Das folgende Kapitel stellt alle wesentlichen Techniken vor, die Sie im täglichen Umgang mit Git einsetzen werden. Neben einer genaueren Beschreibung des Index und wie man alte Versionen wiederherstellt, liegt der Fokus auf der effektiven Arbeit mit Branches.
„Branch“ und „Merge“ sind im CVS-/SVN-Umfeld für Neulinge oft ein Buch mit sieben Siegeln, für Könner regelmäßig Grund zum Haare raufen. In Git sind das Abzweigen im Entwicklungszyklus (Branching) und das anschließende Wiederzusammenführen (Merging) alltäglich, einfach, transparent und schnell. Es kommt häufig vor, dass ein Entwickler an einem Tag mehrere Branches erstellt und mehrere Merges durchführt.
Das Tool Gitk ist hilfreich, um bei mehreren Branches nicht den
Überblick zu verlieren. Mit
gitk --all zeigen Sie alle Branches an. Das Tool visualisiert den im vorigen Abschnitt
erläuterten Commit-Graphen. Jeder Commit stellt eine Zeile dar.
Branches werden als grüne Labels, Tags als gelbe Zeiger dargestellt.
Für weitere Informationen siehe Abschnitt 3.6.2, „Gitk“.
Abbildung 3.1. Das Beispiel-Repository aus Kapitel 2, Grundlagen in Gitk. Zur Illustration wurde der zweite Commit mit dem Tag v0.1 versehen.
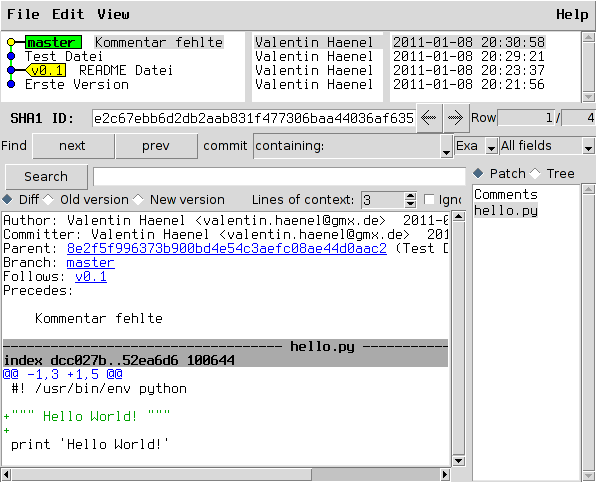
Da Branches in Git „billig“ und Merges einfach sind, können Sie es sich leisten, Branches exzessiv zu verwenden. Sie wollen etwas probieren, einen kleinen Bugfix vorbereiten oder mit einem experimentellen Feature beginnen? Für all das erstellen Sie jeweils einen neuen Branch. Sie wollen testen, ob sich ein Branch mit dem anderen verträgt? Führen Sie die beiden zusammen, testen Sie alles, und löschen Sie danach den Merge wieder und entwickeln weiter. Das ist gängige Praxis unter Entwicklern, die Git einsetzen.
Zunächst wollen wir uns mit Referenzen generell auseinandersetzen. Referenzen sind nichts weiter als symbolische Namen für die schwierig zu merkenden SHA-1-Summen von Commits.
Diese Referenzen liegen in .git/refs/. Der Name einer
Referenz wird anhand des Dateinamens, das Ziel anhand des Inhalts der
Datei bestimmt. Der Master-Branch, auf dem Sie schon die ganze Zeit
arbeiten, sieht darin zum Beispiel so aus:
$ cat .git/refs/heads/master
89062b72afccda5b9e8ed77bf82c38577e603251
Tipp
Wenn Git sehr viele Referenzen verwalten muss, liegen diese nicht
zwingend als Dateien unterhalb von .git/refs/. Git erstellt
dann stattdessen einen Container, der gepackte Referenzen (Packed
Refs) enthält: Eine Zeile pro Referenz mit Name und SHA-1-Summe. Das
sequentielle Auflösen vieler Referenzen geht dann schneller.
Git-Kommandos suchen Branches und Tags in der Datei .git/packed-refs, wenn die entsprechende Datei
.git/refs/<name> nicht existiert.
Unterhalb von .git/refs/ gibt es verschiedene Verzeichnisse,
die für die „Art“ von Referenz stehen. Fundamental
unterscheiden sich diese Referenzen aber nicht, lediglich darin, wann
und wie sie angewendet werden. Die Referenzen, die Sie am häufigsten
verwenden werden, sind Branches. Sie sind unter .git/refs/heads/ gespeichert. Heads bezeichnet das,
was in anderen Systemen zuweilen auch „Tip“ genannt wird:
Den neuesten Commit auf einem Entwicklungsstrang.[29] Branches rücken weiter, wenn Sie
Commits auf einem Branch erstellen – sie bleiben also an der Spitze
der Versionsgeschichte.
Branches in Repositories anderer Entwickler (z.B. der Master-Branch
des offiziellen Repositorys), sog.
Remote-Tracking-Branches, werden unter .git/refs/remotes/ abgelegt (siehe Abschnitt 5.2.2, „Remote-Tracking-Branches“). Tags, statische
Referenzen, die meist der Versionierung dienen, liegen unter .git/refs/tags/ (siehe Abschnitt 3.1.3, „Tags – Wichtige Versionen markieren“).
Eine Referenz, die Sie selten explizit, aber ständig implizit
benutzen, ist HEAD. Sie referenziert meist den gerade
ausgecheckten Branch, hier master:
$ cat .git/HEAD
ref: refs/heads/master
HEAD kann auch direkt auf einen Commit zeigen, wenn Sie
git checkout <commit-id> eingeben. Sie sind dann
allerdings im sogenannten Detached-Head-Modus, in dem Commits
möglicherweise verlorengehen, siehe auch
Abschnitt 3.2.1, „Detached HEAD“.
Der HEAD bestimmt, welche Dateien im Working Tree zu finden
sind, welcher Commit Vorgänger bei der Erstellung eines neuen wird,
welcher Commit per git show angezeigt wird etc. Wenn wir
hier von „dem aktuellen Branch“ sprechen, dann ist damit
technisch korrekt der HEAD gemeint.
Die simplen Kommandos log, show und diff
nehmen ohne weitere Argumente HEAD als erstes Argument an.
Die Ausgabe von git log ist gleich der von git log HEAD usw. – dies gilt für die meisten Kommandos, die auf einem
Commit operieren, wenn Sie keinen explizit angeben. HEAD ist
somit vergleichbar mit der Shell-Variable PWD, die angibt
„wo man ist“.
Wenn wir von einem Commit sprechen, dann ist es einem Kommando in der
Regel egal, ob man die Commit-ID komplett oder verkürzt angibt oder
den Commit über eine Referenz, wie z.B. ein Tag oder Branch,
ansteuert. Eine solche Referenz muss aber nicht immer eindeutig sein.
Was passiert, wenn es einen Branch master gibt und ein Tag
gleichen Namens? Git überprüft, ob die folgenden Referenzen
existieren:
-
.git/<name>(meist nur sinnvoll fürHEADo.ä.) -
.git/refs/<name> -
.git/refs/tags/<name> -
.git/refs/heads/<name> -
.git/refs/remotes/<name> -
.git/refs/remotes/<name>/HEAD
Die erste gefundene Referenz nimmt Git als Treffer an. Sie sollten
also Tags immer ein eindeutiges Schema geben, um sie nicht mit
Branches zu verwechseln. So können Sie Branches direkt über den Namen
statt über heads/<name> ansprechen.
Besonders wichtig sind dafür die Suffixe ^ und ~<n>. Die Syntax
<ref>^ bezeichnet den direkten Vorfahren von <ref>. Dieser muss
aber nicht immer eindeutig sein: Wenn zwei oder mehr Branches
zusammengeführt wurden, hat der Merge-Commit mehrere direkte
Vorfahren. <ref>^ bzw. <ref>^1 bezeichnen dann den ersten
direkten Vorfahren, <ref>^2 den zweiten usw.[30] Die Syntax HEAD^^ bedeutet also „der zwei
Ebenen vorher liegende direkte Vorfahre des aktuellen
Commits“. Achten Sie darauf, dass ^ in Ihrer Shell möglicherweise
eine spezielle Bedeutung hat und Sie es durch Anführungszeichen oder
mit einem Backslash schützen müssen.
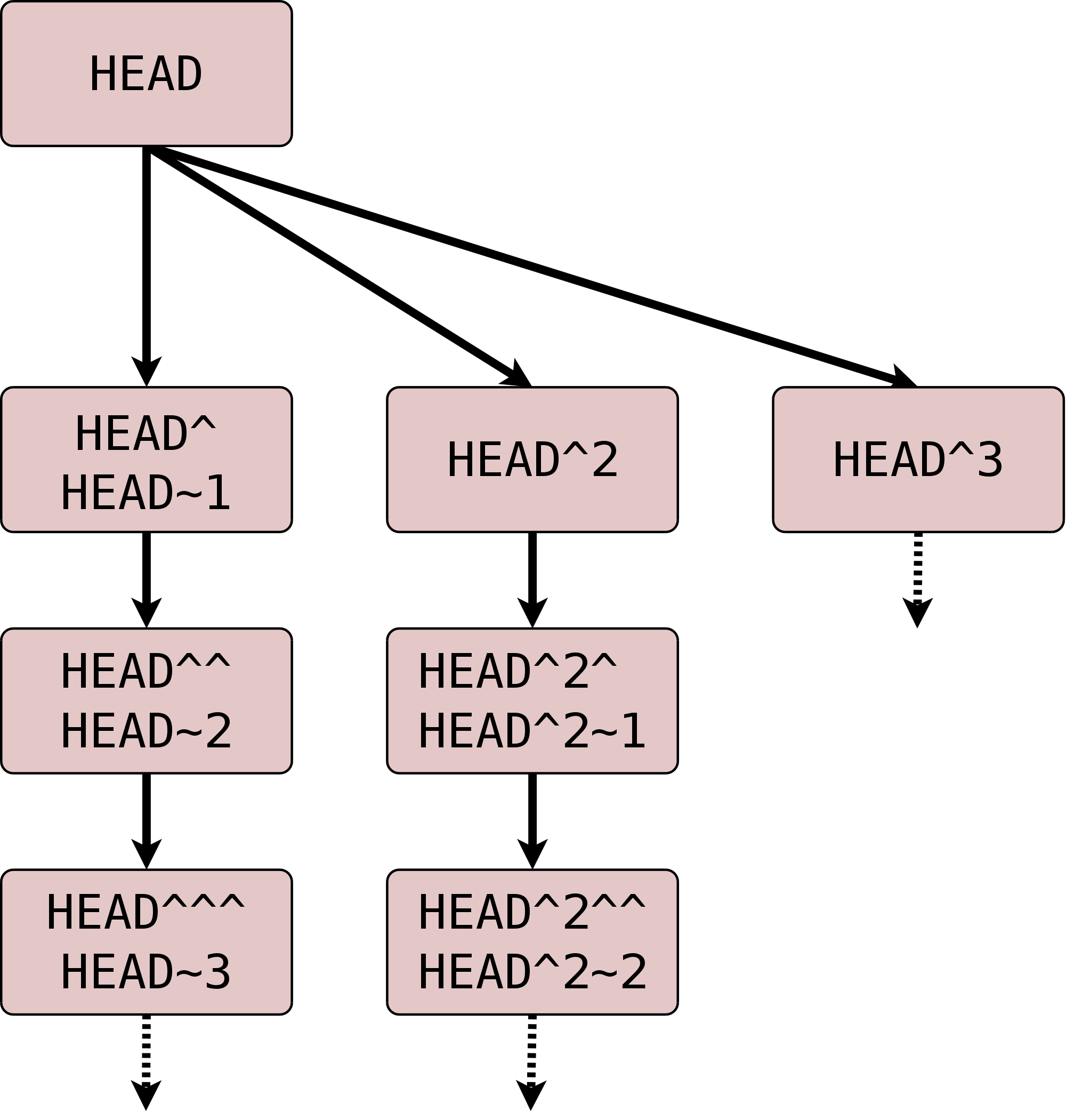
Die Syntax <ref>~<n> kommt einer
n-fachen Wiederholung von ^ gleich:
HEAD~10 bezeichnet also den zehnten direkten
Vorgänger des aktuellen Commits. Achtung: Das heißt nicht, dass
zwischen HEAD und HEAD~10 nur elf
Commits liegen: Da ^ bei einem etwaigen Merge nur dem
ersten Strang folgt, liegen zwischen den beiden Referenzen die elf
und alle durch einen Merge integrierten weiteren Commits.
Die Syntax ist übrigens in der Man-Page git-rev-parse(1) im Abschnitt
„Specifying Revisions“ dokumentiert.
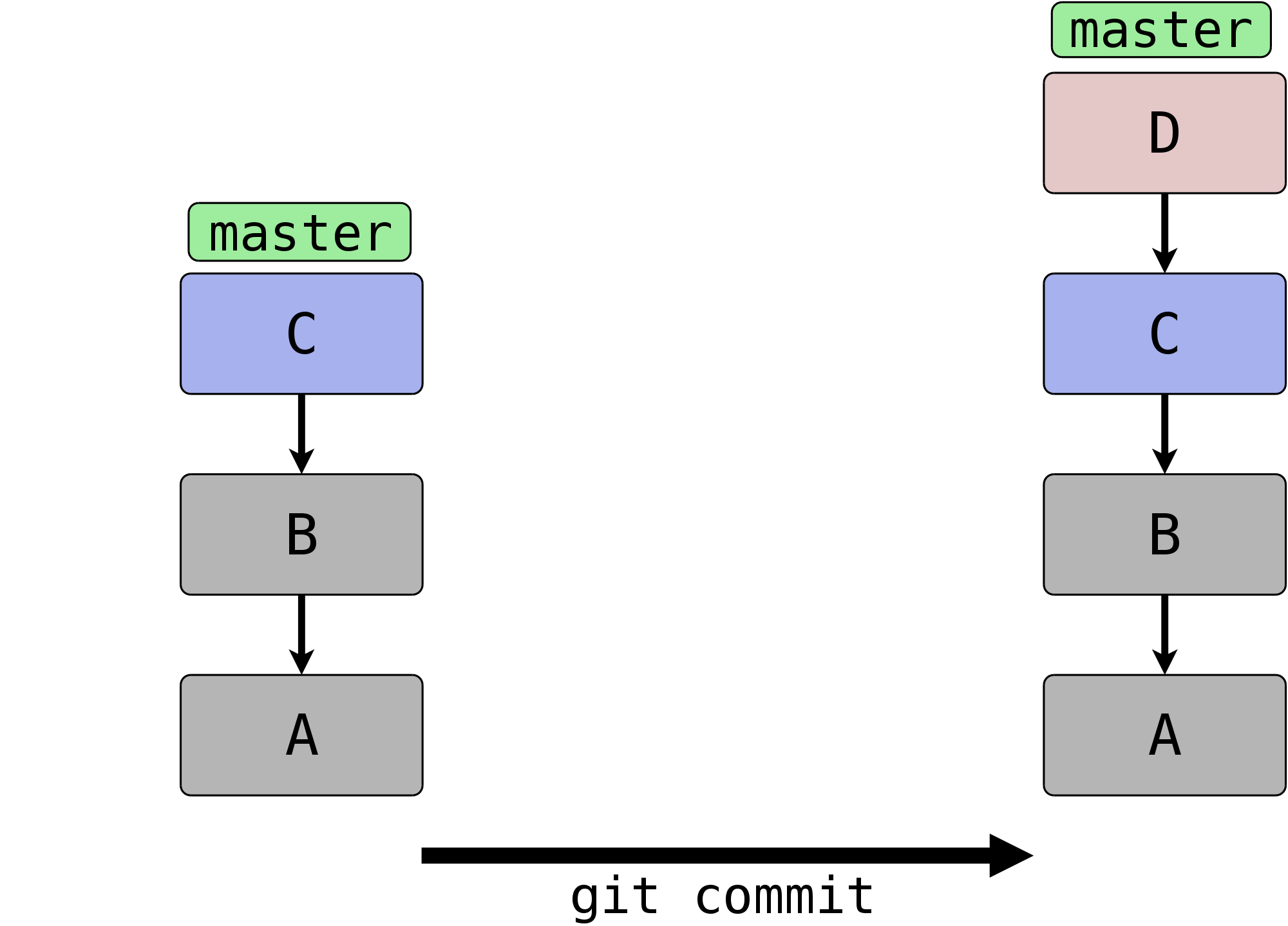
Ein Branch ist in Git im Nu erstellt. Git muss lediglich den aktuell
ausgecheckten Commit identifizieren und die SHA-1-Summe in der Datei
.git/refs/heads/<branch-name> ablegen.
