Git speichert die Objektdatenbank, die zugehörigen Referenzen usw. im
sogenannten Git-Directory, oft auch als $GIT_DIR
bezeichnet. Standardmäßig ist dies .git/. Es existiert
für jedes Git-Repository nur einmal, d.h. es werden keine
zusätzlichen .git/-Verzeichnisse in Unterverzeichnissen
angelegt.[154] Es enthält unter anderem
folgende Einträge:
-
HEAD -
Der
HEAD, siehe Abschnitt 3.1.1, „HEAD und andere symbolische Referenzen“. NebenHEADliegen ggf. auch andere wichtige symbolische Referenzen auf oberster Ebene, z.B.ORIG_HEADoderFETCH_HEAD. -
config - Die Konfigurationsdatei des Repositorys, siehe Abschnitt 1.3, „Git konfigurieren“.
-
hooks/ - Enthält die für dieses Repository gesetzten Hooks, siehe Abschnitt 8.2, „Hooks“.
-
index - Der Index bzw. Stage, siehe Abschnitt 2.1.1, „Index“.
-
info/ - Zusätzliche Repository-Informationen, z.B. zu ignorierende Muster (siehe Abschnitt 4.4, „Dateien ignorieren“) und auch Grafts (siehe Abschnitt 8.4.3, „Grafts: Nachträgliche Merges“). Sie können eigene Informationen dort ablegen, wenn andere Tools damit umgehen können (siehe z.B. der Abschnitt über Caching von CGit, Abschnitt 7.5.4, „Caching ausnutzen“).
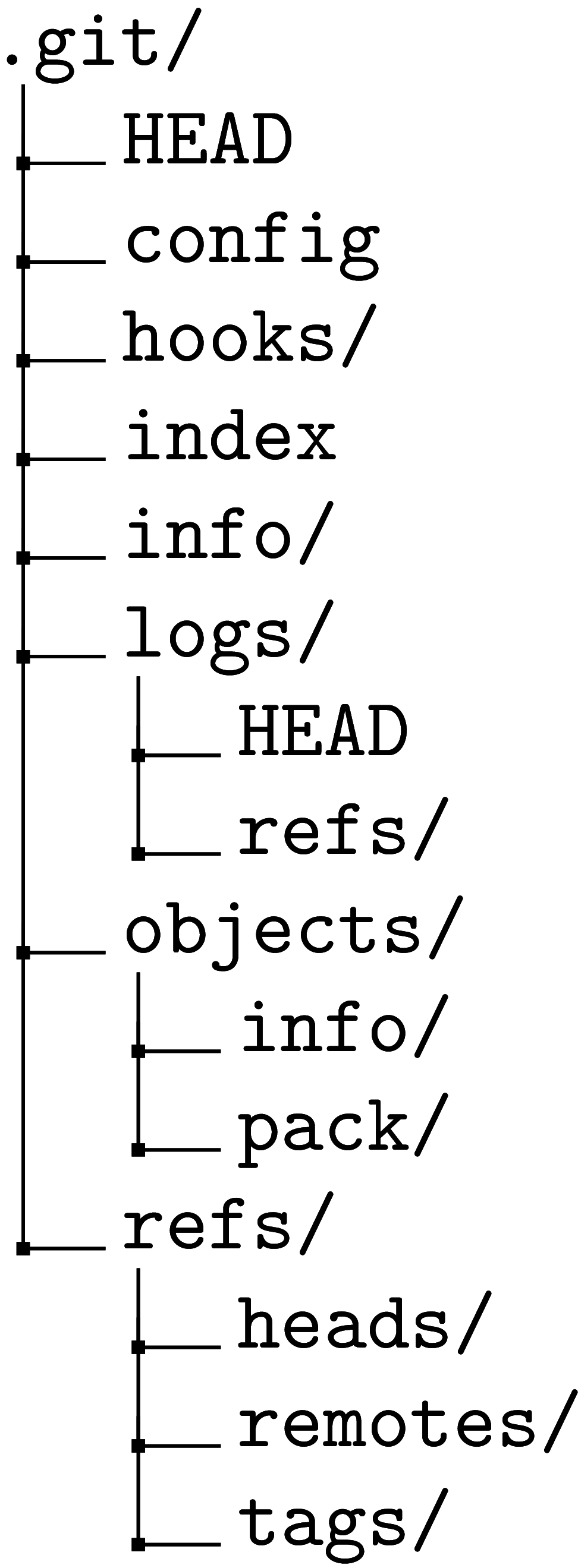
-
logs/ -
Protokoll der Veränderungen an Referenzen; zugänglich über
das Reflog, siehe Abschnitt 3.7, „Reflog“. Enthält eine Logdatei für jede
Referenz unter
refs/sowieHEAD. -
objects/ -
Die Objektdatenbank, siehe Abschnitt 2.2.3, „Die Objektdatenbank“. Aus
Performance-Gründen sind die Objekte in Unterverzeichnisse, die einem
Zwei-Zeichen-Präfix ihrer SHA-1-Summe entsprechen, einsortiert (der
Commit
0a7ba55...liegt also unter0a/7ba55...). Im Unterverzeichnispack/finden Sie die Packfiles und zugehörigen Indizes, die u.a. von der Garbage-Collection (s.u.) erstellt wird. Im Unterverzeichnisinfo/legt Git bei Bedarf eine Auflistung vorhandener Packfiles ab. -
refs/ -
Alle Referenzen, unter anderem Branches in
refs/heads/, siehe Abschnitt 3.1.1, „HEAD und andere symbolische Referenzen“, Tags inrefs/tags/, siehe Abschnitt 3.1.3, „Tags – Wichtige Versionen markieren“ sowie Remote-Tracking-Branches unterrefs/remotes/, siehe Abschnitt 5.2.2, „Remote-Tracking-Branches“.
