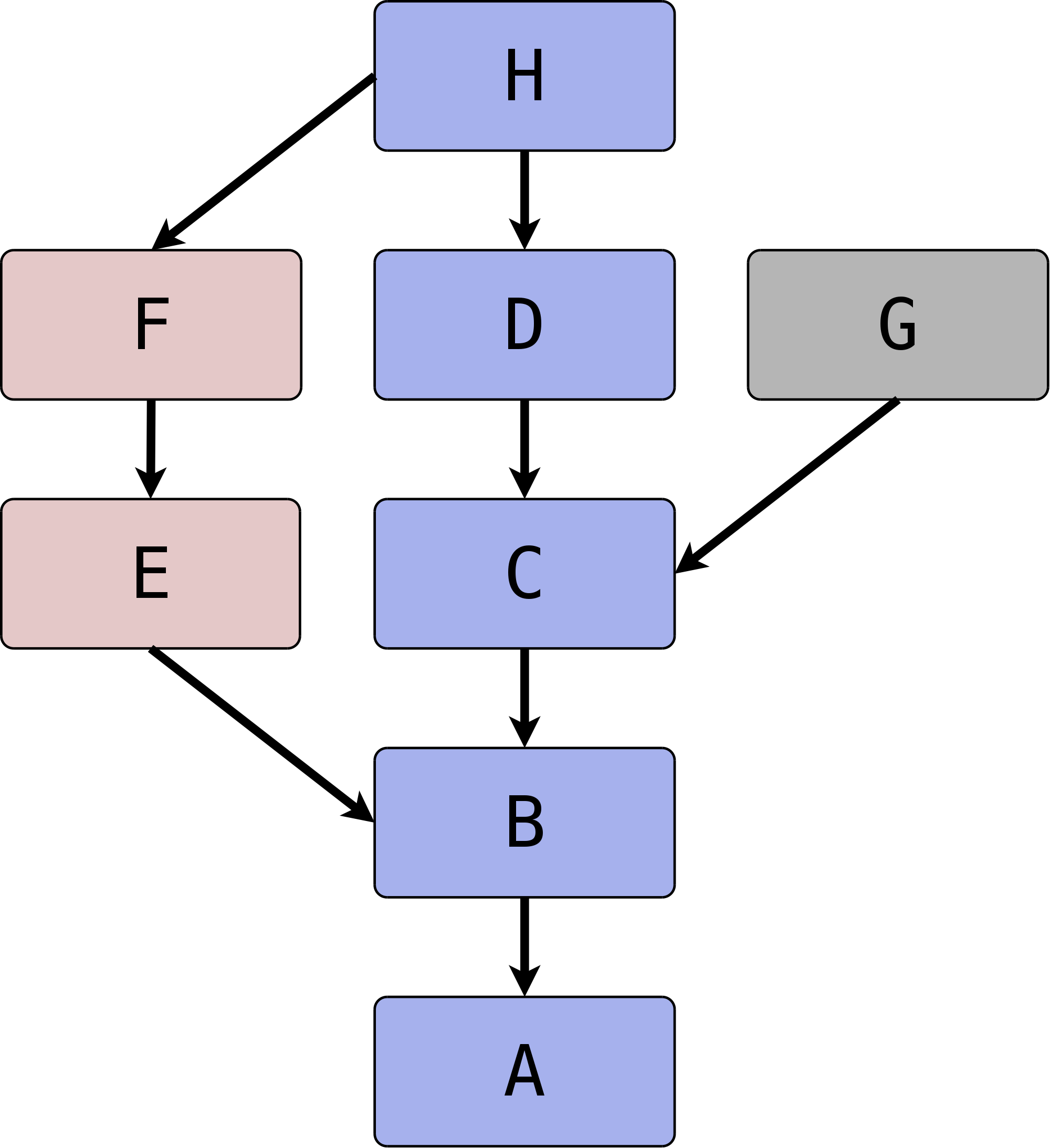
Ein Resultat der Graph-Struktur ist die kryptographisch gesicherte Integrität eines Repositorys. Git referenziert durch die SHA-1-Summe eines Commits nicht nur die Inhalte der Projektdateien zu einem bestimmten Zeitpunkt, sondern außerdem alle bis dahin ausgeführten Commits und deren Relation untereinander, also die vollständige Versionsgeschichte.
Das Objektmodell macht dies möglich: Jeder Commit speichert eine Referenz auf seine Vorfahren. Diese Referenzen fließen wiederum in die Berechnung der SHA-1-Summe des Commits selbst ein. Sie erhalten also einen anderen Commit, wenn Sie einen anderen Vorgänger referenzieren.