$ time git branch neuer-branch
git branch neuer-branch 0.00s user 0.00s system 100% cpu 0.008 total
Das Kommando ist so schnell, weil (im Gegensatz zu anderen Systemen) keine Dateien kopiert und keine weiteren Metadaten abgelegt werden müssen. Informationen über die Struktur der Versionsgeschichte sind immer aus dem Commit, den ein Branch referenziert, und seinen Vorfahren ableitbar.
Hier eine Übersicht der wichtigsten Optionen:
-
git branch [-v] -
Listet lokale Branches auf. Dabei ist der aktuell ausgecheckte Branch mit einem Sternchen markiert. Mit
-vwerden außerdem die Commit-IDs, auf die die Branches zeigen, sowie die erste Zeile der Beschreibung der entsprechenden Commits angezeigt.$ git branch -v maint 65f13f2 Start 1.7.5.1 maintenance track * master 791a765 Update draft release notes to 1.7.6 next b503560 Merge branch 'master' into next pu d7a491c Merge branch 'js/info-man-path' into pu -
git branch <branch> [<ref>] -
Erstellt einen neuen
Branch
<branch>, der auf Commit<ref>zeigt (<ref>kann die SHA-1-Summe eines Commits sein, ein anderer Branch usw.). Wenn Sie keine Referenz angeben, ist diesHEAD, der aktuelle Branch. -
git branch -m <neuer-name> -
git branch -m <alter-name> <neuer-name>In der ersten Form wird der aktuelle Branch in
<neuer-name>umbenannt. In der zweiten Form wird<alter-name>in<neuer-name>umbenannt. Das Kommando schlägt fehl, wenn dadurch ein anderer Branch überschrieben würde.$ git branch -m master fatal: A branch named 'master' already exists.Wenn Sie einen Branch umbenennen, gibt Git keine Meldung aus. Sie können also hinterher überprüfen, dass die Umbenennung erfolgreich war:
$ git branch * master test $ git branch -m test pu/feature $ git branch * master pu/feature
-
git branch -M ... -
Wie
-m, nur dass ein Branch auch umbenannt wird, wenn dadurch ein anderer überschrieben wird. Achtung: Dabei können Commits des überschriebenen Branches verlorengehen! -
git branch -d <branch> -
Löscht
<branch>. Sie können mehrere Branches gleichzeitig angeben. Git weigert sich, einen Branch zu löschen, wenn er noch nicht komplett in seinen Upstream-Branch, oder, falls dieser nicht existiert, inHEAD, also den aktuellen Branch, integriert ist. (Mehr über Upstream-Branches finden Sie in Abschnitt 5.3.2, „git pull“.) -
git branch -D ... - Löscht einen Branch, auch wenn er Commits enthält, die noch nicht in den Upstream- oder aktuellen Branch integriert wurden. Achtung: Diese Commits können möglicherweise verlorengehen, wenn sie nicht anders referenziert werden.
Branches wechseln Sie mit git checkout <branch>. Wenn Sie
einen Branch erstellen und direkt darauf wechseln
wollen, verwenden Sie git checkout -b <branch>. Das Kommando
ist äquivalent zu git branch <branch> && git checkout
<branch>.
Was passiert bei einem Checkout? Jeder Branch referenziert einen
Commit, der wiederum einen Tree referenziert, also das Abbild einer
Verzeichnisstruktur. Ein git checkout <branch> löst nun die
Referenz <branch> auf einen Commit auf und repliziert den
Tree des Commits auf den Index und auf den Working Tree (d.h. auf
das Dateisystem).
Da Git weiß, in welcher Version Dateien aktuell in Index und Working Tree vorliegen, müssen nur die Dateien, die sich auf dem aktuellen und dem neuen Branch unterscheiden, ausgecheckt werden.
Git macht es Anwendern schwer, Informationen zu verlieren. Daher wird ein Checkout eher fehlschlagen als eventuell nicht abgespeicherte Änderungen in einer Datei überschreiben. Das passiert in den folgenden beiden Fällen:
-
Der Checkout würde eine Datei im Working Tree
überschreiben, in der sich Änderungen befinden. Git gibt folgende
Fehlermeldung aus:
error: Your local changes to the following files would be overwritten by checkout: datei. -
Der Checkout würde eine ungetrackte Datei überschreiben,
d.h. eine Datei, die nicht von Git verwaltet wird. Git bricht dann mit
der Fehlermeldung ab:
error: The following untracked working tree files would be overwritten by checkout: datei.
Liegen allerdings Änderungen im Working Tree oder Index vor, die mit beiden Branches verträglich sind, übernimmt ein Checkout diese Änderungen. Das sieht dann z.B. so aus:
$ git checkout master A neue-datei.txt Switched to branch master
Das bedeutet, dass die Datei neue-datei.txt hinzugefügt
wurde, die auf keinem der beiden Branches existiert. Da hier also
keine Informationen verlorengehen können, wird die Datei einfach
übernommen. Die Meldung: A neue-datei.txt erinnert Sie, um
welche Dateien Sie sich noch kümmern sollten. Dabei steht A
für hinzugefügt (added), D für gelöscht (deleted)
und M für geändert (modified).
Wenn Sie ganz sicher sind, dass Sie Ihre Änderungen nicht mehr
brauchen, können Sie per git checkout -f die Fehlermeldungen
ignorieren und den Checkout trotzdem ausführen.
Wenn Sie sowohl die Änderungen behalten als auch den Branch wechseln
wollen (Beispiel: Arbeit unterbrechen und auf einem anderen Branch
einen Fehler korrigieren), dann hilft git stash (Abschnitt 4.5, „Veränderungen auslagern – git stash“).
Sie können Branches prinzipiell fast beliebig benennen. Ausnahmen sind
aber Leerzeichen, einige Sonderzeichen mit spezieller Bedeutung für Git
(z.B. *, ^, :, ~), sowie zwei aufeinanderfolgende Punkte
(..) oder ein Punkt am Anfang des Namens.[31]
Sinnvollerweise sollten Sie Branch-Namen immer komplett in
Kleinbuchstaben angeben. Da Git Branch-Namen unter
.git/refs/heads/ als Dateien verwaltet, ist die Groß- und
Kleinschreibung wesentlich.
Sie können Branches in „Namespaces“ gruppieren, indem Sie
als Separator einen / verwenden. Branches, die mit der
Übersetzung einer Software zu tun haben, können Sie dann z.B. i18n/german, i18n/english etc. nennen. Auch können
Sie, wenn sich mehrere Entwickler ein Repository teilen,
„private“ Branches unter <username>/<topic>
anlegen. Diese Namespaces werden durch eine Verzeichnisstruktur
abgebildet, so dass dann unter .git/refs/heads/ ein
Verzeichnis <username>/ mit der Branch-Datei <topic>
erstellt wird.
Der Hauptentwicklungszweig Ihres Projekts sollte immer master
heißen. Bugfixes werden häufig auf einem Branch maint (kurz
für „maintenance“) verwaltet. Das nächste Release wird
meist auf next vorbereitet. Features, die sich noch in einem
experimentellen Zustand befinden, sollten in pu (für
„proposed updates“) entwickelt werden oder in
pu/<feature>. Eine detailliertere Beschreibung, wie Sie mit
Branches die Entwicklung strukturieren und Release-Zyklen
organisieren, finden Sie in Kapitel 6, Workflows über Workflows.
Commits kennen jeweils einen oder mehrere Vorgänger. Daher kann man den Commit-Graphen „gerichtet“, d.h. von neueren zu älteren Commits, durchlaufen, bis man an einem Wurzel-Commit ankommt.
Andersherum geht das nicht: Wenn ein Commit seinen Nachfolger kennen
würde, müsste diese Version irgendwo gespeichert werden. Dadurch würde
sich die SHA-1-Summe des Commits ändern, worauf der Nachfolger den
entsprechend neuen Commit referenzieren müsste, dadurch eine neue
SHA-1-Summe erhielte, so dass wiederum der Vorgänger geändert werden
müsste usw. Git kann also die Commits nur von einer benannten
Referenz aus (z.B. ein Branch oder HEAD) in Richtung
früherer Commits durchgehen.
Wenn daher die „Spitze“ eines Branches gelöscht wird, wird der oberste Commit nicht mehr referenziert (im Git-Jargon: unreachable). Dadurch wird der Vorgänger nicht mehr referenziert usw. – bis der nächste Commit auftaucht, der irgendwie referenziert wird (sei es von einem Branch oder dadurch, dass er einen Nachfolger hat, der wiederum von einem Branch referenziert wird).
Wenn Sie einen Branch löschen, werden die Commits auf diesem Branch also nicht gelöscht, sie gehen nur „verloren“. Git findet sie einfach nicht mehr.
In der Objektdatenbank sind sie allerdings noch eine Weile lang vorhanden.[32] Sie können also einen Branch ohne weiteres wiederherstellen, indem Sie den vorherigen (und vermeintlich gelöschten) Commit explizit als Referenz angeben:
$ git branch -D test Deleted branch test (was e32bf29). $ git branch test e32bf29
Eine weitere Möglichkeit, gelöschte Commits wiederzufinden, ist das Reflog (siehe dafür Abschnitt 3.7, „Reflog“).
SHA-1-Summen sind zwar eine sehr elegante Lösung, um Versionen dezentral zu beschreiben, aber semantikarm und für Menschen unhandlich. Im Gegensatz zu linearen Revisionsnummern sagen uns Commit-IDs allein nichts über die Reihenfolge der Versionen.
Während der Entwicklung von Softwareprojekten müssen verschiedene „wichtige“ Versionen so markiert werden, dass sie leicht in dem Repository zu finden sind. Die wichtigsten sind meist solche, die veröffentlicht werden, die sogenannten Releases. Auch Release Candidates werden häufig auf diese Weise markiert, also Versionen, die die Basis für die nächste Version bilden und im Zuge der Qualitätssicherung auf kritische Fehler untersucht werden, ohne dass neue Features hinzugefügt werden. Je nach Projekt und Entwicklungsmodell gibt es verschiedene Konventionen, um Releases zu bezeichnen, und Abläufe, wie sie vorbereitet und publiziert werden.
Im Open-Source-Bereich haben sich zwei Versionierungsschemata
durchgesetzt: die klassische Major/Minor/Micro-Versionierung
und neuerdings auch die datumsbasierte Versionierung. Bei der
Major/Minor/Micro-Versionierung, welche z.B. beim Linux-Kernel und
auch Git eingesetzt wird, ist eine Version durch drei (oft auch vier)
Zahlen gekennzeichnet: 2.6.39 oder 1.7.1. Bei der
datumsbasierten Versionierung hingegen ist die Bezeichnung aus dem
Zeitpunkt des Releases abgeleitet, z.B.: 2011.05 oder
2011-05-19. Das hat den großen Vorteil, dass das Alter einer
Version leicht ersichtlich ist.[33]
Git bietet Ihnen mit Tags („Etiketten“) die Möglichkeit,
beliebige Git-Objekte – meist Commits – zu markieren, um markante
Zustände in der Entwicklungsgeschichte hervorzuheben. Tags sind, wie
Branches auch, als Referenzen auf Objekte implementiert. Im Gegensatz
zu Branches jedoch sind Tags statisch, das heißt, sie werden nicht
verschoben, wenn neue Commits hinzukommen, und zeigen stets auf
dasselbe Objekt. Es gibt zwei Arten von Tags: Annotated (mit
Anmerkungen versehen) und Lightweight
(„leichtgewichtig“, d.h. ohne Anmerkungen). Annotated
Tags sind mit Metadaten – z.B. Autor, Beschreibung oder
GPG-Signatur – versehen. Lightweight Tags zeigen hingegen
„einfach nur“ auf ein bestimmtes Git-Objekt. Für beide Arten
von Tags legt Git unter .git/refs/tags/ bzw.
.git/packed-refs Referenzen an. Der Unterschied ist,
dass Git für jedes Annotated Tag ein spezielles Git-Objekt – und zwar
ein Tag-Objekt – in der Objektdatenbank anlegt, um die
Metadaten sowie die SHA-1-Summe des markierten Objekts zu speichern,
während ein Lightweight Tag direkt auf das markierte Objekt zeigt.
Abbildung 3.4, „Das Tag-Objekt“ zeigt den Inhalt eines Tag-Objekts;
vergleichen Sie auch die anderen Git-Objekte, Abbildung 2.4, „Git-Objekte“.