Eine ausführliche technische Beschreibung finden Sie in der
Man-Page gitrepository-layout(5).
Wie beispielsweise schon in Abschnitt 3.1.2, „Branches verwalten“ erwähnt, sind Commits, die nicht mehr referenziert werden (sei es durch Branches oder andere Commits), nicht mehr zu erreichen. In der Regel ist das der Fall, wenn Sie einen Commit löschen wollten (oder Commits mit Rebase umgebaut haben). Git löscht diese nicht sofort aus der Objektdatenbank, sondern belässt sie per Default zwei Wochen dort, auch wenn sie nicht mehr erreichbar sind.
Intern verwendet Git die Kommandos prune,
prune-packed, fsck, repack u.a.
Allerdings werden die Tools mit entsprechenden Optionen
automatisch von der Garbage Collection („Müllabfuhr“)
ausgeführt: git gc. Folgende Aufgaben erledigt das Tool:
- Dangling und Unreachable Objects löschen. Diese entstehen bei diversen Operationen und können in der Regel nach einiger Zeit gelöscht werden, um Platz zu sparen (Default: nach zwei Wochen).
-
Loose Objects neu packen. Git verwendet sog.
Packfiles, um mehrere Git-Objekte zusammenzuschnüren. (Dann
existiert nicht mehr eine Datei unterhalb von
.git/objects/pro Blob, Tree und Commit – diese werden in einer großen, zlib-komprimierten Datei zusammengefasst). - Existierende Packfiles nach alten (unerreichbaren) Objekten durchsuchen und die Packfiles entsprechend „ausdünnen“. Ggf. werden mehrere kleine Packfiles zu großen kombiniert.
- Referenzen packen. Es entstehen sog. Packed Refs, siehe auch Abschnitt 3.1, „Referenzen: Branches und Tags“.
- Alte Reflog-Einträge löschen. Das geschieht per Default nach 90 Tagen.
- Alte Konflikt-Resolutionen (siehe Rerere, Abschnitt 3.4.2, „rerere: Reuse Recorded Resolution“) werden entsorgt (15/60 Tage Haltezeit für ungelöst/gelöst).
Die Garbage Collection kennt drei Modi: automatisch, normal und
aggressiv. Den automatischen Modus rufen Sie per git gc
--auto auf – der Modus überprüft, ob es wirklich eklatante
Mängel im Repository gibt. Was „eklatant“ bedeutet, ist
konfigurierbar. Über folgende Konfigurationseinstellungen können Sie
(global oder per Repository) bestimmen, ab wann, d.h. ab welcher
Anzahl „kleiner“ Dateien der automatische Modus aufräumt,
also diese in große Archive zusammenfasst.
-
gc.auto(Default: 6700 Objekte) - Objekte zu einem Packfile zusammenfassen
-
gc.autopacklimit(Default: 50 Packs) - Packs zu einem großen Packfile zusammenfassen
Der automatische Modus wird häufig aufgerufen, u.a. von
receive-pack und rebase (interaktiv). In den
meisten Fällen tut der automatische Modus allerdings nichts, da die
Defaults sehr konservativ sind. Wenn doch, sieht das so aus:
$ git gc --auto
Auto packing the repository for optimum performance. You may also
run "git gc" manually. See "git help gc" for more information.
...