Da der Vorgänger wiederum Vorgänger referenziert und dessen SHA-1-Summe von den Vorgängern abhängt usw., bedeutet das konkret, dass in der Commit-ID die vollständige Versionsgeschichte implizit kodiert ist. Implizit bedeutet hier: Wenn sich auch nur ein Bit eines Commits irgendwo in der Versionsgeschichte ändert, dann ist die SHA-1-Summe der darauf folgenden Commits, insbesondere des obersten, nicht mehr dieselbe. Die SHA-1-Summe sagt aber nichts Detailliertes über die Versionsgeschichte aus, sondern ist wiederum nur eine Prüfsumme derselben.
Mit einem reinen Commit-Graphen kann man aber noch nicht viel anfangen. Um einen Knoten zu referenzieren (also damit zu arbeiten), muss man dessen Namen kennen, also die SHA-1-Summe des Commits. Im täglichen Umgang verwendet man aber selten direkt die SHA-1-Summe eines Commits, sondern stattdessen symbolische Namen, sog. Referenzen, die Git auf die SHA-1-Summe auflösen kann.
Git bietet im Wesentlichen zwei Typen von Referenzen an, Branches und Tags. Das sind Zeiger in einen Commit-Graphen, die verwendet werden, um bestimmte Knoten zu markieren. Branches haben „beweglichen“ Charakter, das heißt, sie rücken weiter an die Spitze, wenn neue Commits auf dem Branch dazu kommen. Tags hingegen haben statischen Charakter und markieren wichtige Punkte im Commit-Graphen, wie z.B. Releases.
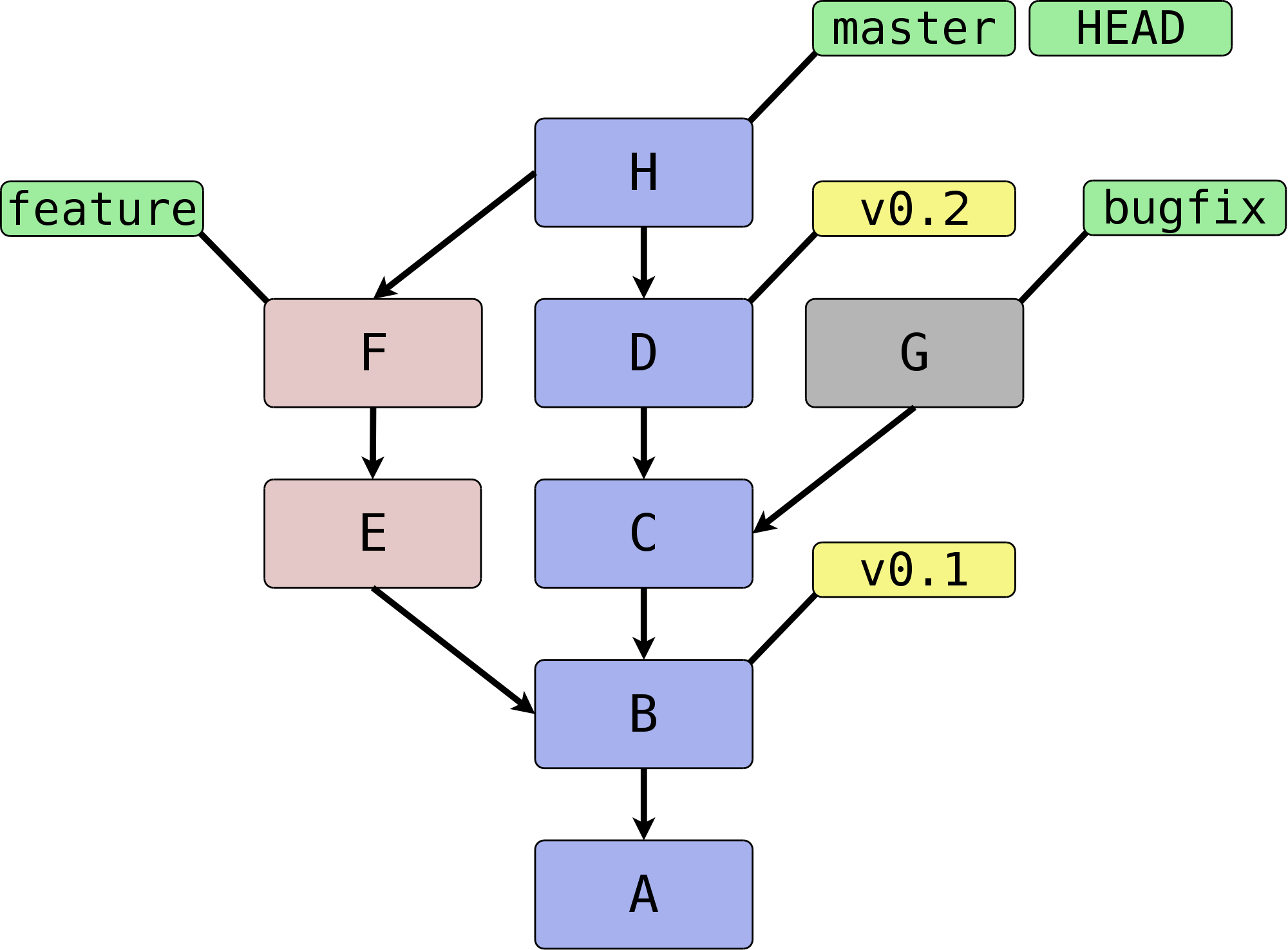
Abbildung 2.8, „Ein beispielhafter Commit-Graph mit Branches und Tags“ zeigt denselben Commit-Graphen mit den
Branches master, HEAD, feature und bugfix.