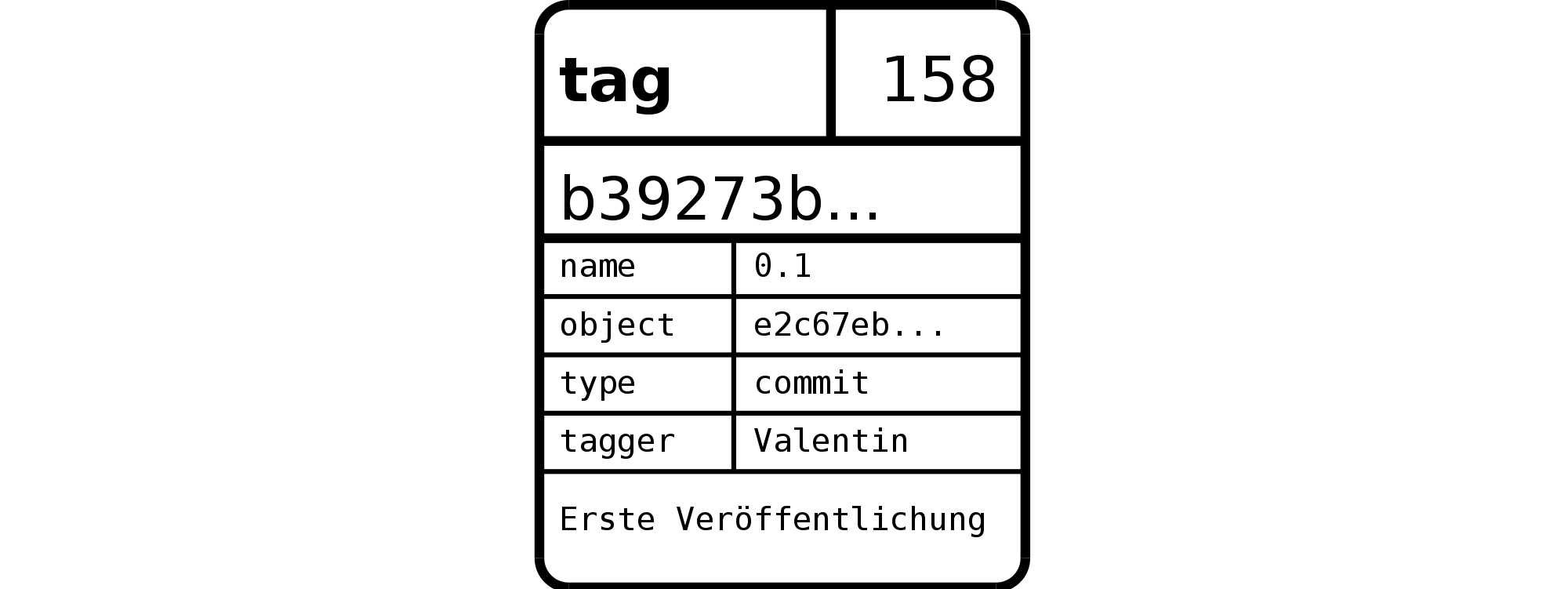
Das gezeigte Tag-Objekt hat sowohl eine Größe (158 Byte) als auch eine
SHA-1-Summe. Es enthält die Bezeichnung (0.1), den Objekt-Typ
und die SHA-1-Summe des referenzierten Objekts sowie den Namen und
E-Mail des Autors, der im Git-Jargon Tagger heißt. Außerdem
enthält das Tag eine Tag-Message, die zum Beispiel die Version beschreibt,
sowie optional eine GPG-Signatur. Im Git-Projekt etwa besteht eine Tag-Message
aus der aktuellen Versionsbezeichnung und der Signatur des
Maintainers.
Schauen wir im Folgenden zunächst, wie Sie Tags lokal verwalten. Wie Sie Tags zwischen Repositories austauschen, beschreibt Abschnitt 5.8, „Tags austauschen“.
Tags verwalten Sie mit dem Kommando git tag. Ohne Argumente
zeigt es alle vorhandenen Tags an. Je nach Projektgröße lohnt es sich,
die Ausgabe mit der Option -l und einem entsprechenden Muster
einzuschränken. Mit folgendem Befehl zeigen Sie alle Varianten der
Version 1.7.1 des Git-Projekts an, also sowohl die
Release-Candidates mit dem Zusatz -rc* sowie die
(vierstelligen) Maintenance-Releases:
$ git tag -l v1.7.1*
v1.7.1
v1.7.1-rc0
v1.7.1-rc1
v1.7.1-rc2
v1.7.1.1
v1.7.1.2
v1.7.1.3
v1.7.1.4
Den Inhalt eines Tags liefert Ihnen git show:
$ git show 0.1 | head
tag 0.1
Tagger: Valentin Haenel <valentin.haenel@gmx.de>
Date: Wed Mar 23 16:52:03 2011 +0100
Erste Veröffentlichung
commit e2c67ebb6d2db2aab831f477306baa44036af635
Author: Valentin Haenel <valentin.haenel@gmx.de>
Date: Sat Jan 8 20:30:58 2011 +0100
Gitk stellt Tags als gelbe, pfeilartige Kästchen dar, die sich deutlich von den grünen, rechteckigen Branches unterscheiden:
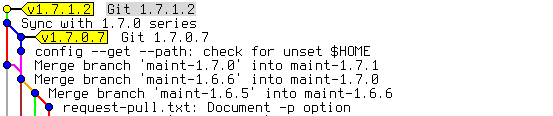
Um den HEAD mit einem Lightweight Tag zu versehen, übergeben
Sie den gewünschten Namen an das Kommando (in diesem Beispiel, um einen
wichtigen Commit zu markieren):
$ git tag api-aenderung $ git tag api-aenderung
Sie können aber auch die SHA-1-Summe eines Objekts oder eine valide
Revisionsbezeichnung (z.B. master oder HEAD~23)
angeben, um ein Objekt nachträglich zu markieren.
$ git tag pre-regression HEAD~23 $ git tag api-aenderung pre-regression
Tags sind einzigartig – sollten Sie versuchen, ein Tag erneut zu erzeugen, bricht Git mit einer Fehlermeldung ab:
$ git tag pre-regression
fatal: tag 'pre-regression' already exists
Annotated Tags erzeugen Sie mit der Option -a. Wie bei
git commit öffnet sich ein Editor, mit dem Sie die
Tag-Message verfassen. Oder Sie übergeben die Tag-Message mit der
Option -m – dann ist die Option -a redundant:
$ git tag -m "Zweite Veröffentlichung" 0.2
Um ein signiertes Tag zu überprüfen, verwenden Sie die Option
-v (verify):
$ git tag -v v1.7.1
object d599e0484f8ebac8cc50e9557a4c3d246826843d
type commit
tag v1.7.1
tagger Junio C Hamano <gitster@pobox.com> 1272072587 -0700
Git 1.7.1
gpg: Signature made Sat Apr 24 03:29:47 2010 CEST using DSA key ID F3119B9A
gpg: Good signature from "Junio C Hamano <junkio@cox.net>"
...
Das setzt natürlich voraus, dass Sie sowohl GnuPG installiert als auch den Schlüssel des Signierenden bereits importiert haben.
Um selbst Tags zu signieren, müssen Sie zunächst den dafür bevorzugten Key einstellen:
$ git config --global user.signingkey <GPG-Key-ID>
Nun können Sie signierte Tags mit der Option -s (sign)
erstellen:
$ git tag -s -m "Dritte Veröffentlichung" 3.0
Mit den Optionen -d und -f löschen Sie Tags bzw.
überschreiben sie:
$ git tag -d 0.2
Deleted tag '0.2' (was 4773c73)
Die Optionen sind mit Vorsicht zu genießen, besonders wenn Sie die
Tags nicht nur lokal verwenden, sondern auch veröffentlichen. Unter
bestimmten Umständen kann es dazu kommen, dass Tags unterschiedliche
Commits bezeichnen – Version 1.0 im Repository X zeigt auf
einen anderen Commit als Version 1.0 im Repository Y. Aber
sehen Sie hierzu auch Abschnitt 5.8, „Tags austauschen“.
Für die öffentliche Versionierung von Software sind allgemein Annotated Tags sinnvoller. Sie enthalten im Gegensatz zu Lightweight Tags Metainformationen, aus denen zu ersehen ist, wer wann ein Tag erstellt hat – der Ansprechpartner ist eindeutig. Auch erfahren Benutzer einer Software so, wer eine bestimmte Version abgesegnet hat. Zum Beispiel ist klar, dass Junio C. Hamano die Git-Version 1.7.1 getaggt hat – sie hat also quasi sein „Gütesiegel“. Die Aussage bestätigt natürlich auch die kryptographische Signatur. Lightweight Tags hingegen eignen sich vor allem, um lokal Markierungen anzubringen, zum Beispiel um bestimmte, für die aktuelle Aufgabe relevante Commits zu kennzeichnen. Achten Sie aber darauf, solche Tags nicht in ein öffentliches Repository hochzuladen (siehe Abschnitt 5.8, „Tags austauschen“), da diese sich sonst verbreiten könnten. Sofern Sie die Tags nur lokal verwenden, können Sie sie auch löschen, wenn sie ihren Dienst erfüllt haben (s.o.).
Mit Tags markieren Sie beliebige Git-Objekte, also nicht nur Commits, sondern auch Tree-, Blob- und sogar Tag-Objekte selbst! Das klassische Beispiel ist, den öffentlichen GPG-Schlüssel, der von dem Maintainer eines Projekts zum Signieren von Tags verwendet wird, in einem Blob zu hinterlegen.
So zeigt das Tag junio-gpg-pub im Git-Repository von Git auf den
Schlüssel von Junio C. Hamano:
$ git show junio-gpg-pub | head -5
tag junio-gpg-pub
Tagger: Junio C Hamano <junkio@cox.net>
Date: Tue Dec 13 16:33:29 2005 -0800
GPG key to sign git.git archive.
Weil dieses Blob-Objekt von keinem Tree referenziert wird, ist die Datei quasi getrennt vom eigentlichen Code, aber dennoch im Repository vorhanden. Außerdem ist ein Tag auf einen „einsamen“ Blob notwendig, damit dieser nicht als unreachable gilt und im Zuge der Repository-Wartung gelöscht wird.[34]
Um den Schlüssel zu verwenden, gehen Sie wie folgt vor:
$ git cat-file blob junio-gpg-pub | gpg --import
gpg: key F3119B9A: public key "Junio C Hamano <junkio@cox.net>" imported
gpg: Total number processed: 1
gpg: imported: 1
Sie können dann, wie oben beschrieben, alle Tags im Git-via-Git-Repository verifizieren.
Tags sind sehr nützlich, um beliebige Commits „besser“ zu
beschreiben. Das Kommando git describe gibt eine
Beschreibung, die aus dem aktuellsten Tag und dessen relativer
Position im Commit-Graphen besteht. Hier ein Beispiel aus dem
Git-Projekt: Wir beschreiben einen Commit mit dem SHA-1-Präfix 28ba96a,
der sich im Commit-Graphen sieben Commits nach der Version 1.7.1
befindet:
$ git describe --tags
v1.7.1-7-g28ba96a
Die Ausgabe von git describe ist wie folgt formatiert:
<tag>-<position>-g<SHA-1>
Das Tag ist v1.7.1; die Position besagt, dass sich sieben
neue Commits zwischen dem Tag und dem beschriebenen Commit
befinden.[35]
Das Kürzel g vor der ID besagt, dass die Beschreibung aus
einem Git-Repository abgeleitet ist, was in Umgebungen mit mehreren
Versionsverwaltungssystemen nützlich ist. Standardmäßig sucht
git describe nur nach Annotated Tags, mit der Option
--tags erweitern Sie die Suche auch auf Lightweight Tags.
Das Kommando ist sehr nützlich, weil es einen inhaltsbasierten
Bezeichner in etwas für Menschen Sinnvolles übersetzt:
v1.7.1-7-g28ba96a ist deutlich näher an v1.7.1 als
v1.7.1-213-g3183286. Dadurch können Sie die Ausgaben sinnvoll – wie im Git-Projekt auch – direkt in die Software einkompilieren:
$ git describe v1.7.5-rc2-8-g0e73bb4 $ make GIT_VERSION = 1.7.5.rc2.8.g0e73bb ... $ ./git --version git version 1.7.5.rc2.8.g0e73bb
Somit weiß ein Benutzer ungefähr, welche Version er hat, und kann nachvollziehen, aus welchem Commit die Version kompiliert wurde.
Ziel einer Versionskontrollsoftware ist es nicht nur, Änderungen
zwischen Commits zu untersuchen. Wichtig ist vor allem auch, ältere
Versionen einer Datei oder ganzer Verzeichnisbäume wiederherzustellen
oder Änderungen rückgängig zu machen. Dafür sind in Git insbesondere
die Kommandos checkout, reset und revert
zuständig.
Das Git-Kommando checkout kann nicht nur Branches wechseln,
sondern auch Dateien aus früheren Commits wiederherstellen. Die Syntax
lautet allgemein:
git checkout [-f] <referenz> -- <muster>
checkout löst die angegebene Referenz (und wenn diese fehlt,
HEAD) auf einen Commit auf und extrahiert alle Dateien, die
auf <muster> passen, in den Working Tree. Ist
<muster> ein Verzeichnis, bezieht sich das auf alle darin
enthaltenen Dateien und Unterverzeichnisse. Sofern Sie kein Muster
explizit angeben, werden alle Dateien ausgecheckt. Dabei werden
Änderungen an einer Datei nicht einfach überschrieben, es sei denn,
Sie geben die Option -f an (s.o.). Außerdem wird
HEAD auf den entsprechenden Commit (bzw. Branch) gesetzt.
Wenn Sie allerdings ein Muster angeben, dann überschreibt
checkout diese Datei(en) ohne Nachfrage. Um also alle
Änderungen an <datei> zu
verwerfen, geben Sie git checkout -- <datei> ein: Git
ersetzt dann <datei> durch die Version im aktuellen Branch.
Auf diese Weise können Sie auch den älteren Zustand einer Datei
rekonstruieren:
$ git checkout ce66692 -- <datei>
Das doppelte Minus trennt die Muster von den Optionen bzw. Argumenten. Es ist allerdings nicht notwendig: Gibt es keine Branches oder andere Referenzen mit dem Namen, versucht Git, eine solche Datei zu finden. Die Separierung macht also nur eindeutig, dass Sie die entsprechende(n) Datei(en) wiederherstellen möchten.
Um den Inhalt einer Datei aus einem bestimmten Commit anzuschauen, ohne sie auszuchecken, nutzen Sie das folgende Kommando:
$ git show ce66692:<datei>
Tipp
Mit --patch bzw. -p rufen Sie git checkout im interaktiven Modus
auf. Der Ablauf ist der gleiche wie bei git add -p (siehe
Abschnitt 2.1.2, „Commits schrittweise erstellen“), jedoch können Sie hier Hunks einer Datei schrittweise
zurücksetzen.
Wenn Sie einen Commit auschecken, der nicht durch einen Branch referenziert wird, befinden Sie sich im sogenannten Detached-HEAD-Modus:
$ git checkout 3329661
Note: checking out '3329661'.
You are in 'detached HEAD' state. You can look around, make
experimental changes and commit them, and you can discard any
commits you make in this state without impacting any branches
by performing another checkout.
If you want to create a new branch to retain commits you create,
you may do so (now or later) by using -b with the checkout command
again. Example:
git checkout -b new_branch_name
HEAD is now at 3329661... Add LICENSE file
Wie die Erklärung, die Sie durch setzen der Option
advice.detachedHead auf false ausblenden können,
schon warnt, werden Änderungen, die Sie nun tätigen, im Zweifel
verlorengehen: Da Ihr HEAD danach die einzige direkte
Referenz auf den Commit ist, werden weitere Commits nicht direkt von
einem Branch referenziert (sie sind unreachable, s.o.).
Im Detached-HEAD-Modus zu arbeiten bietet sich also vor allem dann an,
wenn Sie schnell etwas probieren wollen: Ist der Fehler eigentlich
schon im Commit 3329661 aufgetaucht? Gab es zum
Zeitpunkt von 3329661 eigentlich schon die Datei
README?
Tipp
Wenn Sie von dem ausgecheckten Commit aus mehr machen wollen als sich bloß umzuschauen und beispielsweise testen möchten, ob Ihre Software schon damals einen bestimmten Bug hatte, sollten Sie einen Branch erstellen:
$ git checkout -b <temp-branch>
Dann können Sie wie gewohnt Commits machen, ohne befürchten zu müssen, dass diese verlorengehen.