Sie sollten entweder die Schwellen, ab denen die automatische Garbage
Collection greift, deutlich herabsetzen, oder von Zeit zu Zeit
git gc aufrufen. Dies hat einen offensichtlichen Vorteil,
nämlich dass Plattenplatz gespart wird:
$ du -sh .git 20M .git $ git gc Counting objects: 3726, done. Compressing objects: 100% (1639/1639), done. Writing objects: 100% (3726/3726), done. Total 3726 (delta 1961), reused 2341 (delta 1279) Removing duplicate objects: 100% (256/256), done. $ du -sh .git 6.3M .git
Einzelne Objekte unterhalb von .git/objects/ wurden zu einem
Packfile zusammengefasst:
$ ls -lh .git/objects/pack/pack-a97624dd23<...>.pack -r-------- 1 feh feh 4.6M Jun 1 10:20 .git/objects/pack/pack-a97624dd23<...>.pack $ file .git/objects/pack/pack-a97624dd23<...>.pack .git/objects/pack/pack-a97624dd23<...>.pack: Git pack, version 2, 3726 objects
Sie können sich per git count-objects ausgeben lassen, aus
wie vielen Dateien die Objektdatenbank besteht. Hier nebeneinander vor
und nach dem obigen Packvorgang:
$ git count-objects -v
count: 1905 count: 58
size: 12700 size: 456
in-pack: 3550 in-pack: 3726
packs: 7 packs: 1
size-pack: 4842 size-pack: 4716
prune-packable: 97 prune-packable: 0
garbage: 0 garbage: 0
Nun ist Plattenplatz billig, ein auf 30% komprimiertes Repository also kein großer Gewinn. Der Performance-Gewinn ist allerdings nicht zu verachten. In der Regel zieht ein Objekt (z.B. ein Commit) weitere Objekte nach sich (Blobs, Trees). Wenn Git also pro Objekt eine Datei öffnen muss (bei n verwalteten Dateien also mindestens n Blob-Objekte), dann sind dies n Lese-Vorgänge auf dem Dateisystem.
Packfiles haben zwei wesentliche Vorteile: Erstens legt Git zu jedem Packfile eine Indizierung an, die angibt, welches Objekt in welchem Offset der Datei zu finden ist. Zusätzlich hat die Packroutine noch eine gewisse Heuristik um die Objektplatzierung innerhalb der Datei zu optimieren (so dass bspw. ein Tree-Object und die davon referenzierten Blob-Objekte „nah“ beieinander liegen). Dadurch kann Git einfach das Packfile in den Speicher mappen (Stichwort: „sliding mmap“). Die Operation „suche Objekt X“ ist dann nichts weiter als eine Lookup-Operation im Pack-Index und ein entsprechendes Auslesen der Stelle im Packfile, d.h. im Speicher. Dies entlastet das Datei- und Betriebssystem erheblich.
Der zweite Vorteil der Packfiles liegt in der Delta-Kompression. So
werden Objekte möglichst als Deltas (Veränderungen)
anderer Objekte gespeichert.[155] Das spart Speicherplatz, ermöglicht aber
andererseits auch Kommandos wie git blame,
„kostengünstig“, also ohne großen Rechenaufwand, Kopien
von Code-Stücken zwischen Dateien zu entdecken.
Der aggressive Modus sollte nur in begründeten Ausnahmefällen eingesetzt werden.[156]
Tipp
Lassen Sie auf Ihren öffentlich zugänglichen Repositories auch
regelmäßig, z.B. per Cron, ein git gc laufen. Commits werden über
das Git-Protokoll immer als Packfiles übertragen, die on demand, das
heißt zum Zeitpunkt des Abrufs, erzeugt werden. Wenn das gesamte
Repository schon als ein großes Packfile vorliegt, können Teile daraus
schneller extrahiert werden, und ein kompletter Clone des Repositorys
benötigt keine zusätzlichen Rechenoperationen (es muss kein riesiges
Packfile gepackt werden). Eine regelmäßige Garbage Collection kann
also die Auslastung Ihres Servers senken, außerdem wird der
Clone-Vorgang der Nutzer beschleunigt.
Ist das Repository besonders groß, kann es bei einem git clone sehr
lange dauern, bis der Server alle Objekte gezählt hat. Dies können Sie
beschleunigen, indem Sie regelmäßig per Cron-Job git repack -A -d -b
aufrufen: Git erstellt dann zusätzlich zu den Pack-Files eine
Bitmap-Datei, die diesen Vorgang um ein bis zwei Größenordnungen
beschleunigt.
[154] Da ein Bare-Repository
(siehe Abschnitt 7.1.3, „Bare Repositories – Repositories ohne Working Tree“) keinen Working Tree besitzt,
bilden die Inhalte, die normalerweise in .git liegen, die
oberste Ebene in der Verzeichnisstruktur, und es gibt kein
zusätzliches Verzeichnis .git.
[155] Das ist nicht zu verwechseln mit Versionskontrollsystemen, die inkrementelle Versionen einer Datei speichern. Innerhalb von Packfiles werden die Objekte unabhängig von ihrem semantischen Zusammenhang, d.h. speziell ihrer zeitlichen Abfolge, gepackt.
[156] Eine ausführliche Auseinandersetzung mit dem Thema finden Sie unter http://metalinguist.wordpress.com/2007/12/06/the-woes-of-git-gc-aggressive-and-how-git-deltas-work/