Sowie den Tags v0.1 und v0.2.
[12] Standardmäßig sind
Wörter durch ein oder mehr Leerzeichen getrennt; Sie können aber einen
anderen regulären Ausdruck angeben, um zu bestimmen, was ein Wort ist:
git diff --word-diff-regex=<regex>. Siehe hierzu auch die
Man-Page git-diff(1).
[13] Das ist eine Anweisung für
den Kernel, welches Programm zum Interpretieren des Scripts verwendet
werden soll. Typische Shebang-Zeilen sind etwa #!/bin/sh oder #!/usr/bin/perl.
[14] Genaugenommen führt die Option
-p direkt in den Patch-Mode des
Interactive-Mode von git add. Der Interactive-Mode
wird aber in der Praxis – im Gegensatz zu dem Patch-Mode – sehr
selten verwendet und ist deswegen hier nicht weiter beschrieben. Die
Dokumentation dazu finden Sie in der Man-Page git-add(1) im
Abschnitt „Interactive Mode“.
[15] Git öffnet dann
den Hunk in einem Editor; unten sehen Sie eine Anleitung, wie Sie den
Hunk editieren: Um gelöschte Zeilen (mit - präfigiert) zu löschen –
also nicht dem Index hinzuzufügen, sie aber im Working Tree zu
behalten! –, ersetzen Sie das Minuszeichen durch ein Leerzeichen (die
Zeile wird zu „Kontext“). Um +-Zeilen zu löschen, entfernen Sie
diese einfach aus dem Hunk.
[16] Sie können Hunks in der Regel
aber nicht beliebig teilen. Zumindest eine Zeile Kontext,
also eine Zeile ohne Präfix + oder -, muss
dazwischen liegen. Wollen Sie den Hunk dennoch teilen, müssen Sie
mit e für edit arbeiten.
[17] Sie können
diese Informationen u.a. in gitk sehen oder mit dem
Kommando git log --pretty=fuller.
[18] Tatsächlich erstellt Git einen neuen Commit, dessen Änderungen eine Kombination der Änderungen des alten Commits und des Index ist. Der neue Commit ersetzt dann den alten.
[19] Durch
git rm löschen Sie eine Datei mit dem nächsten Commit; sie
bleibt jedoch im Commit-Verlauf erhalten. Wie man eine Datei
vollständig, also auch aus der Versionsgeschichte, löscht, ist in
Abschnitt 8.4.1, „Sensitive Informationen nachträglich entfernen“ nachzulesen.
[20] Dieses und die folgenden Beispiele stammen aus dem Git-Repository.
[21] Sie
können das Repository, das auf den folgenden Seiten detailliert
untersucht wird, mit dem Befehl git clone
git://github.com/gitbuch/objektmodell-beispiel.git herunterladen.
[22] http://de.wikipedia.org/wiki/Secure_Hash_Algorithm, „Schwächen“.
[24] Die technische Dokumentation
bietet die Man-Page gittutorial-2(7).
[25] Das Tag-Objekt wird hier nicht dargestellt, da es für das Verständnis der Objektstruktur nicht notwendig ist. Sie finden es stattdessen in Abbildung 3.4, „Das Tag-Objekt“.
[26] Git speichert sämtliche Objekte
unterhalb von .git/objects. Man unterscheidet zwischen
Loose Objects und Packfiles. Die „losen“
Objekte speichern den Inhalt in einer Datei, deren Name der
SHA-1-Summe des Inhalts entspricht (Git speichert pro Objekt eine
Datei). Im Gegensatz dazu sind Packfiles komprimierte Archive
von vielen Objekten. Das geschieht aus Performancegründen: Nicht
nur ist die Übertragung bzw. Speicherung dieser Archive effizienter,
auch wird das Dateisystem entlastet.
[27] Intern kennt Git natürlich Mechanismen, um Blobs als Deltas anderer Blobs zu erkennen und diese platzsparend zu Packfiles zusammenzuschnüren.
[28] Diese beiden Eigenschaften gerichtet und azyklisch sind die einzig notwendige Beschränkung, die man an einen Graphen stellen muss, der Änderungen über Zeit abbildet: Weder kann man zukünftige Änderungen referenzieren (Richtung der Kanten zeigt immer in die Vergangenheit), noch kann man irgendwann an einem Punkt ankommen, von dem aus der Weg schon vorgezeichnet ist (Zirkelschluss).