Wenn Sie alle Änderungen, die ein Commit einbringt, rückgängig machen
wollen, hilft das Kommando revert. Es löscht aber keinen
Commit, sondern erstellt einen neuen, dessen Änderungen genau dem
Gegenteil des anderen Commits entsprechen: Gelöschte Zeilen werden zu
hinzugefügten und umgekehrt.
Angenommen, Sie haben einen Commit, der eine Datei LICENSE
erstellt. Der Patch des entsprechenden Commits sieht so aus:
--- /dev/null +++ b/LICENSE @@ -0,0 +1 @@ +This software is released under the GNU GPL version 3 or newer.
Nun können Sie die Änderungen rückgängig machen:
$ git revert 3329661
Finished one revert.
[master a68ad2d] Revert "Add LICENSE file"
1 files changed, 0 insertions(+), 1 deletions(-)
delete mode 100644 LICENSE
Git erstellt einen neuen Commit auf dem aktuellen Branch – sofern Sie
nichts anderes angeben – mit der Beschreibung Revert "<Alte Commit-Nachricht>". Dieser Commit sieht so aus:
$ git show
commit a68ad2d41e9219383449d703521573477ee7da48
Author: Julius Plenz <feh@mali>
Date: Mon Mar 7 05:28:47 2011 +0100
Revert "Add LICENSE file"
This reverts commit 3329661775af3c52e6b2ad7e9e7e7d789ba62712.
diff --git a/LICENSE b/LICENSE
deleted file mode 100644
index 3fd9c20..0000000
--- a/LICENSE
+++ /dev/null
@@ -1 +0,0 @@
-This software is released under the GNU GPL version 3 or newer.
Beachten Sie also, dass in der Versionsgeschichte eines Projekts ab nun sowohl der Commit als auch der Revert auftauchen. Sie machen also nur die Änderungen rückgängig, löschen aber keine Informationen aus der Versionsgeschichte.
Sie sollten daher revert nur einsetzen, wenn Sie eine
Änderung, die bereits veröffentlicht wurde, rückgängig machen müssen.
Entwickeln Sie allerdings lokal in einem eigenen Branch, ist es
sinnvoller, diese Commits komplett zu löschen (siehe dafür den
folgenden Abschnitt über reset sowie das Thema Rebase, Abschnitt 4.1, „Commits verschieben – Rebase“).
Sofern Sie einen Revert durchführen wollen, allerdings nicht für sämtliche Änderungen des Commits, sondern nur für die einer Datei, können Sie sich zum Beispiel so behelfen:
$ git show -R 3329661 -- LICENSE | git apply --index $ git commit -m 'Revert change to LICENSE from 3329661'
Das Kommando git show gibt die Änderungen von Commit
3329661 aus, die sich auf die Datei LICENSE
beziehen. Die Option -R sorgt dafür, dass das
Unified-Diff-Format „andersherum“ angezeigt wird
(reverse). Die Ausgabe wird an git apply
weitergeleitet, um die Änderungen an der Datei und dem Index
vorzunehmen. Anschließend werden die Änderungen eingecheckt.
Eine weitere Möglichkeit, eine Änderung rückgängig zu machen, besteht darin, eine Datei aus einem vorherigen Commit auszuchecken, sie dem Index hinzuzufügen und neu einzuchecken:
$ git checkout 3329661 -- <datei> $ git add <datei> $ git commit -m 'Reverting <datei> to resemble 3329661'
Wenn Sie einen Commit gänzlich löschen, also nicht nur rückgängig
machen, dann verwenden Sie git reset. Das Reset-Kommando
setzt den HEAD (und damit auch den aktuellen Branch) sowie
wahlweise auch Index und Working Tree auf einen bestimmten Commit.
Die Syntax lautet git reset [<option>] [<commit>].
Die wichtigsten Reset-Typen sind die folgenden:
-
--soft -
Setzt nur den
HEADzurück; Index und Working Tree bleiben unberührt. -
--mixed -
Voreinstellung, wenn Sie keine Option
angeben. Setzt
HEADund Index auf den angegebenen Commit, die Dateien im Working Tree bleiben aber unberührt. -
--hard -
Synchronisiert
HEAD, Index und Working Tree und setzt sie auf den gleichen Commit. Dabei gehen möglicherweise Änderungen im Working Tree verloren!
Wenn Sie git reset ohne Optionen aufrufen, entspricht dies
einem git reset --mixed HEAD. Das Kommando haben wir schon
kennengelernt: Git setzt den aktuellen HEAD auf
HEAD (verändert ihn also nicht) und den Index auf
HEAD – dabei gehen die vorher hinzugefügten Änderungen
verloren.
Die Anwendungsmöglichkeiten dieses Kommandos sind vielfältig und werden in den verschiedenen Kommandosequenzen wieder auftauchen. Daher ist es wichtig, die Funktionalität zu verstehen, auch wenn es teilweise alternative Kommandos gibt, die den gleichen Effekt haben.
Angenommen, Sie haben auf master zwei Commits gemacht, die Sie
eigentlich auf einen neuen Branch verschieben wollen, um noch weiter
daran zu arbeiten. Die folgende Kommandosequenz erstellt einen neuen
Branch, der auf den HEAD zeigt, und setzt anschließend
HEAD und damit den aktuellen Branch master zwei
Commits zurück. Dann checken Sie den neuen Branch
<neues-feature> aus.
$ git branch <neues-feature> $ git reset --hard HEAD^^ $ git checkout <neues-feature>
Alternativ hat die folgende Sequenz den gleichen Effekt: Sie
erstellen einen Branch <neues-feature>, der auf den
aktuellen Commit zeigt. Dann löschen Sie master und erstellen
ihn neu, so dass er auf den zweiten Vorgänger des aktuellen Commits
zeigt.
$ git checkout -b <neues-feature> $ git branch -D master $ git branch master HEAD^^
Mit reset löschen Sie nicht beliebige Commits, sondern
verschieben immer nur Referenzen. Dadurch gehen die nicht mehr
referenzierten Commits verloren, werden also quasi gelöscht
(unreachable). Sie können also mit reset nur die
obersten Commits auf einem Branch löschen, nicht beliebige Commits
„irgendwo aus der Mitte“, da dies den Commit-Graphen
zerstören würde. (Für das etwas kompliziertere Löschen von Commits
„mittendrin“ siehe Rebase, Abschnitt 4.1, „Commits verschieben – Rebase“.)
Git speichert den ursprünglichen HEAD immer unter
ORIG_HEAD ab. Falls Sie also fälschlicherweise einen Reset durchgeführt haben, machen Sie diesen mit git reset --hard ORIG_HEAD
rückgängig (auch wenn der Commit vermeintlich gelöscht wurde). Das
betrifft allerdings nicht die verlorengegangenen Änderungen am
Working Tree (die Sie noch nicht eingecheckt haben) – diese werden
unwiderruflich gelöscht.
Das Resultat von oben (zwei Commits auf einen neuen Branch verschieben) erreichen Sie also alternativ auch so:
$ git reset --hard HEAD^^ $ git checkout -b <neues-feature> ORIG_HEAD
Eine häufige Anwendung von reset ist, testweise Änderungen zu
verwerfen. Sie wollen einen Patch probieren? Ein bisschen
Debugging-Output einbauen? Ein paar Konstanten ändern? Gefällt das
Ergebnis nicht, löscht ein git reset --hard alle
Änderungen am Working Tree.
Auch können Sie mit Hilfe von reset Ihre Versionsgeschichte
„schön machen“. Wenn Sie beispielsweise ein paar Commits auf
einem auf master aufbauenden Branch <feature>
haben, die aber nicht sinnvoll gegliedert (oder viel zu groß)
sind, können Sie einen Branch <reorder-feature>
erstellen und alle Änderungen in neue Commits verpacken:
$ git checkout -b <reorder-feature> <feature> $ git reset master $ git add -p $ git commit $ ...
Das Kommando git reset master setzt Index und HEAD
auf den Stand von master. Ihre Änderungen im Working Tree
bleiben aber erhalten, d.h. alle Änderungen, die den Branch
<feature> von master unterscheiden, sind nun
lediglich in den Dateien im Working Tree enthalten. Jetzt können Sie
die Änderungen schrittweise per git add -p hinzufügen
und in (mehrere) handliche Commits verpacken.[36]
Angenommen, Sie arbeiten an einer Änderung und wollen diese temporär einchecken (um später daran weiterzuarbeiten). Dann können Sie folgende Kommandos verwenden:
$ git commit -m 'feature (noch unfertig)' (später) $ git reset --soft HEAD^ (weiterarbeiten)
Das Kommando git reset --soft HEAD^ setzt den
HEAD einen Commit zurück, lässt allerdings den Index sowie
den Working Tree unberührt. Alle Änderungen aus Ihrem temporären
Commit sind also nach wie vor im Index und Working Tree, aber der
eigentliche Commit geht verloren. Sie können nun weitere Änderungen
machen und später einen neuen Commit erstellen. Eine ähnliche
Funktionalität stellt die Option --amend für git
commit sowie auch das Kommando git stash (dt.
„verstauen“) bereit, das in Abschnitt 4.5, „Veränderungen auslagern – git stash“ erklärt
wird.
Das Zusammenführen von Branches nennt man in Git mergen; der Commit, der zwei oder mehr Branches miteinander verbindet, heißt entsprechend Merge-Commit.
Git stellt das Subkommando merge bereit, mit dem Sie einen
Branch in einen anderen integrieren. Das bedeutet, dass alle
Änderungen, die Sie auf dem Branch getätigt haben, in den aktuellen
einfließen.
Beachten Sie, dass das Kommando den angegebenen Branch in den
aktuell ausgecheckten Branch (d.h. HEAD)
integriert. Das Kommando benötigt also nur ein Argument:
$ git merge <branch-name>
Wenn Sie wohlüberlegt mit Ihren Branches hantieren, dürfte es keine Probleme beim Mergen geben. Wenn doch, dann stellen wir in diesem Abschnitt auch Strategien vor, wie Sie Merge-Konflikte lösen.
Zunächst schauen wir uns einen Merge-Vorgang auf Objektebene an.
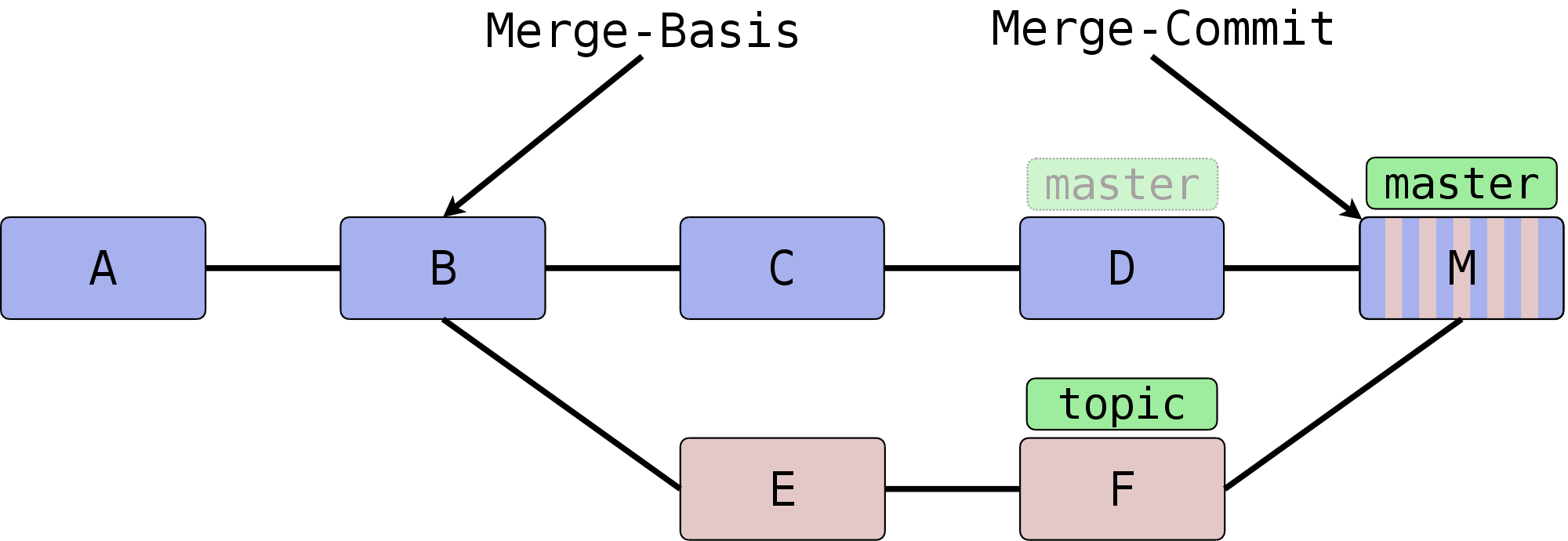
Die zwei Branches topic und master, die Sie mergen
wollen, referenzieren jeweils den aktuellsten Commit in einer Kette
von Commits (F und D), und diese beiden Commits wiederum einen Tree
(entspricht dem obersten Verzeichnis Ihres Projekts).
Zunächst berechnet Git eine sogenannte Merge-Basis, also einen Commit, den beide zu verschmelzenden Commits als gemeinsamen Vorfahren haben. In der Regel gibt es mehrere solcher Basen – im untenstehenden Diagramm A und B – , dann wird die neueste (die also die anderen Basen als Vorfahren hat) verwendet.[37] Anschaulich gesprochen, ist dies für einfache Fälle der Commit, an dem die Branches divergiert haben (also B).
Wenn Sie nun zwei Commits miteinander verschmelzen wollen (D und F zu M), dann müssen also die von den Commits referenzierten Trees verschmolzen werden.
Dafür geht Git so vor:[38] Wenn ein Tree-Eintrag (ein weiterer Tree oder ein Blob) in beiden Commits gleich ist, wird genau dieser Tree-Eintrag auch im Merge-Commit übernommen. Das passiert in zwei Fällen:
- Eine Datei wurde von keinem der beiden Commits geändert, oder ein Unterverzeichnis enthält keine geänderte Datei: Im ersten Fall ist die Blob-SHA-1-Summe dieser Datei in beiden Commits gleich, im zweiten Fall wird von beiden Commits das gleiche Tree-Objekt referenziert. Der referenzierte Blob bzw. Tree ist also derselbe wie der in der Merge-Basis referenzierte.
-
Eine Datei wurde auf beiden Seiten und äquivalent geändert (gleiche Blobs). Das passiert zum Beispiel, wenn aus dem einen Branch alle Änderungen an einer Datei per
git cherry-pick(siehe Abschnitt 3.5, „Einzelne Commits übernehmen: Cherry-Pick“) übernommen wurden. Der referenzierte Blob ist dann nicht derselbe wie in der Merge-Basis.
Wenn ein Tree-Eintrag in einem der Commits verschwindet, im anderen aber noch vorhanden ist und der gleiche ist wie in der Merge-Basis, dann wird er nicht übernommen. Das entspricht dem Löschen einer Datei oder eines Verzeichnisses, wenn an der Datei auf der anderen Seite keine Änderungen vorgenommen wurden. Analog, wenn ein Commit einen neuen Tree-Eintrag mitbringt, wird dieser in den Merge-Tree übernommen.
Was passiert nun, wenn eine Datei aus den Commits verschiedene Blobs aufweist, die Datei also zumindest auf der einen Seite verändert wurde? Im Falle, dass einer der Blobs der gleiche ist wie in der Merge-Basis, wurden nur auf einer Seite Änderungen an der Datei durchgeführt – Git kann diese Änderungen also einfach übernehmen.
Wenn sich aber beide Blobs von der Merge-Basis unterscheiden, könnte es möglicherweise zu Problemen kommen. Zunächst versucht Git, die Änderungen beider Seiten zu übernehmen.
Dafür wird in der Regel ein 3-Wege-Merge-Algorithmus verwendet. Im Gegensatz zum klassischen 2-Wege-Merge-Algorithmus, der eingesetzt wird, wenn Sie zwei unterschiedliche Versionen A und B einer Datei haben und diese zusammenführen wollen, bezieht dieser 3-Wege-Algorithmus eine dritte Version C der Datei ein, extrahiert aus obiger Merge-Basis. Der Algorithmus kann daher, weil ein gemeinsamer Vorgänger der Datei bekannt ist, in vielen Fällen besser (d.h. nicht nur anhand der Zeilennummer bzw. des Kontextes) entscheiden, wie Änderungen zusammengeführt werden. In der Praxis werden so viele trivial lösbare Merge-Konflikte schon automatisch ohne Zutun des Nutzers gelöst.
Es gibt allerdings Konflikte, die kein noch so guter Merge-Algorithmus zusammenführen kann. Das passiert zum Beispiel, wenn in Version A der Datei der Kontext direkt vor einer Änderung in Datei B geändert wurde, oder, schlimmer noch, Version A und B und C unterschiedliche Versionen einer Zeile aufweisen.
Einen solchen Fall nennt man Merge-Konflikt. Git führt alle Dateien so gut es geht zusammen und präsentiert dem Nutzer dann die in Konflikt stehenden Änderungen, damit dieser sie manuell verschmelzen (und damit den Konflikt lösen) kann (siehe dafür Abschnitt 3.4, „Merge-Konflikte lösen“).
Zwar ist es grundsätzlich möglich, mit einem speziell auf die jeweilige Programmiersprache ausgerichteten Algorithmus eine syntaktisch korrekte Auflösung zu erzeugen – allerdings kann ein Algorithmus nicht hinter die Semantik des Codes schauen, also die Bedeutung des Codes erfassen. Daher wäre eine so generierte Lösung in der Regel nicht sinnvoll.
Das Kommando git merge erzeugt nicht immer einen
Merge-Commit. Ein trivialer Fall, der aber häufig vorkommt, ist der
sogenannte Fast-Forward-Merge, also ein Vorspulen des Branches.
Ein Fast-Forward-Merge tritt dann auf, wenn ein Branch, z.B. topic, Kind eines zweiten Branches, master,
ist:
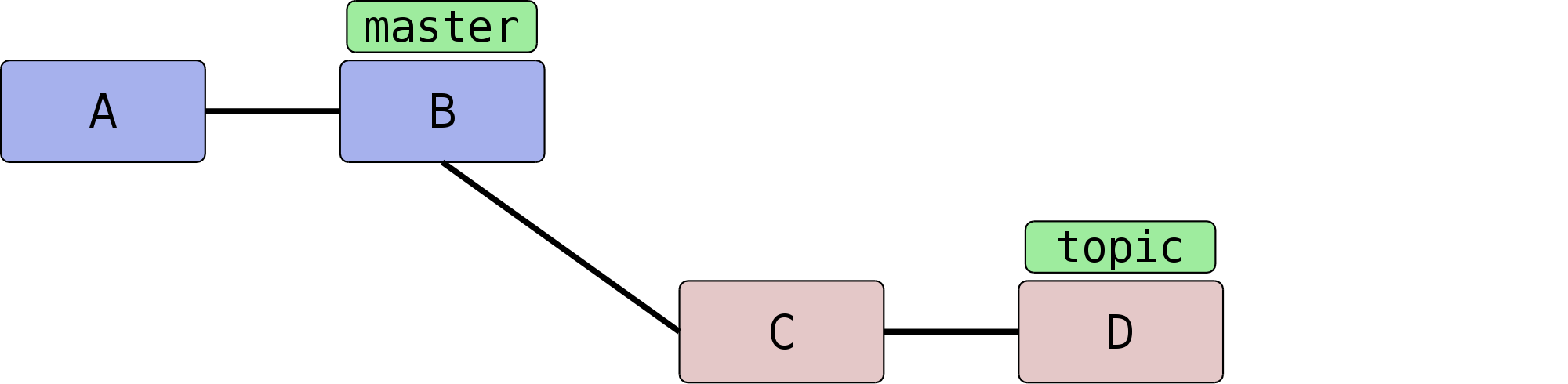
Ein einfaches git merge topic im Branch master führt
nun dazu, dass master einfach weitergerückt wird – es wird
kein Merge-Commit erzeugt.
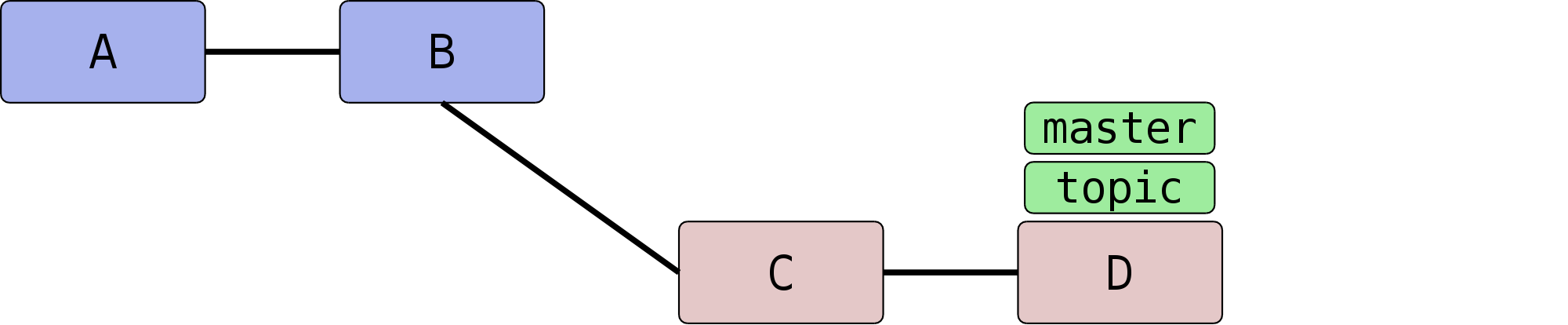
Ein solches Verhalten geht natürlich nur dann, wenn die beiden
Branches nicht divergiert haben, wenn also die Merge-Basis beider
Branches einer der beiden Branches selbst ist, in diesem Falle
master.
Dieses Verhalten ist häufig wünschenswert:
-
Sie wollen Upstream-Änderungen, also Änderungen aus einem
anderen Git-Repository, integrieren. Dafür verwenden Sie
typischerweise ein Kommando wie
git merge origin/master. Auch eingit pullwird einen Merge ausführen. Wie Sie Änderungen zwischen Git-Repositories austauschen, behandeln wir in Kapitel 5, Verteiltes Git. - Sie wollen einen experimentellen Branch einpflegen. Da Sie besonders einfach und schnell Branches in Git erstellen, empfiehlt es sich, für jedes Feature einen neuen Branch anzufangen. Wenn Sie nun etwas Experimentelles auf einem Branch ausprobiert haben und dies integrieren wollen, ohne dass man einen „Zeitpunkt der Integration“ erkennen kann, dann geschieht das per Fast-Forward.
Tipp
Mit den Optionen --ff-only und --no-ff können
Sie das Merge-Verhalten anpassen. Wenn Sie die erste Option verwenden
und die Branches können nicht per Fast-Forward zusammengeführt
werden, wird Git mit einer Fehlermeldung abbrechen. Die zweite
Option zwingt Git dazu, einen Merge-Commit zu erstellen, obwohl ein
Fast-Forward möglich gewesen wäre.
Es gibt verschiedene Meinungen, ob man Änderungen immer per Fast-Forward integrieren sollte oder lieber einen Merge-Commit erstellt, obwohl dies nicht unbedingt nötig ist. Die Resultate sind in beiden Fällen gleich: Die Änderungen aus einem Branch werden in einen anderen integriert.
Wenn Sie allerdings einen Merge-Commit erstellen, dann wird die Integration eines Features deutlich. Betrachten Sie die beiden folgenden Ausschnitte aus der Versionsgeschichte eines Projekts:

Im oberen Fall können Sie nicht ohne weiteres erkennen, welche
Commits ehemals im Branch sha1-caching entwickelt wurden,
also mit einem spezifischen Feature der Software zu tun haben.
In der unteren Version jedoch können Sie auf den ersten Blick erkennen, dass es genau vier Commits auf diesem Branch gab und er dann integriert wurde. Da parallel nichts entwickelt wurde, wäre der Merge-Commit prinzipiell unnötig, allerdings macht er die Integration des Features deutlich.
Tipp
Es bietet sich daher an, statt auf die Magie von git merge zu
vertrauen, zwei Aliase (siehe auch Abschnitt 1.3.1, „Git Aliase“) zu kreieren, die
einen Fast-Forward-Merge forcieren oder verbieten:
nfm = merge --no-ff # no-ff-merge ffm = merge --ff-only # ff-merge
Ein expliziter Merge-Commit ist auch hilfreich, weil Sie diesen mit einem einzigen Kommando rückgängig machen können. Dies ist beispielsweise dann sinnvoll, wenn Sie einen Branch integriert haben, der aber Fehler aufweist: Wenn der Code in Produktion läuft, ist es häufig wünschenswert, die gesamte Änderung vorerst wieder auszubauen, bis der Fehler korrigiert ist. Verwenden Sie dafür:
git revert -m 1 <merge-commit>
Git produziert dann einen neuen Commit, der alle Änderungen rückgängig
macht, die durch den Merge verursacht wurden. Die Option -m 1 gibt
hier an, welche „Seite“ des Merges als Mainline, also stabile
Entwicklungslinie, gelten soll: deren Änderungen bleiben bestehen.
Im obigen Beispiel würde -m 1 dazu führen, dass die Änderungen der
vier Commits aus dem Branch sha1-caching, also dem zweiten Strang des
Merges, rückgängig gemacht würden.
Git kennt fünf verschiedene Merge-Strategien, deren Verhalten
teilweise noch durch Strategie-Optionen weiter angepasst werden
kann. Die Strategie bestimmen Sie per -s, so dass ein
Merge-Aufruf wie folgt lautet:
git merge -s <strategie> <branch>
Manche dieser Strategien können nur zwei Branches zusammenführen, andere eine beliebige Anzahl.
-
resolve -
Die
resolve-Strategie kann zwei Branches mit Hilfe einer 3-Wege-Merge-Technik zusammenführen. Als Merge-Basis wird dafür die neueste (beste) aller möglichen Basen verwendet. Diese Strategie ist schnell und erzeugt generell gute Ergebnisse. -
recursive -
Dies ist die Standard-Strategie, die
Git einsetzt, um zwei Branches zu verschmelzen. Auch hier wird ein
3-Wege-Merge-Algorithmus eingesetzt. Allerdings geht diese
Strategie geschickter vor als
resolve: Existieren mehrere Merge-Basen, die allesamt „gleiche Berechtigung“ haben,[39] dann führt Git zunächst diese Basen zusammen, um das Ergebnis dann als Merge-Basis für den 3-Wege-Merge-Algorithmus zu verwenden. Neben der Tatsache, dass dadurch auch Merges mit Dateiumbenennungen besser verarbeitet werden können, hat ein Testlauf auf der Versionsgeschichte des Linux-Kernels gezeigt, dass durch diese Strategien weniger Merge-Konflikte auftreten als mit derresolve-Strategie. Die Strategie kann durch diverse Optionen angepasst werden (s.u.). -
octopus - Standard-Strategie, wenn drei oder mehr Branches zusammengeführt werden. Die Octopus-Strategie kann im Gegensatz zu den beiden vorher genannten Strategien nur dann Merges durchführen, wenn kein Fehler auftritt, also keine manuelle Konfliktauflösung notwendig ist. Die Strategie ist besonders dafür gedacht, viele Topic-Branches, von denen bekannt ist, dass sie sich mit der Mainline (Haupt-Entwicklungsstrang) vertragen, zu integrieren.
-
ours -
Kann beliebig viele Branches
verschmelzen, nutzt aber keinen Merge-Algorithmus. Stattdessen
werden immer die Blobs bzw. Trees des aktuellen Branch (d.h.
von dem Branch, von dem aus Sie
git mergeeingegeben haben) übernommen. Die Strategie wird vor allem dann verwendet, wenn Sie alte Entwicklungen mit dem aktuellen Stand der Dinge überschreiben wollen. -
subtree -
Funktioniert wie
recursive, allerdings vergleicht die Strategie die Trees nicht „auf gleicher Augenhöhe“, sondern bemüht sich, den Tree der einen Seite als Subtree der anderen Seite zu finden und erst dann zu verschmelzen. Diese Strategie ist zum Beispiel dann sinnvoll, wenn Sie das UnterverzeichnisDocumentation/Ihres Projekts in einem separaten Repository verwalten. Dann können Sie die Änderungen aus diesem Repository in das Haupt-Repository übernehmen, indem Sie übergit pull -s subtree <documentation-repo>diesubtree-Strategie bemühen, die die Inhalte von<documentation-repo>als Unterverzeichnis des Haupt-Repositorys erkennt und den Merge-Vorgang nur auf das entsprechende Unterverzeichnis anwendet. Dieses Thema wird eingehender in Abschnitt 5.11, „Unterprojekte verwalten“ behandelt.
Die Default-Strategie recursive kennt mehrere Optionen, die das
Verhalten besonders bezüglich der Konfliktlösung anpassen. Sie
bestimmen sie über die Option -X; die Syntax lautet also:
git merge -s recursive -X <option> <branch>
Sofern Sie nur zwei Branches mergen, müssen Sie die
recursive-Strategie nicht explizit per -s recursive
angeben.
Da die Strategie nur zwei Branches zusammenführen kann, ist es möglich, von unserer (engl. our) und deren (engl. theirs) Version zu sprechen: unsere Version ist dabei der ausgecheckte Branch beim Merge-Vorgang, während deren Version den Branch, den Sie integrieren wollen, referenziert.
-
ours -
Wenn ein Merge-Konflikt auftritt, der
normalerweise manuell gelöst werden müsste, wird stattdessen
unsere Version verwendet. Die Strategie-Option
unterscheidet sich allerdings von der Strategie
ours, denn dort werden jegliche Änderungen der Gegenseite(n) ignoriert. Dieours-Option hingegen übernimmt alle Änderungen unserer sowie der Gegenseite und gibt nur im Konfliktfall und nur an den Konfliktstellen unserer Seite Vorrang. -
theirs -
Wie
ours, nur dass genau gegenteilig vorgegangen wird: bei Konflikten wird deren Version bevorzugt. -
ignore-space-change,ignore-all-space,ignore-space-at-eol -
Da Whitespace in den meisten Sprachen keine syntaktische Rolle spielt, können Sie mit diesen Optionen Git anweisen, im Falle eines Merge-Konfliktes zu probieren, ob dieser automatisch lösbar ist, wenn Whitespace keine Rolle spielt. Ein häufiger Anwendungsfall ist, dass ein Editor oder eine IDE Quellcode automatisch umformatiert hat.
Die Option
ignore-space-at-eolignoriert Whitespace am Ende der Zeile, was insbesondere dann hilfreich ist, wenn beide Seiten verschiedene Zeilenende-Konventionen (LF/CRLF) verwenden. Geben Sieignore-space-changean, wird außerdem Whitespace als reiner Trenner betrachtet: Für den Vergleich einer Zeile ist also unwesentlich, wie viele Leerzeichen oder Tabs an einer Stelle stehen – eingerückte Zeilen bleiben eingerückt, und getrennte Wörter bleiben getrennt. Die Optionignore-all-spaceignoriert jeglichen Whitespace.Generell geht die Strategie so vor: Falls deren Version nur durch die angegebene Option abgedeckte Whitespace-Änderungen hineinbringt, werden diese ignoriert und unsere Version verwendet; bringt sie weitere Änderungen mit, und unsere Version hat nur Whitespace-Änderungen, so wird deren Version verwendet. Wenn aber auf beiden Seiten nicht nur Whitespace geändert wurde, so gibt es weiterhin einen Merge-Konflikt.
Generell empfiehlt es sich nach einem Merge, den Sie nur mit Hilfe einer dieser Optionen lösen konnten, die entsprechenden Dateien noch einmal zu normalisieren, also die Zeilenenden und Einrückungen einheitlich zu machen.
-
subtree=<tree> -
Ähnlich wie die
subtree-Strategie, allerdings wird hier ein expliziter Pfad angegeben. Analog zum obigen Beispiel würden Siegit pull -Xsubtree=Documentation <documentation-repo>
verwenden.
Wie bereits beschrieben, sind manche Konflikte nicht durch Algorithmen aufzulösen – hier ist manuelle Nachbesserung nötig. Gute Team-Koordination sowie schnelle Integrationszyklen können größere Merge-Konflikte minimieren. Aber gerade in der frühen Entwicklung, wenn möglicherweise die Interna einer Software geändert werden, statt neue Features hinzuzufügen, kann es zu Konflikten kommen.
Wenn Sie in einem größeren Team arbeiten, dann ist in der Regel der Entwickler, der maßgeblich am konfliktbehafteten Code gearbeitet hat, dafür verantwortlich, eine Lösung zu finden. Eine solche Konfliktlösung ist aber meist nicht schwierig, wenn der Entwickler einen guten Überblick über die Software allgemein und insbesondere über sein Stück Code und dessen Interaktion mit anderen Teilen hat.
Wir werden die Lösung eines Merge-Konflikts anhand eines einfachen
Beispiels in C durchgehen. Betrachten Sie die folgende Datei output.c:
int i;
for(i = 0; i < nr_of_lines(); i++)
output_line(i);
print_stats();
Das Stück Code geht alle Zeilen einer Ausgabe durch und gibt diese nacheinander aus. Zuletzt liefert es eine kleine Statistik.
Nun ändern zwei Entwickler etwas an diesem Code. Der erste,
Axel, schreibt eine Funktion, die die Zeilen umbricht, bevor sie
ausgegeben werden, und ersetzt im obigen Codestück
output_line durch seine verbesserte Version
output_wrapped_line:
int i;
int tw = 72;
for(i = 0; i < nr_of_lines(); i++)
output_wrapped_line(i, tw);
print_stats();
Die zweite Entwicklerin, Beatrice, modifiziert den Code, damit ihre
neu eingeführte Konfigurationseinstellung max_output_lines
honoriert wird, und nicht zu viele Zeilen ausgegeben werden:
int i;
for(i = 0; i < nr_of_lines(); i++) {
if(i > config_get("max_output_lines"))
break;
output_line(i);
}
print_stats();
Beatrice verwendet also die „veraltete“ Version
output_line, und Axel hat noch nicht das Konstrukt, das die
Konfigurationseinstellung überprüft.
Nun versucht Beatrice, ihre Änderungen auf Branch B in den
Branch master zu übernehmen, auf dem Axel seine Änderungen
schon integriert hat:
$ git checkout master $ git merge B Auto-merging output.c CONFLICT (content): Merge conflict in output.c Automatic merge failed; fix conflicts and then commit the result.
In der Datei output.c platziert Git nun sogenannte
Konflikt-Marker, unten halbfett hervorgehoben, die anzeigen, wo
sich Änderungen überschneiden. Es gibt zwei Seiten: Zum einen
HEAD, d.h. der Branch, in den Beatrice die Änderungen
übernehmen will – in diesem Falle master. Die andere Seite ist
der zu integrierende Branch – B. Die beiden Seiten werden
durch eine Reihe von Gleichheitszeichen voneinander getrennt:
int i; int tw = 72; <<<<<<< HEAD for(i = 0; i < nr_of_lines(); i++) output_wrapped_line(i, tw); ======= for(i = 0; i < nr_of_lines(); i++) { if(i > config_get("max_output_lines")) break; output_line(i); } >>>>>>> print_stats();
Zu beachten ist hier, dass nur die wirklich konfliktbehafteten
Änderungen von Beatrice beanstandet werden. Axels Definition von
tw weiter oben wird, obwohl bei Beatrice noch nicht
vorhanden, anstandslos übernommen.
Beatrice muss nun den Konflikt lösen. Das passiert, indem sie zunächst die Datei direkt editiert, den Code so abwandelt, wie er sein soll, und anschließend die Konflikt-Marker entfernt. Wenn Axel in seiner Commit-Nachricht entsprechend ausführlich dokumentiert hat[40] wie seine neue Funktion arbeitet, sollte das schnell gehen:
int i;
int tw = 72;
for(i = 0; i < nr_of_lines(); i++) {
if(i > config_get("max_output_lines"))
break;
output_wrapped_line(i, tw);
}
print_stats();
Anschließend muss Beatrice die Änderungen per git add
hinzufügen. Sofern keine Konflikt-Marker mehr in der Datei verbleiben,
ist dies für Git das Zeichen, dass ein Konflikt gelöst wurde.
Schließlich muss das Resultat noch eingecheckt werden:
$ git add output.c $ git commit
In der Commit-Nachricht sollte unbedingt stehen, wie dieser Konflikt gelöst wurde. Auch mögliche Seiteneffekte auf andere Teile des Programms sollten nicht unerwähnt bleiben.
Normalerweise sind Merge-Commits „leer“, d.h. in
git show erscheint keine Diff-Ausgabe (weil die Änderungen ja
von anderen Commits verursacht wurden). Im Falle eines Merge-Commits,
der einen Konflikt löst, ist dies aber anders:
$ git show commit 6e6c55810c884356402c078f30e45a997047058e Merge: f894659 256329f Author: Beatrice <beatrice@gitbu.ch> Date: Mon Feb 28 05:59:36 2011 +0100 Merge branch 'B' * B: honor max_output_lines config option Conflicts: output.c diff --cc output.c index a2bd8ed,f4c8bec..e39e39d --- a/output.c +++ b/output.c @@@ -1,7 -1,9 +1,10 @@@ int i; +int tw = 72; - for(i = 0; i < nr_of_lines(); i++) + for(i = 0; i < nr_of_lines(); i++) { + if(i > config_get("max_output_lines")) + break; - output_line(i); + output_wrapped_line(i, tw); + } print_stats();
Diese kombinierte Diff-Ausgabe unterscheidet sich vom üblichen
Unidiff-Format: Es gibt nicht nur eine Spalte mit den Markern für
hinzugefügt (+), entfernt (-) und Kontext bzw.
ungeändert (␣), sondern zwei. Git vergleicht also
das Resultat mit beiden Vorfahren. Die in der zweiten Spalte
geänderten Zeilen entsprechen genau denen des Commits von Axel; die
(halbfett markierten) Änderungen in der ersten Spalte sind der Commit
von Beatrice inklusive Konfliktlösung.
Der Standard-Weg, wie oben gesehen, ist der folgende:
- konfliktbehaftete Datei öffnen
- Konflikt lösen, Marker entfernen
-
Datei per
git addals „gelöst“ markieren - Schritt eins bis drei für alle Dateien wiederholen, in denen Konflikte auftraten
-
Konfliktlösungen per
git commiteinchecken
Wenn Sie ad hoc nicht wissen, wie der Konflikt zu lösen ist (und zum
Beispiel den ursprünglichen Entwickler damit beauftragen wollen, eine
konfliktfreie Version des Codes zu produzieren), können Sie per
git merge --abort den Merge-Vorgang abbrechen – also den
Zustand Ihres Working Trees wieder auf den Stand bringen, auf dem er
war, bevor Sie den Merge-Vorgang angestoßen haben. Dieses Kommando
bricht auch einen Merge ab, den Sie schon teilweise gelöst haben.
Achtung: Dabei gehen alle nicht eingecheckten Änderungen verloren.
Tipp
Um einen Überblick zu erhalten, welche Commits für den Merge-Konflikt relevante Änderungen an Ihrer Datei verursacht haben, können Sie das Kommando
git log --merge -p -- <datei>
verwenden. Git listet dann die Diffs von Commits auf, die seit der
Merge-Basis Änderungen an <datei> vorgenommen haben.
Wenn Sie sich in einem Merge-Konflikt befinden, liegt eine Datei mit
Konflikten in drei Stufen (Stages) vor: Stufe eins enthält die
Version der Datei in der Merge-Basis (also die gemeinsame
Ursprungsversion der Datei), Stufe zwei enthält die Version aus dem
HEAD (also die Version aus dem Branch, in den Sie
mergen). Stufe drei enthält schließlich die Datei in der Version des
zu integrierenden Branches (dieser hat die symbolische Referenz
MERGE_HEAD). Im Working Tree befindet sich die Kombination
dieser drei Stufen mit Konflikt-Markern. Sie können diese Versionen
aber jeweils mit git show :<n>:<datei> anzeigen:
$ git show :1:output.c $ git show :2:output.c $ git show :3:output.c
Mit einem speziell für 3-Wege-Merges entwickelten Programm behalten Sie allerdings wesentlich leichter den Überblick. Das Programm betrachtet die drei Stufen einer Datei, visualisiert sie entsprechend und bietet Ihnen Möglichkeiten an, Änderungen hin- und herzuschieben.
Bei nicht-trivialen Merge-Konflikten empfiehlt sich ein Merge-Tool, das die drei Stufen einer Datei entsprechend visualisiert und dadurch die Lösung des Konflikts erleichtert.
Gängige IDEs und Editoren wie z.B. Vim und Emacs bieten einen solchen Modus an. Außerdem gibt es externe Tools, wie zum Beispiel KDiff3[41] und Meld[42]. Letzteres visualisiert besonders gut, wie sich eine Datei zwischen den Commits verändert hat.

Sie starten ein solches Merge-Tool über git mergetool. Git wird alle
Dateien, die Konflikte enthalten, durchgehen und jeweils (wenn Sie
Eingabe drücken) in einem Merge-Tool anzeigen. Per Default ist das
Vimdiff[43].
Ein solches Programm wird in der Regel die drei Versionen einer Datei – unsere Seite, deren Seite sowie die soweit wie möglich zusammengeführte Datei inklusive Konflikt-Markern – in drei Spalten nebeneinander anzeigen, letztere sinnvollerweise in der Mitte. Wesentlich ist immer, dass Sie die Änderung (Konfliktlösung) in der mittleren Datei machen, also auf der Working-Copy. Die anderen Dateien sind temporär und werden wieder gelöscht, wenn das Merge-Tool beendet wurde.
Prinzipiell können Sie ein beliebiges anderes Tool verwenden. Das
mergetool-Script legt lediglich die drei Stufen der Datei mit
entsprechendem Dateinamen ab und startet das Diff-Tool auf diesen
drei Dateien. Beendet sich das Programm wieder, überprüft Git, ob noch
Konflikt-Marker in der Datei enthalten sind – wenn nicht, wird Git
annehmen, dass der Konflikt erfolgreich gelöst wurde, und die Datei
automatisch per git add dem Index hinzufügen. Wenn Sie also
alle Dateien abarbeiten, müssen Sie schließlich nur noch einen
Commit-Aufruf ausführen, um die Konfliktlösung zu besiegeln.
Welches Tool Git auf der Datei startet, regelt die Option
merge.tool. Die folgenden Kommandos sind bereits
vorkonfiguriert, d.h. Git weiß bereits, in welcher Reihenfolge das
Programm die Argumente erwartet und welche Zusatzoptionen angegeben
werden müssen:
araxis bc3 codecompare deltawalker diffmerge diffuse ecmerge emerge gvimdiff gvimdiff2 gvimdiff3 kdiff3 meld opendiff p4merge tkdiff tortoisemerge vimdiff vimdiff2 vimdiff3 xxdiff
Um Ihr eigenes Merge-Tool zu verwenden, müssen Sie
merge.tool auf einen geeigneten Namen setzen, zum Beispiel
mymerge, und anschließend zumindest die Option
mergetool.mymerge.cmd angeben. Den darin gespeicherten
Ausdruck wertet die Shell aus, und die Variablen
BASE, LOCAL, REMOTE sowie MERGED,
die die Datei mit den Konflikt-Markern enthält, sind auf die
entsprechend erzeugten temporären Dateien gesetzt. Sie können die
Eigenschaften Ihres Merge-Kommandos weiter konfigurieren, siehe
dafür die Man-Page git-config(1) im Abschnitt der
mergetool-Konfiguration.
Tipp
Wenn Sie sich zeitweise (nicht dauerhaft) für ein
anderes Merge-Programm entscheiden, geben Sie dieses über die
Option -t <tool> an. Um also Meld auszuprobieren,
geben Sie während eines Merge-Konflikts einfach git
mergetool -t meld ein – dafür muss Meld natürlich installiert
sein.
Git besitzt ein relativ unbekanntes (und schlecht dokumentiertes),
aber sehr hilfreiches Feature: Rerere, kurz für Reuse Recorded
Resolution („gespeicherte Konfliktlösung
wiederverwenden“). Sie müssen die Option
rerere.enabled auf true setzen, damit das Kommando
automatisch aufgerufen wird (beachten Sie das d am Ende von
enabled).
Die Idee hinter Rerere ist simpel, aber effektiv: Sobald ein Merge-Konflikt auftritt, nimmt Rerere automatisch ein Preimage auf, ein Abbild der Konfliktdatei inklusive Markern. Im Falle des obigen Beispiels sähe das so aus:
$ git merge B Auto-merging output.c CONFLICT (content): Merge conflict in output.c Recorded preimage for 'output.c' Automatic merge failed; fix conflicts and then commit the result.
Wird der Konflikt wie oben gelöst und die Lösung eingecheckt, speichert Rerere die Konfliktlösung ab:
$ vim output.c $ git add output.c $ git commit Recorded resolution for 'output.c'. [master 681acc2] Merge branch 'B'
Bisher hat Rerere noch nicht wirklich geholfen. Jetzt aber können wir den Merge-Commit komplett löschen (und sind wieder in der Ausgangssituation vor dem Merge). Dann führen wir den Merge noch einmal aus:
$ git reset --hard HEAD^ HEAD is now at f894659 wrap output at 72 chars $ git merge B Auto-merging output.c CONFLICT (content): Merge conflict in output.c Resolved 'output.c' using previous resolution. Automatic merge failed; fix conflicts and then commit the result.
Rerere bemerkt, dass der Konflikt bekannt ist und dass bereits eine Lösung gefunden wurde.[44] Also berechnet Rerere einen 3-Wege-Merge zwischen dem gespeicherten Preimage, der gespeicherten Lösung und der im Working Tree vorliegenden Version der Datei. So kann Rerere nicht nur dieselben Konflikte lösen, sondern auch ähnliche (wenn zwischenzeitlich weitere Zeilen außerhalb des Konfliktbereichs geändert wurden).
Das Ergebnis wird nicht direkt dem Index hinzugefügt. Die
Lösung wird lediglich in die Datei übernommen. Sie können dann per
git diff nachschauen, ob die Lösung sinnvoll aussieht,
eventuell Tests laufen lassen etc. Wenn alles gut aussieht, übernehmen
Sie wie üblich die automatische Lösung per git add.
Man könnte einwenden: Wer geht denn freiwillig das Risiko ein, einen bereits (möglicherweise aufwendig) gelösten Merge-Konflikt zu löschen, um ihn irgendwann wiederholen zu wollen?
Das Vorgehen ist allerdings wünschenswert: Zunächst ist es
nicht sinnvoll, einfach periodisch und aus Gewohnheit die
Mainline – also den Hauptentwicklungsstrang, z.B. master – in den Topic-Branch zu mergen (wir werden noch darauf
zurückkommen). Wenn Sie aber einen langlebigen Topic-Branch haben und
diesen gelegentlich darauf testen wollen, ob er sich mit der Mainline
verträgt, dann wollen Sie nicht jedes Mal die Konflikte von Hand
auflösen – einmal gelöste Konflikte wird Rerere dann automatisch
auflösen. Sie können so sukzessive Ihr Feature weiterentwickeln,
wohlwissend, dass es mit der Mainline in Konflikt steht. Zum
Zeitpunkt der Integration des Features sind die Konflikte aber alle
automatisch lösbar (weil Sie gelegentlich Konfliktlösungen mit Rerere
abgespeichert haben).
Außerdem wird Rerere auch automatisch in Konfliktfällen aufgerufen, die in einem Rebase-Prozess (siehe Abschnitt 4.1, „Commits verschieben – Rebase“) entstehen. Auch hier gilt wieder: Einmal gelöste Konflikte können automatisch wieder gelöst werden. Wenn Sie einen Branch einmal testweise per Merge in die Mainline integriert und einen Konflikt gelöst haben, wird diese Lösung automatisch angewendet, wenn Sie diesen Branch per Rebase auf die Mainline neu aufbauen.
Damit die Rerere-Funktionalität verwendet wird, müssen Sie, wie schon
erwähnt, die Option rerere.enabled auf true setzen.
Rerere wird dann automatisch aufgerufen, wenn ein Merge-Konflikt
auftritt (um das Preimage aufzunehmen, möglicherweise auch um den
Konflikt zu lösen) und wenn eine Konfliktlösung eingecheckt wird (um
die Lösung abzuspeichern).
Rerere legt Informationen wie Preimage und Lösung in
.git/rr-cache/ ab, eindeutig identifiziert durch eine
SHA-1-Summe. Das Subkommando git rerere müssen Sie fast nie
aufrufen, da es von merge und commit schon erledigt
wird. Sie können analog zu git gc auch git rerere gc
verwenden, um sehr alte Lösungen zu löschen.
Was passiert, wenn eine falsche Konfliktlösung eingecheckt wurde?
Dann sollten Sie die Konfliktlösung löschen, andernfalls wird Rerere
die Lösung, wenn Sie den konfliktbehafteten Merge wiederholen, erneut
anwenden. Dafür gibt es das Kommando git rerere forget
<datei> – direkt nachdem Rerere eine falsche Lösung eingespielt
hat, können Sie auf diese Weise die falsche Lösung löschen und den
Ursprungszustand der Datei wiederherstellen (d.h. mit
Konflikt-Markern). Wollen Sie nur Letzteres bewirken, hilft auch ein
git checkout -m <datei>.
Dezentrale Versionskontrollsysteme verwalten Merges generell wesentlich besser als zentrale. Das liegt vor allem daran, dass es bei dezentralen Systemen Usus ist, viele kleine Änderungen zunächst lokal einzuchecken. Dadurch entstehen keine „Monster-Commits“, die wesentlich mehr Konfliktpotential bieten. Diese feiner granulierte Entwicklungsgeschichte und der Umstand, dass Merges in der Regel wiederum Daten in der Versionsgeschichte sind (im Gegensatz zu einem simplen Kopieren der Codezeilen), führen dazu, dass dezentrale Systeme bei einem Merge nicht nur auf den bloßen Inhalt von Dateien schauen müssen.
Um Merge-Konflikte zu minimieren, ist Vorbeugung das beste Mittel.
Machen Sie kleine Commits! Fassen Sie Ihre Änderungen so zusammen,
dass der resultierende Commit als Einheit Sinn ergibt. Bauen Sie
Topic-Branches immer auf dem neuesten Release auf. Mergen Sie von
Topic-Branches in „Sammel-Branches“ oder direkt in den
master, nicht anders
herum.[45] Der
Einsatz von Rerere erlaubt es, dass bereits gelöste Konflikte nicht
ständig erneut auftreten.
Offensichtlich zählt zur Vorbeugung auch gute Kommunikation unter den Entwicklern: Wenn mehrere Entwickler an der gleichen Funktion unterschiedliche und sich gegenseitig beeinflussende Änderungen implementieren, wird das früher oder später sicher zu Konflikten führen.
Ein weiterer Faktor, der leider häufig zu unnötigen(!) Konflikten führt, sind autogenerierte Inhalte. Angenommen, Sie schreiben die Dokumentation einer Software in AsciiDoc[46] oder arbeiten an einem LaTeX-Projekt mit mehreren Mitstreitern: Fügen Sie keinesfalls die kompilierten Man-Pages oder das kompilierte DVI/PS/PDF im Repository ein! In den autogenerierten Formaten können kleine Änderungen am Plaintext (d.h. in der Ascii- bzw. LaTeX-Version) große (und unvorhersehbare) Änderungen an den kompilierten Formaten hervorrufen, die Git nicht adäquat auflösen wird. Sinnvoll ist es stattdessen, entsprechende Makefile-Targets oder Scripte bereitzustellen, um die Dateien zu generieren, und möglicherweise die kompilierte Version auf einem separaten Branch vorzuhalten.[47]
Es wird vorkommen, dass Sie nicht direkt einen ganzen Branch
integrieren wollen, sondern zunächst Teile, also einzelne Commits.
Dafür ist das Git-Kommando cherry-pick („die guten
Kirschen herauspicken“) zuständig.
Das Kommando erwartet einen oder mehrere Commits, die auf den aktuellen Branch kopiert werden sollen. Zum Beispiel:
$ git cherry-pick d0c915d $ git cherry-pick topic~5 topic~1 $ git cherry-pick topic~5..topic~1
Das mittlere Kommando kopiert zwei explizit angegebene Commits; das letzte Kommando hingegen kopiert alle zu der angegebenen Commit-Range gehörigen Commits.
Im Gegensatz zu einem Merge werden aber nur die Änderungen integriert,
nicht der Commit selbst. Dafür müsste er nämlich seinen Vorgänger
referenzieren, so dass dieser auch integriert werden müsste usw. – was einem Merge gleichkommt. Wenn Sie Commits mit cherry-pick
übernehmen, entstehen dabei also neue Commits mit neuer
Commit-ID. Git kann danach nicht ohne weiteres wissen, dass
diese Commits eigentlich die gleichen sind.
Daher kann es, wenn Sie zwei Branches mergen, zwischen denen Sie
Änderungen per Cherry-Pick ausgetauscht haben, zu Konflikten kommen.[48] Diese
sind meist trivial zu lösen, möglicherweise sind auch die
Strategie-Optionen ours bzw. theirs hilfreich
(siehe Abschnitt 3.3.4, „Optionen für die recursive-Strategie“).
Das Rebase-Kommando hingegen erkennt solche Commit-Doppelungen,[49]
und lässt die gedoppelten Commits aus. So können Sie einige Commits
„aus der Mitte“ übernehmen und dann den Branch, aus dem die
Commits stammten, neu aufbauen.
Das cherry-pick-Kommando versteht außerdem selbst diese
Merge-Strategie-Optionen: Wenn Sie einen Commit in den aktuellen Branch
kopieren wollen, und im Konfliktfall dem neuen Commit recht geben
wollen, verwenden Sie:
git cherry-pick -Xtheirs <commit>
Tipp
Über die Option -n bzw. --no-commit veranlassen
Sie Git, die Änderungen eines Commits zwar in den Index zu
übernehmen, aber noch keinen Commit daraus zu machen. So können Sie
mehrere kleine Commits erst im Index „aggregieren“ und
dann als einen Commit verpacken:
$ git cherry-pick -n 785aa39 512f3e9 4e4a063 Finished one cherry-pick. Finished one cherry-pick. Finished one cherry-pick. $ git commit -m "Diverse kleine Änderungen"
Wenn Sie einige Branches erstellt und wieder zusammengeführt haben, werden Sie gemerkt haben: Man verliert leicht den Überblick.
Die Anordnung der Commits und ihre Beziehungen untereinander
bezeichnet man als Topologie eines Repositorys. Im Folgenden
werden wir unter anderem das grafische Programm gitk
vorstellen, um diese Topologien zu untersuchen.
Rufen Sie bei kleinen Repositories zunächst ganz einfach gitk
--all auf, das das komplette Repository als Graphen darstellt. Ein
Klick auf die einzelnen Commits zeigt die Metainformationen sowie den
erzeugten Patch an.
Da die Auflistung mehrerer Commits kaum zu überblicken ist, untersuchen wir ein kleines Beispiel-Repository mit mehreren Branches, die untereinander gemergt wurden:
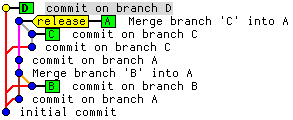
Wir erkennen vier Branches (A-D) sowie einen Tag release.
Diesen Baum können wir mit geeigneten Kommandozeilenoptionen auch per
log-Kommando auf der Konsole anzeigen lassen (Branch- und
Tag-Namen sind zur besseren Unterscheidung halbfett gedruckt):
$ git log --decorate --pretty=oneline --abbrev-commit --graph --all * c937566 (HEAD, D) commit on branch D | * b0b30ef (release, A) Merge branch 'C' into A | |\ | | * 807db47 (C) commit on branch C | | * 996a53b commit on branch C | |/ |/| | * 83f6bf3 commit on branch A | * 5b2c291 Merge branch 'B' into A | |\ | | * 2417cf7 (B) commit on branch B | |/ |/| | * 0bf1433 commit on branch A |/ * 4783886 initial commit
Tipp
Die Ausgabe des log-Kommandos ist äquivalent zu der Ansicht
in Gitk. Allerdings ist git log sehr viel schneller als
Gitk und kommt ohne ein weiteres Programmfenster aus.
Für eine schnelle Übersicht ist es also viel praktischer, ein
Alias einzurichten, das die vielen langen Optionen automatisch
hinzufügt. Die Autoren verwenden dafür das Alias tree, das
Sie wie folgt definieren können:
$ git config --global alias.tree 'log --decorate \ --pretty=oneline --abbrev-commit --graph'
Per git tree --all erhalten Sie eine ASCII-Version des
Graphen des Git-Repositorys. Im Folgenden nutzen wir dieses Alias, um
die Topologie darzustellen.
Nun verändern wir obiges Kommando: Statt der Option --all,
die alle Commits im Baum unterbringt, geben wir nun B an (den
Namen des Branch):
$ git tree B * 2417cf7 (B) commit on branch B * 4783886 initial commit
Wir erhalten alle Commits, die von B aus erreichbar sind. Ein Commit kennt jeweils nur seinen bzw. seine Vorgänger (mehrere dann, wenn Branches zusammengeführt werden). „Alle von B erreichbaren Commits“ bezeichnet also die Liste der Commits von B an weiter bis zu einem Commit, der keinen Vorgänger hat (genannt Root-Commit).
Statt einer kann das Kommando auch mehrere Referenzen entgegennehmen.
Um also die gleiche Ausgabe wie mit der Option --all zu
erhalten, müssen Sie die Referenzen A, B und D angeben. C kann
ausgelassen werden, weil der Commit auf dem Weg von A zum Root-Commit
bereits „eingesammelt“ wird.
Natürlich können Sie statt symbolischer Referenzen auch direkt eine SHA-1-Summe angeben:
$ git tree 5b2c291 * 5b2c291 Merge branch 'B' into A |\ | * 2417cf7 (B) commit on branch B * | 0bf1433 commit on branch A |/ * 4783886 initial commit
Wird einer Referenz ein Caret (^) vorangestellt, so negiert das
die Bedeutung.[50] Die Notation ^A bedeutet also: nicht die Commits,
die von A aus erreichbar sind. Allerdings schließt dieser Schalter
lediglich diese Commits aus, nicht jedoch die anderen ein. Obiges
log-Kommando mit dem Argument ^A wird also nichts ausgeben, da Git
nur weiß, welche Commits nicht angezeigt werden sollen. Wir fügen
also wieder --all hinzu, um alle Commits aufzulisten, abzüglich
derer, die von A erreichbar sind:
$ git tree --all ^A * c937566 (HEAD, D) commit on branch D
Eine alternative Notation ist mit --not verfügbar: Statt
^A kann man auch --not A schreiben.
Besonders hilfreich sind solche Kommandos, um den Unterschied zwischen zwei Branches zu untersuchen: Welche Commits sind in Branch D, die nicht in A sind? Die Antwort liefert das Kommando:
$ git tree D ^A * c937566 (HEAD, D) commit on branch D
Weil sich diese Frage häufig stellt, gibt es dafür eine andere,
intuitivere Notation: A..D ist gleichbedeutend mit D ^A:
$ git tree A..D * c937566 (HEAD, D) commit on branch D
Natürlich ist hier die Reihenfolge wichtig: „D ohne A“ ist eine andere Menge von Commits als „A ohne D“! (Vergleiche auch den vollständigen Graphen.)
Im unserem Beispiel gibt es einen Tag release. Um zu
überprüfen, welche Commits aus dem Branch D (der für
„Development“ stehen könnte) noch nicht im aktuellen Release
enthalten sind, genügt die Angabe release..D.
Tipp
Die Syntax A..B kann man sich als Idiom „von
A bis B“ merken. Diese „Differenz“
ist aber nicht symmetrisch, d.h. A..B sind in der Regel
nicht die gleichen Commits wie B..A.
Alternativ stellt Git die symmetrische Differenz A...B bereit. Sie entspricht dem Argument A B
--not $(git merge-base A B), bezieht also alle Commits ein,
die von A oder von B erreichbar sind – aber nicht von beiden.
Im Beispiel werden mit A immer alle Commits bezeichnet, die von A
erreichbar sind. Aber eigentlich ist ein Branch ja nur eine Referenz
auf einen Commit. Warum listet also log immer alle von
A erreichbaren Commits auf, während das Git-Kommando
show mit dem Argument A nur diesen einen Commit
anzeigt?
Der Unterschied liegt darin, was die Kommandos als Argument erwarten:
show erwartet ein Objekt, also eine Referenz auf
ein Objekt, das dann angezeigt wird.[51]
Viele andere Kommandos erwarten stattdessen einen (oder auch mehrere)
Commits, und diese Kommandos wandeln die Argumente in eine
Liste von Commits um (traversieren die Liste bis zum Root-Commit).
Gitk ist ein in Tcl implementiertes grafisches Programm, das in der Regel von Distributoren zusammen mit den eigentlichen Git-Kommandos paketiert wird – Sie können sich also darauf verlassen, es auf fast jedem System vorzufinden.
Es repräsentiert einzelne Commits oder das ganze Repository in einer dreiteiligen Ansicht: Oben die Baumstruktur mit zwei weiteren Spalten für Autor und Datum, unten eine Auflistung der Änderungen im Unified-Diff-Format sowie eine Liste von Dateien, um die angezeigten Änderungen einzuschränken.
Die Graph-Ansicht ist intuitiv: Verschiedene Farben helfen, die
verschiedenen Versionsstränge zu unterscheiden. Commits sind jeweils
blaue Punkte, mit zwei Ausnahmen: Der HEAD ist gelb markiert,
und ein Commit, der nicht Root-Commit ist, dessen Vorgänger aber nicht
angezeigt ist, wird weiß dargestellt.
Branches mit einer Pfeilspitze deuten an, dass auf dem Branch weitere Commits getätigt wurden. Aufgrund der zeitlichen Distanz der Commits blendet Gitk aber den Branch aus. Ein Klick auf die Pfeilspitze bringt Sie zu der Weiterführung des Branches.
Branches erscheinen als grüne Labels, der aktuell ausgecheckte Branch zusätzlich fett. Tags sind als gelbe Pfeile dargestellt.
Mit einem Rechtsklick auf einen Branch können Sie diesen löschen oder auschecken. Auf Commits öffnet ein Rechtsklick ein Menü, in dem Sie Aktionen mit dem markierten Commit ausführen können. Die einzige, die mit Gitk möglicherweise leichter zu bewerkstelligen ist als über die Kommandozeile, ist Cherry-Picking, also das Übernehmen einzelner Commits in einen anderen Branch (siehe auch Abschnitt 3.5, „Einzelne Commits übernehmen: Cherry-Pick“).
Gitk akzeptiert im wesentlichen die gleichen Optionen wie git
log. Einige Beispiele:
$ gitk --since=yesterday -- doc/ $ gitk e13404a..48effd3 $ gitk --all -n 100
Das erste Kommando zeigt alle Commits seit gestern an, die Änderungen
an einer Datei unterhalb des Verzeichnisses doc/ vorgenommen
haben. Das zweite Kommando limitiert die Commits auf eine spezielle
Range, während das dritte Kommando die 100 neuesten Commits aller
Branches anzeigt.
Tipp
Erfahrungsgemäß sind Anfänger oft verwirrt, weil gitk
standardmäßig nur den aktuellen Branch anzeigt. Das liegt vermutlich
daran, dass gitk oft aufgerufen wird, um sich einen
Überblick aller Branches zu verschaffen. Daher bietet sich
folgendes Shell-Alias an: alias gik='gitk --all'
Viele Nutzer lassen gitk während der Arbeit offen. Dann ist
es wichtig, von Zeit zu Zeit die Anzeige zu aktualisieren, damit auch
aktuellere Commits erscheinen. Mit F5 (Update) laden
Sie alle neuen Commits und erneuern die Darstellung der Referenzen.
Manchmal, wenn Sie z.B. einen Branch löschen, reicht dies jedoch
nicht aus. Zwar wird der Branch nicht mehr angezeigt, aber evtl. sind
unerreichbare Commits weiterhin quasi als Artefakte in der GUI
vorhanden. Mit der Tastenkombination Strg+F5
(Reload) wird das Repository vollständig neu eingelesen, was
das Problem beseitigt.
Alternativ zu gitk können Sie auf UNIX-Systemen das GTK-basierte
gitg oder Qt-basierte qgit verwenden; auf einem OS-X-System können
Sie beispielsweise GitX verwenden; für Windows bieten sich die
GitExtensions an. Einige IDEs verfügen mittlerweile auch über
entsprechende Visualisierungen (z.B. das Eclipse-Plugin EGit).
Weiterhin können Sie vollwertige Git-Clients wie Atlassian SourceTree
(OS X, Windows; kostenlos), Tower (OS X; kommerziell) sowie SmartGit
(Linux, OS X und Windows; kostenlos für nichtkommerzielle Nutzung)
verwenden.
Das Reference Log (Reflog) sind Log-Dateien, die Git für
jeden Branch sowie HEAD anlegt. Darin wird gespeichert, wann
eine Referenz von wo nach wo verschoben wurde. Das passiert vor allem
bei den Kommandos checkout, reset, merge
und rebase.
Diese Log-Dateien liegen unter .git/logs/ und tragen den
Namen der jeweiligen Referenz. Das Reflog für den
master-Branch finden Sie also unter
.git/logs/refs/heads/master. Außerdem gibt es das Kommando
git reflog show <referenz>, um das Reflog aufzulisten:
$ git reflog show master
48effd3 master@{0}: HEAD^: updating HEAD
ef51665 master@{1}: rebase -i (finish): refs/heads/master onto 69b9e27
231d0a3 master@{2}: merge @{u}: Fast-forward
...
Das Reflog-Kommando wird selten direkt benutzt und ist nur ein Alias
für git log -g --oneline. Die Option -g bewirkt
nämlich, dass das Kommando nicht die Vorgänger im Commit-Graphen
anzeigt, sondern die Commits in der Reihenfolge des Reflogs
abarbeitet.
Das können Sie ganz leicht ausprobieren: Erstellen Sie einen
Test-Commit und löschen Sie ihn danach wieder mit git reset
--hard HEAD^. Das Kommando git log -g wird nun zuerst
den HEAD anzeigen, dann den gelöschten Commit und dann wieder
den HEAD.
Das Reflog referenziert also auch Commits, die sonst nicht mehr
referenziert sind, also „verloren“ sind (siehe
Abschnitt 3.1.2, „Branches verwalten“). So hilft das Reflog Ihnen
möglicherweise, wenn Sie einen Branch gelöscht haben, von dem sich im
Nachhinein herausstellt, dass Sie ihn doch gebraucht hätten. Zwar
löscht ein git branch -D auch das Reflog des Branches.
Allerdings haben Sie den Branch ja auschecken müssen, um Commits
darauf zu machen: Suchen Sie also mit git log -g HEAD nach
dem letzten Zeitpunkt, zu dem Sie den gesuchten Branch ausgecheckt
haben. Dann erstellen Sie einen Branch, der auf diese (scheinbar
verlorene) Commit-ID zeigt, und Ihre verlorenen Commits sollten wieder
da sein.[52]
Kommandos, die eine oder mehrere Referenzen erwarten, können
allerdings auch implizit das Reflog verwenden. Neben der Syntax, die
sich schon bei der Ausgabe von git log -g findet (z.B. HEAD@{1} für die vorherige Position des HEAD),
versteht Git auch <ref>@{<wann>}. Git interpretiert den
Zeitpunkt <wann> als absolutes oder relatives Datum und
konsultiert dann das Reflog der entsprechenden Referenz, um
herauszufinden, was der zeitlich nächste Log-Eintrag ist. Dieser wird
dann referenziert.
Zwei Beispiele:
$ git log 'master@{two weeks ago}..' $ git show '@{1st of April, 2011}'
Das erste Kommando listet alle Commits zwischen HEAD und dem
Commit auf, auf den der master-Branch vor zwei Wochen gezeigt
hat (beachten Sie das Suffix .., was eine Commit-Range bis
HEAD bedeutet). Das muss nicht nötigerweise auch ein Commit
sein, der zwei Wochen alt ist: Wenn Sie vor zwei Wochen testweise per
git reset --hard <initial-commit> den Branch auf den
allerersten Commit des Repositorys verschoben haben, dann wird genau
dieser Commit referenziert.[53]
Die zweite Zeile zeigt den Commit an, auf den der (wegen fehlender
expliziter Referenz vor dem @) aktuell ausgecheckte Branch am
1. April 2011 gezeigt hat. In beiden Kommandos muss das Argument mit
Reflog-Anhang sinnvoll in Anführungszeichen eingefasst werden, damit
Git das Argument komplett erhält.
Beachten Sie, dass das Reflog nur lokal vorliegt und somit
nicht zum Repository gehört. Wenn Sie einem anderen Entwickler eine
Commit-ID oder einen Tag-Namen schicken, dann referenziert dies den
gleichen Commit – ein master@{yesterday} kann aber je nach
Entwickler verschiedene Commits referenzieren.
Tipp
Wenn Sie keinen Branch und keinen Zeitpunkt angeben, nimmt Git HEAD an.
Somit können Sie in Kommandos @ als Kurzform für HEAD verwenden.
Weiterhin verstehen viele Kommandos das Argument - als @{-1}, also
„letzte Position des HEAD“:
$ git checkout feature # vorher auf "master" $ git commit ... # Änderungen, Commits machen $ git checkout - # zurück auf "master" $ git merge - # Merge von "feature"
[29] Das hindert Sie natürlich nicht, einen Branch auf einen Commit „irgendwo in der Mitte“ zu setzen, was auch sinnvoll sein kann.
[30] Aufgrund der
Tatsache, dass bei einem Merge die Reihenfolge der direkten Vorfahren
gespeichert wird, ist es wichtig, immer vom kleineren in den
größeren Branch zu mergen, also z.B. topic nach master. Wenn Sie
dann mit master^^ Commits im Master-Branch untersuchen wollen,
landen Sie nicht auf einmal auf Commits aus dem Topic-Branch (siehe
auch Abschnitt 3.3, „Branches zusammenführen: Merges“).
[31] Wie Git eine
Referenz auf Gültigkeit überprüft, können Sie bei Bedarf in der Man-Page
git-check-ref-format(1) nachlesen.
[32] Wie lange sie dort verweilen, bestimmen Sie mit entsprechenden Einstellungen für die Garbage Collection (Wartungsmechanismen), siehe Abschnitt B.1, „Aufräumen“.
[33] Eine detaillierte Übersicht der Vor- und Nachteile der beiden Schemata sowie eine Beschreibung des Release-Prozesses usw. finden Sie im Kapitel 6 des Buches Open Source Projektmanagement von Michael Prokop (Open Source Press, München, 2010).
[34] Um einen solchen getaggten Blob in ein
Repository aufzunehmen, bedienen Sie sich des folgenden
Kommandos: git tag -am "<beschreibung>" <tag-name>
$(git hash-object -w <datei>).
[35] Es handelt sich hierbei um die
Commits, die mit git log v1.7.1..28ba96a erfasst werden.
[36] Um zu überprüfen, dass die Änderungen in
Ihrem neuen Branch denen des alten entsprechen, verwenden Sie
git diff <reorder-feature> <feature> – wenn das
Kommando keine Ausgabe erzeugt, dann enthalten die Branches
identische Änderungen.
[37] Es ist nicht zwingend notwendig, dass eine Merge-Basis existiert; wenn Sie zum Beispiel mehrere Root-Commits in einem Repository verwalten (siehe auch Abschnitt 4.7, „Mehrere Root-Commits“) und dann die darauf aufgebauten Branches mergen, gibt es – sofern vorher noch kein Merge stattfand – keine gemeinsame Basis. In diesem Fall erzeugt eine Datei, die auf beiden Seiten in verschiedenen Versionen vorliegt, einen Konflikt.
[38] Die
nachfolgende Beschreibung erläutert die Vorgehensweise der
resolve-Strategie. Sie unterscheidet sich nur wenig von der
Standard-Strategie recursive, siehe auch die
Detailbeschreibung dieser Strategie in Abschnitt 3.3.3, „Merge-Strategien“.
[39] Die
recursive-Strategie geht also nur dann wesentlich
intelligenter als resolve vor, wenn die
Topologie der Commits (d.h. die Anordnung, wo
abgezweigt und zusammengeführt wurde) wesentlich komplizierter
ist als ein bloßes Abzweigen und anschließendes Zusammenführen.
[40] Die für den Merge relevanten Commits,
die etwas an der Datei output.c geändert haben, kann
Beatrice mit git log --merge -p -- output.c auflisten.
[43] In Vimdiff können Sie mit
Strg+W und anschließender Bewegung mit den Pfeiltasten oder
h, j, k, l das Fenster in die
entsprechende Richtung wechseln. Mit dp bzw. do
schieben Sie Änderungen auf die andere Seite oder übernehmen sie von
dort (diff put – diff obtain).
[44] Die Meldung Automatic
merge failed bedeutet lediglich, dass ein Konflikt auftrat, der
nicht durch einen 3-Wege-Merge gelöst werden konnte. Da
Rerere keine sinnvolle Lösung garantieren kann, wird die Lösung nur
„bereitgestellt“, nicht aber als ultimative Lösung des
Konflikts angesehen.
[45] Weitere nützliche Tipps finden Sie in Kapitel 6, Workflows.
[46] AsciiDoc ist eine simple,
wiki-ähnliche Markup-Sprache:
http://www.methods.co.nz/asciidoc/. Die Git-Dokumentation liegt in
diesem Format vor und wird in HTML-Seiten und Man-Pages konvertiert,
und auch dieses Buch wurde in AsciiDoc geschrieben!
[47] Das Repository des Git-Projekts
selbst verwaltet zum Beispiel die autogenerierte HTML-Dokumentation
in einem Branch html, der von den Entwicklungsbranches
vollständig abgekoppelt ist. So kann es bei Merges zwischen den
Code-Branches nicht zu Konflikten wegen unterschiedlich kompilierter
HTML-Dokumentation kommen. Wie Sie solche „entkoppelten“
Branches erstellen, beschreiben wir in Abschnitt 4.7, „Mehrere Root-Commits“.
[48] Das liegt daran, dass das Merge-Kommando nicht jeden Commit einzeln untersucht. Stattdessen werden drei Trees verglichen, in denen unter anderen diese Änderungen enthalten sind, siehe Abschnitt 3.3.1, „Zwei Branches verschmelzen“.
[49] Das liegt daran, dass Rebase intern
mit cherry-pick arbeitet, was wiederum erkennt, wenn die
Änderungen, die durch den Commit eingebracht würden, schon vorhanden
sind. Eine ähnliche Funktionalität bietet auch git cherry
bzw. git patch-id, das fast gleiche Patches erkennen kann.
[50] Möglicherweise besitzt das Zeichen ^ in
Ihrer Shell eine besondere Bedeutung (dies ist z.B. in der Z-Shell
oder rc-Shell der Fall). Dann müssen Sie das Zeichen maskieren, also
das Argument in Anführungszeichen einfassen oder einen Backslash
voranstellen. In der Z-Shell existiert außerdem das Kommando noglob,
das Sie git voranstellen, um die Sonderbedeutung von ^
aufzuheben.
[51] Dies ist nicht nötigerweise ein Commit – das können auch Tags oder Blobs sein.
[52] Ob die Commits nicht schon aufgrund
ihres Alters herausgefallen sind, hängt natürlich davon ab, wie oft
Sie eine Garbage-Collection per git gc durchführen.
Siehe auch Abschnitt B.1, „Aufräumen“.
[53] Wollen
Sie alle Commits der letzten zwei Wochen auflisten, verwenden Sie
stattdessen git log --since='two weeks ago'.
